|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
DERS ÖZETİ, KRİBS
Veri tabanı. Ders notları: kısaca, en önemli
Rehber / Ders notları, kopya kağıtları içindekiler
Ders numarası 1. Giriş 1. Veritabanı yönetim sistemleri Veritabanı yönetim sistemleri (DBMS) sağlayan özel yazılım ürünleridir: 1) keyfi olarak büyük (ancak sonsuz değil) miktarda veriyi kalıcı olarak depolamak; 2) sözde sorguları kullanarak bu saklanan verileri bir şekilde çıkarın ve değiştirin; 3) yeni veri tabanları oluşturun, yani mantıksal veri yapılarını tanımlayın ve yapılarını ayarlayın, yani bir programlama arayüzü sağlayın; 4) aynı anda birkaç kullanıcı tarafından saklanan verilere erişin (yani işlem yönetim mekanizmasına erişim sağlayın). Buna göre, Veri tabanı yönetim sistemlerinin kontrolü altındaki veri kümeleridir. Artık veritabanı yönetim sistemleri piyasadaki en karmaşık yazılım ürünleridir ve temelini oluşturmaktadır. Gelecekte, geleneksel veritabanı yönetim sistemleri ile nesne yönelimli programlama (OOP) ve İnternet teknolojilerinin bir kombinasyonu üzerinde geliştirmeler yapılması planlanmaktadır. Başlangıçta, DBMS'ye dayanıyordu hiyerarşik и ağ veri modelleri, yani yalnızca ağaç ve grafik yapılarıyla çalışmasına izin verilir. 1970 yılındaki geliştirme sürecinde, Codd tarafından önerilen veritabanı yönetim sistemleri ortaya çıktı. ilişkisel veri modeli. 2. İlişkisel veritabanları "İlişkisel" terimi, İngilizce "ilişki" - "ilişki" kelimesinden gelir. En genel matematiksel anlamda (klasik küme cebir dersinden hatırlayabileceğiniz gibi) отношение - bu bir set R = {(x1,..., Xn) | X1 ∈ bir1,...,Xn ∈ An}, burada bir1,...,An Kartezyen çarpımı oluşturan kümelerdir. Böylece, oran R kümelerin Kartezyen çarpımının bir alt kümesidir: A1 x... x An : R ⊆ Bir 1 x... x An. Örneğin, sıralı A sayı çiftleri kümesindeki "büyüktür" ve "küçüktür" katı düzeninin ikili ilişkilerini düşünün. 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x bir2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ Bir1 x bir2. Bu ilişkiler tablolar şeklinde sunulabilir. Oran "daha büyük">:
R oranı "daha az"<:
Böylece ilişkisel veritabanlarında çok çeşitli verilerin ilişkiler şeklinde düzenlendiğini ve tablolar şeklinde sunulabildiğini görüyoruz. Bu iki ilişkinin R olduğuna dikkat edilmelidir.> ve R< birbirine eşdeğer değildir, yani bu ilişkilere karşılık gelen tablolar birbirine eşit değildir. Dolayısıyla, ilişkisel veritabanlarında veri temsil biçimleri farklı olabilir. Bu farklı temsil olanağı bizim durumumuzda nasıl kendini gösterir? ilişkiler R> ve R< - bunlar kümelerdir ve bir küme sırasız bir yapıdır; bu, bu ilişkilere karşılık gelen tablolarda satırların birbiriyle değiştirilebileceği anlamına gelir. Ancak aynı zamanda, bu kümelerin öğeleri sıralı kümelerdir, bizim durumumuzda - sıralı 3, 4, 5 sayı çiftleri, bu, sütunların değiştirilemeyeceği anlamına gelir. Böylece, bir ilişkinin (matematiksel anlamda) keyfi bir sıra düzenine ve sabit sayıda sütuna sahip bir tablo biçiminde temsilinin, ilişkilerin kabul edilebilir, doğru bir temsil şekli olduğunu gösterdik. Ama eğer R bağıntılarını düşünürsek> ve R< içlerinde gömülü olan bilgiler açısından, eşdeğer oldukları açıktır. Bu nedenle, ilişkisel veritabanlarında "ilişki" kavramı, genel matematikteki bir ilişkiden biraz farklı bir anlama sahiptir. Yani, tablo şeklinde bir sunum biçiminde sütunlara göre sıralama ile ilgili değildir. Bunun yerine, sözde "satır - sütun başlığı" ilişki şemaları tanıtılır, yani her sütuna bir başlık verilir, bundan sonra serbestçe değiştirilebilirler. R ilişkilerimiz böyle görünecek> ve R< ilişkisel bir veritabanında. Kesin bir sıra ilişkisi (R ilişkisi yerine>):
Kesin bir sıra ilişkisi (R ilişkisi yerine<):
Her iki tablo ilişkisi de yeni bir tane alır (bu durumda, aynı, çünkü ek başlıklar ekleyerek, R ilişkileri arasındaki farkları sildik.> ve R<) Başlık. Böylece, tablolara gerekli başlıkları eklemek gibi basit bir hile yardımıyla, R bağıntılarının olduğu gerçeğine geldiğimizi görüyoruz.> ve R< birbirine eşdeğer hale gelir. Böylece, genel matematiksel ve ilişkisel anlamda "ilişki" kavramının tamamen örtüşmediği, özdeş olmadıkları sonucuna varıyoruz. Şu anda, ilişkisel veritabanı yönetim sistemleri bilgi teknolojisi pazarının temelini oluşturmaktadır. İlişkisel modelin değişen derecelerini birleştirme yönünde daha fazla araştırma yürütülmektedir. Ders #2. Eksik Veri Veritabanı yönetim sistemlerinde eksik verileri tespit etmek için iki tür değer tanımlanmıştır: boş (veya Boş değerler) ve tanımsız (veya Boş değerler). Bazı (çoğunlukla ticari) literatürde, Null değerlere bazen boş veya null değerler olarak atıfta bulunulur, ancak bu yanlıştır. Boş ve belirsiz anlamların anlamı temelde farklıdır, bu nedenle belirli bir terimin kullanım bağlamını dikkatlice izlemek gerekir. 1. Boş değerler (Boş değerler) boş değer bazı iyi tanımlanmış veri türleri için olası birçok değerden biridir. En "doğal" olanı hemen listeliyoruz boş değerler (yani herhangi bir ek bilgiye sahip olmadan kendi başımıza atayabileceğimiz boş değerler): 1) 0 (sıfır) - sayısal veri türleri için boş değer; 2) false (yanlış) - boolean veri türü için boş bir değerdir; 3) B'' - değişken uzunluklu diziler için boş bit dizisi; 4) "" - değişken uzunluktaki karakter dizileri için boş dize. Yukarıdaki durumlarda, var olan değeri her veri türü için tanımlanan boş sabitle karşılaştırarak bir değerin boş olup olmadığını belirleyebilirsiniz. Ancak veritabanı yönetim sistemleri, uzun süreli veri depolama için uygulanan şemalar nedeniyle yalnızca sabit uzunluktaki dizilerle çalışabilir. Bu nedenle, boş bir bit dizisi, bir ikili sıfır dizisi olarak adlandırılabilir. Veya boşluklardan veya diğer kontrol karakterlerinden oluşan bir dize, boş bir karakter dizisidir. Sabit uzunluktaki boş dizelere ilişkin bazı örnekler: 1) B'0'; 2) B'000'; 3) ' '. Bu durumlarda bir dizenin boş olup olmadığını nasıl anlarsınız? Veritabanı yönetim sistemlerinde, boşluğu, yani yüklemi test etmek için mantıksal bir işlev kullanılır. IsBoş(<ifade>), kelimenin tam anlamıyla "boş yemek" anlamına gelir. Bu yüklem genellikle veritabanı yönetim sisteminde yerleşiktir ve her türlü ifadeye uygulanabilir. Veritabanı yönetim sistemlerinde böyle bir yüklem yoksa, mantıksal bir işlevi kendiniz yazabilir ve tasarlanan veritabanının nesneleri listesine dahil edebilirsiniz. Boş bir değere sahip olup olmadığımızı belirlemenin o kadar kolay olmadığı başka bir örnek düşünün. Tarih türü verileri. Tarih 01.01.0100 aralığında değişebiliyorsa, bu türdeki hangi değer boş bir değer olarak kabul edilmelidir. 31.12.9999/XNUMX/XNUMX'dan önce mi? Bunu yapmak için, DBMS'ye özel bir atama eklenir. boş tarih sabitleri {...}, bu türün değeri yazılırsa: {DD. MM. YY} veya {YY. MM. DD}. Bu değerle, boşluk değeri kontrol edilirken bir karşılaştırma gerçekleşir. Bu tür bir ifadenin iyi tanımlanmış, "tam" değeri ve mümkün olan en küçük değer olarak kabul edilir. Veritabanları ile çalışırken null değerler genellikle varsayılan değerler olarak kullanılır veya ifade değerlerinin eksik olduğu durumlarda kullanılır. 2. Tanımsız değerler (boş değerler) Kelime Null belirtmek için kullanılır tanımsız değerler veritabanlarında. Hangi değerlerin tanımsız olarak anlaşıldığını daha iyi anlamak için, bir veritabanının parçası olan bir tablo düşünün:
Bu durumda, tanımsız değer veya Boş değer - şudur: 1) bilinmiyor, ancak olağan, yani uygulanabilir değer. Örneğin, veri tabanımızda bir numara olan Bay Khairetdinov'un şüphesiz bazı pasaport bilgileri vardır (1980 doğumlu bir kişi ve ülke vatandaşı gibi), ancak bilinmemektedir, bu nedenle veri tabanına dahil edilmemiştir. . Bu nedenle Null değeri tablonun ilgili sütununa yazılacaktır; 2) geçerli olmayan değer. Bay Karamazov (veritabanımızdaki 2. numara) herhangi bir pasaport verisine sahip olamaz, çünkü bu veri tabanının oluşturulduğu veya verinin girildiği sırada o bir çocuktu; 3) Uygulanabilir olup olmadığını söyleyemezsek, tablonun herhangi bir hücresinin değeri. Örneğin, veri tabanımızda üçüncü sırada yer alan Bay Kovalenko, doğum yılını bilmiyor, bu nedenle pasaport verilerinin olup olmadığını kesin olarak söyleyemeyiz. Ve sonuç olarak, Bay Kovalenko'ya tahsis edilen satırdaki iki hücrenin değerleri Null-değer olacaktır (birincisi - genel olarak bilinmeyen, ikincisi - doğası bilinmeyen bir değer olarak). Diğer tüm veri türleri gibi Null değerlerinin de belirli özellikleri. Bunlardan en önemlilerini sıralıyoruz: 1) Zamanla, Null değerinin anlaşılması değişebilir. Örneğin, 2'te Bay Karamazov (veritabanımızdaki 2014. numara) için, yani reşit olma yaşına ulaşıldığında, Boş değer belirli, iyi tanımlanmış bir değere değişecektir; 2) Herhangi bir türdeki (sayısal, dize, boolean, tarih, saat, vb.) bir değişkene veya sabite bir boş değer atanabilir; 3) işlenen olarak Boş değerlere sahip ifadeler üzerindeki herhangi bir işlemin sonucu bir Boş değerdir; 4) önceki kuralın bir istisnası, soğurma yasalarının koşulları altındaki birleşme ve ayrılma işlemleridir (soğurma yasaları hakkında daha fazla ayrıntı için, 4 No'lu dersin 2. paragrafına bakınız). 3. Boş değerler ve ifadeleri değerlendirmek için genel kural Null değerleri içeren ifadelerdeki eylemler hakkında daha fazla konuşalım. Boş değerlerle ilgili genel kural (Boş değerler üzerindeki işlemlerin sonucunun Boş değer olduğu) aşağıdaki işlemler için geçerlidir: 1) aritmetik için; 2) bit düzeyinde olumsuzlama, bağlaç ve ayırma işlemlerine (absorpsiyon yasaları hariç); 3) dizelerle işlemlere (örneğin, birleştirme - dizelerin birleştirilmesi); 4) karşılaştırma işlemlerine (<, ≤, ≠, ≥, >). Örnekler verelim. Aşağıdaki işlemlerin uygulanması sonucunda Null değerler elde edilecektir: 3 + Null, 1/ Null, (Ivanov' + '' + Null) ≔ Null Burada her zamanki eşitlik yerine kullanıyoruz ikame işlemi Null değerlerle çalışmanın özel doğası nedeniyle "≔". Aşağıda, bu karakter benzer durumlarda da kullanılacaktır; bu, joker karakterin sağındaki ifadenin, joker karakterin solundaki listedeki herhangi bir ifadenin yerini alabileceği anlamına gelir. Null değerlerinin doğası genellikle bazı ifadelerin beklenen null yerine Null değeri üretmesine neden olur, örneğin: (x - x), y * (x - x), x * 0 ≔ x = Boş olduğunda boş. Mesele şu ki, örneğin, x = Null değerini (x - x) ifadesine değiştirirken, (Null - Null) ifadesini ve Null değerleri içeren ifadenin değerini hesaplamak için genel kuralı elde ederiz. yürürlüğe girer ve burada Null değerinin aynı değişkene tekabül ettiği bilgisi kaybolur. Mantıksal olanlar dışındaki herhangi bir işlem hesaplanırken Null değerlerin şu şekilde yorumlandığı sonucuna varabiliriz. uygulanamaz, ve böylece sonuç da bir Null değeridir. Null değerlerinin karşılaştırma işlemlerinde kullanılması, daha az beklenmedik sonuçlara yol açmaz. Örneğin, aşağıdaki ifadeler de beklenen Boolean True veya False değerleri yerine Null değerler üretir: (Boş < Boş); (Hükümsüz ≤ hükümsüz); (Boş = Boş); (Boş ≠ Boş); (Boş > Boş); (Boş ≥ Boş) ≔ Boş; Böylece, bir Null değerinin kendisine eşit olduğunu veya kendisine eşit olmadığını söylemenin imkansız olduğu sonucuna varıyoruz. Null değerinin her yeni oluşumu bağımsız olarak kabul edilir ve Null değerleri her seferinde farklı bilinmeyen değerler olarak değerlendirilir. Bunda, Null değerler diğer tüm veri türlerinden temel olarak farklıdır, çünkü daha önce geçen tüm değerler ve bunların türleri hakkında birbirine eşit veya eşit olmadıklarını söylemenin güvenli olduğunu biliyoruz. Yani Null değerlerin kelimenin genel anlamıyla değişkenlerin değerleri olmadığını görüyoruz. Bu nedenle, Null değerleri içeren değişkenlerin veya ifadelerin değerlerini karşılaştırmak imkansız hale gelir, çünkü sonuç olarak aşağıdaki örneklerde olduğu gibi boole True veya False değerlerini değil, Null değerlerini alacağız: (x < Boş); (x ≤ hükümsüz); (x=Boş); (x ≠ Boş); (x > Boş); (x ≥ Boş) ≔ Boş; Bu nedenle, boş değerlere benzeterek, Null değerler için bir ifadeyi kontrol etmek için özel bir yüklem kullanmanız gerekir: IsNull(<ifade>), kelimenin tam anlamıyla "Boştur" anlamına gelir. Boolean işlevi, ifade Null içeriyorsa veya Null değerine eşitse True, aksi takdirde False döndürür, ancak hiçbir zaman Null döndürmez. IsNull yüklemi, herhangi bir türdeki değişkenlere ve ifadelere uygulanabilir. Boş türdeki ifadelere uygulandığında, yüklem her zaman False döndürür. Örneğin:
Gerçekten de ilk durumda, IsNull yüklemi sıfırdan alındığında çıktının False olduğunu görüyoruz. İkinci ve üçüncü de dahil olmak üzere tüm durumlarda, mantıksal işlevin argümanlarının Null değerine eşit olduğu ortaya çıktığında ve dördüncü durumda, argümanın kendisi başlangıçta Null değerine eşit olduğunda, yüklem True döndürdü. 4. Boş değerler ve mantıksal işlemler Tipik olarak, veritabanı yönetim sistemlerinde yalnızca üç mantıksal işlem doğrudan desteklenir: olumsuzlama ¬, bağlaç & ve ayırma ∨. Ardışık ⇒ ve denklik ⇔ işlemleri, ikameler kullanılarak bunlara göre ifade edilir: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Null değerler kullanılırken bu ikamelerin tamamen korunduğunu unutmayın. İlginç bir şekilde, "¬" olumsuzlama operatörünü kullanarak, bağlaç & veya ayırma ∨ işlemlerinden herhangi biri, aşağıdaki gibi birinden diğerine ifade edilebilir: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); Bu ikameler ve öncekiler, Null-değerlerinden etkilenmez. Ve şimdi olumsuzlama, birleşme ve ayrılmanın mantıksal işlemlerinin doğruluk tablolarını vereceğiz, ancak olağan True ve False değerlerine ek olarak, işlenen olarak Null değerini de kullanıyoruz. Kolaylık sağlamak için aşağıdaki gösterimi sunuyoruz: True yerine False - f yerine t ve Null - n yerine t yazacağız. 1. ret xx.
Null değerleri kullanarak olumsuzlama işlemiyle ilgili olarak aşağıdaki ilginç noktalara dikkat etmek gerekir: 1) ¬¬x ≔ x - çifte olumsuzlama yasası; 2) ¬Null ≔ Null - Null değeri sabit bir noktadır. 2. bağlaç x & y.
Bu işlemin de kendine has özellikleri vardır: 1) x & y ≔ y & x - değişebilirlik; 2) x & x ≔ x - bağımsız; 3) False & y ≔ False, burada False emici bir öğedir; 4) True & y ≔ y, burada True nötr elementtir. 3. Ayrışma x ∨ y.
Özellikler: 1) x ∨ y ≔ y ∨ x - değişebilirlik; 2) x ∨ x ≔ x - bağımsız olma; 3) False ∨ y ≔ y, burada False nötr öğedir; 4) Doğru ∨ y ≔ Doğru, burada Doğru emici bir unsurdur. Genel kuralın bir istisnası, eylem koşulları altında mantıksal işlemlerin birleşimi ve ayrılması ∨ hesaplama kurallarıdır. absorpsiyon yasaları: (Yanlış ve y) ≔ (x ve Yanlış) ≔ Yanlış; (Doğru ∨ y) ≔ (x ∨ Doğru) ≔ Doğru; Bu ek kurallar, bir Null değeri False veya True ile değiştirildiğinde sonucun yine de bu değere bağlı olmayacağı şekilde formüle edilmiştir. Diğer işlem türleri için daha önce gösterildiği gibi, Boolean işlemlerde Null değerlerin kullanılması da beklenmeyen değerlere neden olabilir. Örneğin, ilk bakışta mantık bozulur. üçüncünün hariç tutulması yasası (x ∨ ¬x) ve refleksivite yasası (x = x), çünkü x ≔ Null için: (x ∨ ¬x), (x = x) ≔ Boş. Kanunlar uygulanmıyor! Bu, daha önce olduğu gibi açıklanır: Null bir değer bir ifadeye yerleştirildiğinde, bu değerin aynı değişken tarafından rapor edildiği bilgisi kaybolur ve Null değerlerle çalışmanın genel kuralı yürürlüğe girer. Böylece şu sonuca varıyoruz: Bir işlenen olarak Null değerlerle mantıksal işlemler gerçekleştirirken, bu değerler veritabanı yönetim sistemleri tarafından şu şekilde belirlenir: uygulanabilir ancak bilinmiyor. 5. Boş değerler ve durum kontrolü Dolayısıyla, yukarıdakilerden, veritabanı yönetim sistemlerinin mantığında iki mantıksal değer (Doğru ve Yanlış) değil, üç olduğu sonucuna varabiliriz, çünkü Boş değer de olası mantıksal değerlerden biri olarak kabul edilir. Bu nedenle genellikle bilinmeyen değer, Bilinmeyen değer olarak adlandırılır. Ancak buna rağmen, veritabanı yönetim sistemlerinde sadece iki değerli mantık uygulanmaktadır. Bu nedenle, Null değerine sahip bir koşul (tanımlanmamış bir koşul), makine tarafından Doğru veya Yanlış olarak yorumlanmalıdır. Varsayılan olarak, DBMS dili Null değerine sahip bir koşulu False olarak tanır. Bunu, veritabanı yönetim sistemlerinde koşullu If ve While ifadelerinin uygulanmasına ilişkin aşağıdaki örneklerle gösteriyoruz: P ise A ise B; Bu giriş şu anlama gelir: P Doğru olarak değerlendirilirse, A eylemi gerçekleştirilir ve P Yanlış veya Boş olarak değerlendirilirse, B eylemi gerçekleştirilir. Şimdi olumsuzlama işlemini bu operatöre uygularsak, şunu elde ederiz: ¬P ise B, aksi takdirde A; Buna karşılık, bu operatör şu anlama gelir: ¬P Doğru olarak değerlendirilirse B eylemi gerçekleştirilir ve ¬P Yanlış veya Boş olarak değerlendirilirse A eylemi gerçekleştirilir. Ve yine gördüğümüz gibi bir Null değeri göründüğünde beklenmedik sonuçlarla karşılaşıyoruz. Buradaki nokta, bu örnekteki iki If ifadesinin eşdeğer olmamasıdır! Her ne kadar biri diğerinden koşulun olumsuzlanması ve dalların yeniden düzenlenmesi, yani standart işlem ile elde edilse de. Bu tür operatörler genellikle eşdeğerdir! Ancak örneğimizde, ilk durumda P koşulunun boş değerinin B komutuna ve ikinci durumda - A'ya karşılık geldiğini görüyoruz. Şimdi while koşullu ifadesinin eylemini düşünün: P, A'yı yaparken; B; Bu operatör nasıl çalışır? P Doğru olduğu sürece, A eylemi yürütülür ve P Yanlış veya Boş olduğunda, B eylemi yürütülür. Ancak Null değerler her zaman False olarak yorumlanmaz. Örneğin, bütünlük kısıtlamalarında tanımsız koşullar Doğru olarak tanınır (bütünlük kısıtlamaları, giriş verilerine uygulanan ve bunların doğruluğunu sağlayan koşullardır). Bunun nedeni, bu tür kısıtlamalarda yalnızca kasıtlı olarak yanlış verilerin reddedilmesi gerektiğidir. Ve yine veri tabanı yönetim sistemlerinde özel bir ikame işlevi IfNull(bütünlük kısıtlamaları, True)Null değerlerin ve tanımsız koşulların açıkça gösterilebildiği . Bu işlevi kullanarak koşullu If ve While ifadelerini yeniden yazalım: 1) IfNull ( P, False) ise A yoksa B; 2) IfNull(P, False) A yaparken; B; Dolayısıyla, ikame işlevi IfNull(ifade 1, ifade 2), bir Null değeri içermiyorsa ilk ifadenin değerini, değilse ikinci ifadenin değerini döndürür. IfNull işlevi tarafından döndürülen ifadenin türüne herhangi bir kısıtlama getirilmediğine dikkat edilmelidir. Bu nedenle, bu işlevi kullanarak Null değerlerle çalışmak için tüm kuralları açıkça geçersiz kılabilirsiniz. Ders #3. İlişkisel Veri Nesneleri 1. İlişkilerin tablo şeklinde gösterimi için gereklilikler 1. İlişkilerin temsilinin tablo biçimi için ilk gereklilik sonluluktur. Sonsuz tablolar, ilişkiler veya diğer temsiller ve veri organizasyonlarıyla çalışmak zahmetlidir, harcanan çabayı nadiren haklı çıkarır ve ayrıca bu yönün pratik uygulaması çok azdır. Ancak bunun yanı sıra, oldukça beklenen başka gereksinimler de var. 2. İlişkiyi temsil eden tablonun başlığı mutlaka bir satırdan oluşmalıdır - sütunların başlığı ve benzersiz adlarla. Çok seviyeli başlıklara izin verilmez. Örneğin, bunlar:
Tüm çok katmanlı başlıklar, uygun başlıklar seçilerek tek katmanlı başlıklarla değiştirilir. Örneğimizde, belirtilen dönüşümlerden sonraki tablo şöyle görünecektir:
Her sütunun adının benzersiz olduğunu görüyoruz, böylece istediğiniz gibi değiştirilebiliyorlar, yani sıraları alakasız hale geliyor. Ve bu çok önemlidir çünkü üçüncü özelliktir. 3. Satırların sırası alakasız olmalıdır. Bununla birlikte, herhangi bir tablo kolayca istenen forma indirgenebildiğinden, bu gereklilik de kesinlikle kısıtlayıcı değildir. Örneğin, satırların sırasını belirleyecek ek bir sütun girebilirsiniz. Bu durumda, çizgilerin permütasyonundan hiçbir şey değişmeyecektir. İşte böyle bir tablonun bir örneği:
4. Tabloda ilişkiyi temsil eden yinelenen satırlar olmamalıdır. Tabloda yinelenen satırlar varsa, bu, her satırın yinelenen sayısından sorumlu ek bir sütun eklenerek kolayca düzeltilebilir, örneğin:
Aşağıdaki özellik de oldukça beklenir, çünkü ilişkisel veritabanlarını programlama ve tasarlamanın tüm ilkelerinin temelini oluşturur. 5. Tüm sütunlardaki veriler aynı türde olmalıdır. Ayrıca, basit tipte olmalıdırlar. Basit ve karmaşık veri türlerinin ne olduğunu açıklayalım. Basit bir veri türü, veri değerleri bileşik olmayan, yani kurucu parçalar içermeyen bir veri türüdür. Bu nedenle, tablonun sütunlarında ne listeler, ne diziler, ne ağaçlar ne de benzer bileşik nesneler bulunmamalıdır. Bu tür nesneler bileşik veri türü - ilişkisel veritabanı yönetim sistemlerinde, kendileri bağımsız tablolar-ilişkiler şeklinde sunulurlar. 2. Etki alanları ve nitelikler Etki alanları ve nitelikler, veritabanları oluşturma ve yönetme teorisindeki temel kavramlardır. Ne olduğunu açıklayalım. resmi olarak, nitelik etki alanı (belirtilen ev(a)), a'nın bir öznitelik olduğu yerde, karşılık gelen a özniteliğinin aynı türden geçerli değerler kümesi olarak tanımlanır. Bu tür basit olmalıdır, yani: dom(a) ⊆ {x | tip(x) = tip(a)}; Öznitelik (a ile gösterilir) sırayla name(a) öznitelik alanı ve dom(a) özniteliğinden oluşan sıralı bir çift olarak tanımlanır, yani: a = (isim(a): dom(a)); Bu tanım, olağan "," yerine ":" kullanır (standart sıralı çift tanımlarında olduğu gibi). Bu, özniteliğin etki alanı ve özniteliğin veri türü arasındaki ilişkiyi vurgulamak için yapılır. Aşağıda, farklı niteliklere ilişkin bazı örnekler verilmiştir: а1 = (Ders: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | tür(x) = gerçek, x 0}); а3 = (UzunlukSm: {x | tür(x) = gerçek, x 0}); özniteliklerin bir2 ve bir3 alan adları resmi olarak eşleşir. Ancak bu niteliklerin anlamsal anlamı farklıdır, çünkü kütle ve uzunluk değerlerini karşılaştırmak anlamsızdır. Bu nedenle, bir öznitelik alanı yalnızca geçerli değerlerin türüyle değil, aynı zamanda anlamsal bir anlamla da ilişkilidir. Bir ilişkinin tablo biçiminde, öznitelik tabloda bir sütun başlığı olarak görüntülenir ve özniteliğin etki alanı belirtilmez, ancak ima edilir. Şuna benziyor:
Burada başlıkların her birinin bir1,2,3 bir ilişkiyi temsil eden bir tablonun sütunları ayrı bir niteliktir. 3. İlişki şemaları. Adlandırılmış değer demetleri DBMS'nin teori ve pratiğinde, bir ilişki şeması ve bir nitelik üzerindeki bir tanımlama grubunun adlandırılmış değeri kavramları temeldir. Onları getirelim. ilişki şeması (belirtilen S) benzersiz adlara sahip sonlu bir nitelik kümesi olarak tanımlanır, yani: S = {a | bir ∈ S}; Bir ilişkiyi temsil eden her tabloda, tüm sütun başlıkları (tüm nitelikler) ilişkinin şemasında birleştirilir. İlişki şemasındaki özniteliklerin sayısı şunları belirler: güç o ilişkiler ve kümenin kardinalitesi olarak gösterilir: |S|. Bir ilişki şeması, bir ilişki şeması adıyla ilişkilendirilebilir. Tablo şeklinde bir ilişki gösterimi biçiminde, kolayca görebileceğiniz gibi, ilişki şeması bir dizi sütun başlığından başka bir şey değildir.
S = {bir1,2,3,4} - bu tablonun ilişki şeması. İlişki adı, tablonun şematik bir başlığı olarak görüntülenir. Metin biçiminde, ilişki şeması, nitelik adlarının adlandırılmış bir listesi olarak temsil edilebilir, örneğin: Öğrenciler (ders kitabı numarası, soyadı, adı, soyadı, doğum tarihi). Burada, tablo biçiminde olduğu gibi, nitelik alanları belirtilmez, ancak ima edilir. Tanımdan, bir ilişkinin şemasının da boş olabileceği sonucu çıkar (S = ∅). Doğru, bu sadece teoride mümkündür, çünkü pratikte veritabanı yönetim sistemi asla boş bir ilişki şeması oluşturulmasına izin vermez. Nitelikte adlandırılmış demet değeri (belirtilen t(a)) bir öznitelik adı ve bir öznitelik değerinden oluşan sıralı bir çift olarak bir özniteliğe benzetilerek tanımlanır, yani: t(a) = (isim(a) : x), x ∈ dom(a); Öznitelik değerinin öznitelik alanından alındığını görüyoruz. Bir ilişkinin tablo biçiminde, bir öznitelik üzerindeki bir tanımlama grubunun adlandırılmış her değeri, karşılık gelen bir tablo hücresidir:
Burada t(bir1), t(bir2), t(bir3) - a özniteliklerinde tuple t'nin adlandırılmış değerleri1Ve2Ve3. Niteliklerdeki adlandırılmış demet değerlerinin en basit örnekleri: (Ders: 5), (Puan: 5); Burada Kurs ve Puan, sırasıyla iki özelliğin adıdır ve 5, etki alanlarından alınan değerlerinden biridir. Elbette bu değerler her iki durumda da eşit olsa da, her iki durumda da bu değerlerin kümeleri birbirinden farklı olduğu için anlamsal olarak farklıdır. 4. Tuple'lar. demet türleri Veritabanı yönetim sistemlerinde bir demet kavramı, çeşitli nitelikler üzerinde bir demetin adlandırılmış değeri hakkında konuştuğumuzda, önceki noktadan sezgisel olarak bulunabilir. Yani, demet (belirtilen t, İngilizceden. Tuple - "Tuple"), ilişki şeması S ile bu ilişki şemasına S dahil edilen tüm öznitelikler üzerinde bu demetin adlandırılmış değerleri kümesi olarak tanımlanır. Başka bir deyişle, öznitelikler bir demetin kapsamı, def(t), yani: t ≡ t(K) = {t(a) | a ∈ def(t) ⊆ S;. Birden fazla öznitelik değerinin bir öznitelik adına karşılık gelmemesi önemlidir. İlişkinin tablo biçiminde, bir demet, tablonun herhangi bir satırı olacaktır, yani:
burada1(S) = {t(bir1), t(bir2), t(bir3), t(bir4)} ve t2(S) = {t(bir5), t(bir6), t(bir7), t(bir8)} - demetler. DBMS'deki demetler farklıdır türleri tanım alanına göre değişir. Tuples denir: 1) kısmi, eğer tanım alanları ilişki şemasına dahil edilmişse veya onunla örtüşüyorsa, yani def(t) ⊆ S. Bu, veritabanı uygulamasında yaygın bir durumdur; 2) tamamlayınıztanım alanlarının tamamen örtüşmesi durumunda ilişki şemasına eşittir, yani def(t) = S; 3) eksik, eğer tanım alanı tamamen ilişkiler şemasına dahil edilmişse, yani def(t) ⊂ S; 4) hiçbir yerde tanımlanmadı, eğer tanım alanları boş kümeye eşitse, yani def(t) = ∅. Bir örnekle açıklayalım. Aşağıdaki tabloda verilen bir ilişkimiz olduğunu varsayalım.
Burada t olsun1 = {10, 20, 30}, t2 = {10, 20, Boş}, t3 = {Boş, Boş, Boş}. O zaman tuple t'nin olduğunu görmek kolaydır.1 - tanım alanı def(t olduğundan) tamamlandı1) = {a, b, c} = S. demet t2 - eksik, def(t2) = { a, b} ⊂ S. Son olarak, t demeti3 - def(t3) = ∅ olduğundan hiçbir yerde tanımlanmamıştır. Hiçbir yerde tanımlanmayan bir demetin boş bir küme olduğu, ancak yine de bir ilişki şemasıyla ilişkili olduğu belirtilmelidir. Bazen hiçbir yerde tanımlanmamış bir demet gösterilir: ∅(S). Yukarıdaki örnekte zaten gördüğümüz gibi, böyle bir demet sadece Null değerlerden oluşan bir tablo satırıdır. İlginç bir şekilde, karşılaştırılabilir, yani muhtemelen eşit, yalnızca aynı ilişki şemasına sahip demetlerdir. Bu nedenle, örneğin, beklendiği gibi, farklı ilişki şemalarına sahip hiçbir yerde tanımlı olmayan iki demet eşit olmayacaktır. Tıpkı ilişki kalıpları gibi farklı olacaklar. 5. İlişkiler. ilişki türleri Ve son olarak, ilişkiyi, önceki tüm kavramlardan oluşan bir tür piramidin tepesi olarak tanımlayalım. Yani, отношение (belirtilen r, İngilizceden. ilişki) ile ilişki şeması S, aynı ilişki şeması S'ye sahip zorunlu olarak sonlu bir demetler kümesi olarak tanımlanır. Böylece: r ≡ r(S) = {t(S) | t r}; İlişki şemalarına benzeterek, bir ilişkideki demet sayısı denir. ilişki gücü ve kümenin kardinalitesi olarak belirtilir: |r|. İlişkiler, demetler gibi türlerde farklılık gösterir. Yani ilişki denir: 1) kısmi, ilişkideki herhangi bir demet için aşağıdaki koşul sağlanırsa: [def(t) ⊆ S]. Bu (tuple'larda olduğu gibi) genel durumdur; 2) tamamlayınız, eğer varsa ∀t ∈ r(S) elimizde [def(t) = S] var; 3) eksik, ise ∃t ∈ r(S) def(t) ⊂ S; 4) hiçbir yerde tanımlanmadı, eğer ∀t ∈ r(S) [def(t) = ∅]. Hiçbir yerde tanımlanmamış ilişkilere özellikle dikkat edelim. Tuple'lardan farklı olarak, bu tür ilişkilerle çalışmak biraz incelik gerektirir. Mesele şu ki, hiçbir yerde tanımlı olmayan ilişkiler iki tip olabilir: ya boş olabilirler ya da hiçbir yerde tanımlı olmayan tek bir demet içerebilirler (bu tür ilişkiler {∅(S)} ile gösterilir). karşılaştırılabilir (tuples ile analoji ile), yani muhtemelen eşit, yalnızca aynı ilişki şemasına sahip ilişkilerdir. Bu nedenle, farklı ilişki şemalarına sahip ilişkiler farklıdır. Tablo biçiminde, bir ilişki, satırın - sütunların başlığının, yani kelimenin tam anlamıyla - tüm tablonun, başlıkları içeren ilk satırla birlikte karşılık geldiği tablonun gövdesidir. Ders No. 4. İlişkisel cebir. tekli işlemler İlişkisel cebirTahmin edebileceğiniz gibi, tüm işlemlerin ilişkisel veri modelleri üzerinde, yani ilişkiler üzerinde gerçekleştirildiği özel bir cebir türüdür. Tablo terimleriyle, bir ilişki satırları, sütunları ve bir satırı (sütunların başlığını) içerir. Bu nedenle, doğal tekli işlemler, belirli satırları veya sütunları seçmenin yanı sıra sütun başlıklarını değiştirme - nitelikleri yeniden adlandırma işlemleridir. 1. Tekli seçim işlemi Bakacağımız ilk tekli işlem getirme işlemi - bir ilişkiyi temsil eden bir tablodan bazı ilkelere göre satırları seçme işlemi, yani belirli bir koşulu veya koşulları karşılayan satırları seçme işlemi. Getirme Operatörü σ ile gösterilir , örnekleme koşulu - P , yani, σ operatörü her zaman P demetleri üzerinde belirli bir koşulla alınır ve P koşulunun kendisi S ilişkisinin şemasına bağlı olarak yazılır. Bütün bunlar dikkate alındığında, getirme işlemi S ilişkisinin şeması üzerinde, r ilişkisine göre şöyle görünecektir: σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, Yanlış}; Bu işlemin sonucu, P t seçim koşulunu karşılayan orijinal ilişki-operandının t(S) demetlerinden oluşan aynı ilişki şeması S ile yeni bir ilişki olacaktır. Bir demete bir tür koşul uygulamak için, öznitelik adları yerine demet özniteliklerinin değerlerini değiştirmek gerektiği açıktır. Bu işlemin nasıl çalıştığını daha iyi anlamak için bir örneğe bakalım. Aşağıdaki ilişki şeması verilsin: D: Oturum (Defter No., Soyad, Konu, Not). Seçim koşulunu aşağıdaki gibi alalım: P = (Konu = 'Bilgisayar Bilimi' ve Değerlendirme > 3). İlk ilişki işleneninden "Bilgisayar Bilimi" dersini en az üç puan ile geçen öğrenciler hakkında bilgi içeren demetleri çıkarmamız gerekiyor. Bu bağıntıdan aşağıdaki demet de verilsin: t0(S) ∈ r(S): {(sınıf defteri numarası: 100), (Soyadı: 'Ivanov'), (Konu: 'Veritabanları'), (Puan: 5)}; Seçim koşulumuzu tuple t'ye uygulamak0, şunu elde ederiz: P t0 = ('Veritabanları' = 'Bilişim' ve 5 > 3); Bu belirli demette, seçim koşulu karşılanmadı. Genel olarak, bu özel örneğin sonucu σ<Konu = 'Bilgisayar Bilimi' ve Sınıf > 3 > Oturum seçim koşulunu sağlayan satırların bırakıldığı bir "Oturum" tablosu olacaktır. 2. Tekli projeksiyon işlemi Üzerinde çalışacağımız bir diğer standart tekli işlem ise izdüşüm işlemidir. Projeksiyon işlemi bir ilişkiyi temsil eden bir tablodan bazı niteliklere göre sütun seçme işlemidir. Yani makine, orijinal işlenen ilişkisinin izdüşümde belirtilen niteliklerini (yani, kelimenin tam anlamıyla bu sütunları) seçer. projeksiyon operatörü [S'] veya π ile gösterilir . Burada S', S ilişkisinin orijinal şemasının, yani bazı sütunlarının bir alt şemasıdır. Ne anlama geliyor? Bu, S''nin S'den daha az özniteliğe sahip olduğu anlamına gelir, çünkü S' içinde yalnızca yansıtma koşulunun sağlandığı öznitelikler kalmıştır. Ve r(S') ilişkisini temsil eden tabloda, r(S) tablosundaki kadar çok satır vardır ve sadece kalan niteliklere karşılık gelenler kaldığından daha az sütun vardır. Böylece, r(S) ilişkisine uygulanan izdüşüm operatörü π< S'>, t(S) [S' ] izdüşümlerinden oluşan farklı bir ilişki şeması r(S' ) ile yeni bir ilişki ile sonuçlanır. orijinal ilişki. Bu demet projeksiyonları nasıl tanımlanır? Projeksiyon S' alt devresine r(S) orijinal ilişkisinin herhangi bir t(S) demetinin aşağıdaki formülle belirlenir: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. Yinelenen kümelerin sonuçtan hariç tutulduğunu, yani tabloda yenisini temsil eden yinelenen satırların olmayacağını not etmek önemlidir. Yukarıdakilerin tümü göz önünde bulundurulduğunda, veritabanı yönetim sistemleri açısından bir projeksiyon işlemi şöyle görünecektir: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; Getirme işleminin nasıl çalıştığını gösteren bir örneğe bakalım. "Oturum" ilişkisi ve bu ilişkinin şeması verilsin: S: Oturum (ders kitabı numarası, Soyadı, Konusu, Sınıfı); Bu şemadan sadece iki öznitelikle ilgileneceğiz, yani öğrencinin "Sınıf Defteri #" ve "Soyadı", dolayısıyla S' alt şeması şöyle görünecektir: S' : (Kayıt defteri numarası, Soyadı). Başlangıç ilişkisini r(S) S' alt devresine yansıtmamız gerekiyor. Sonra, bize bir tuple t verilsin0(S) orijinal ilişkiden: t0(S) ∈ r(S): {(sınıf defteri numarası: 100), (Soyadı: 'Ivanov'), (Konu: 'Veritabanları'), (Puan: 5)}; Dolayısıyla, bu demetin verilen S' alt devresi üzerindeki izdüşümü şöyle görünecektir: t0(S) S': {(Hesap defteri numarası: 100), (Soyadı: 'Ivanov')}; Tablolar üzerinden izdüşüm işleminden bahsedecek olursak, orijinal ilişkinin projeksiyon Oturumu [not defteri numarası, Soyadı], ikisi hariç tüm sütunların silindiği Oturum tablosudur: not defteri numarası ve Soyadı. Ayrıca, tüm yinelenen satırlar da kaldırılmıştır. 3. Tekli yeniden adlandırma işlemi Ve bakacağımız son tekli işlem öznitelik yeniden adlandırma işlemi. İlişkiden tablo olarak bahsedersek, sütunların tamamının veya bir kısmının adını değiştirmek için yeniden adlandırma işlemi gerekir. operatörü yeniden adlandır şuna benziyor: ρ<φ>, burada φ - işlevi yeniden adlandır. Bu işlev, S ve Ŝ şema öznitelik adları arasında bire bir yazışma kurar; burada sırasıyla S, orijinal ilişkinin şemasıdır ve Ŝ, yeniden adlandırılan özniteliklerle ilişkinin şemasıdır. Böylece, r(S) ilişkisine uygulanan ρ<φ> operatörü, yalnızca yeniden adlandırılan niteliklerle orijinal ilişkinin demetlerinden oluşan şema Ŝ ile yeni bir ilişki verir. Nitelikleri yeniden adlandırma işlemini veritabanı yönetim sistemleri açısından yazalım: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; İşte bu işlemi kullanmanın bir örneği: Şema ile zaten bize tanıdık olan Oturum ilişkisini düşünelim: S: Oturum (ders kitabı numarası, Soyadı, Konusu, Sınıfı); Mevcut olanlar yerine görmek istediğimiz farklı öznitelik adlarına sahip yeni bir ilişki şeması Ŝ tanıtalım: Ŝ: (No. ZK, Soyad, Konu, Puan); Örneğin, bir veritabanı müşterisi, kullanıma hazır ilişkinizde diğer adları görmek istedi. Bu siparişi uygulamak için aşağıdaki yeniden adlandırma işlevini tasarlamanız gerekir: φ : (kayıt defteri sayısı, Soyadı, Konusu, Sınıfı) → (No. ZK, Soyadı, Konusu, Puanı); Aslında, yalnızca iki özniteliğin yeniden adlandırılması gerekir, bu nedenle geçerli olanın yerine aşağıdaki yeniden adlandırma işlevini yazmak yasaldır: φ : (kayıt defteri sayısı, Derece) → (No. ZK, Puan); Ayrıca, Session ilişkisine ait zaten tanıdık olan demetin de verilmesine izin verin: t0(S) ∈ r(S): {(sınıf defteri numarası: 100), (Soyadı: 'Ivanov'), (Konu: 'Veritabanları'), (Puan: 5)}; Yeniden adlandırma operatörünü bu demete uygulayın: ρ<φ>t0(S): {(ZK#: 100), (Soyadı: 'Ivanov'), (Konu: 'Veritabanları'), (Puan: 5)}; Bu, nitelikleri yeniden adlandırılan ilişkimizin demetlerinden biridir. Tablo olarak, oran ρ < Not defteri numarası, Not → "Hayır. ZK, Puan > Oturum - bu, belirtilen öznitelikleri yeniden adlandırarak "Oturum" ilişki tablosundan elde edilen yeni bir tablodur. 4. Tekli işlemlerin özellikleri Tekli işlemler, diğerleri gibi, belirli özelliklere sahiptir. Bunlardan en önemlilerini ele alalım. Tekli seçim, izdüşüm ve yeniden adlandırma işlemlerinin ilk özelliği, ilişkilerin kardinalitelerinin oranını karakterize eden özelliktir. (Kardinalitenin bir veya başka bir ilişkideki demet sayısı olduğunu hatırlayın.) Burada sırasıyla ilk ilişkiyi ve bir veya başka işlemin uygulanması sonucunda elde edilen ilişkiyi düşündüğümüz açıktır. Tekli işlemlerin tüm özelliklerinin doğrudan tanımlarından kaynaklandığını unutmayın, böylece kolayca açıklanabilirler ve hatta istenirse bağımsız olarak çıkarılabilirler. Yani: 1) güç oranı: a) seçim işlemi için: | σ r |≤ |r|; b) projeksiyon işlemi için: | r[S'] | ≤ |r|; c) yeniden adlandırma işlemi için: | ρ<φ>r | = |r|; Toplamda, iki operatör için, yani seçim operatörü ve izdüşüm operatörü için, orijinal ilişkilerin - işlenenlerin gücünün, karşılık gelen işlemler uygulanarak orijinal olanlardan elde edilen ilişkilerin gücünden daha büyük olduğunu görüyoruz. Bunun nedeni, bu iki seç ve proje işlemine eşlik eden seçimin, seçim koşullarını karşılamayan bazı satırları veya sütunları hariç tutmasıdır. Tüm satırların veya sütunların koşulları sağlaması durumunda, güçte (yani, demet sayısı) azalma olmaz, bu nedenle formüllerdeki eşitsizlik katı değildir. Yeniden adlandırma işlemi durumunda, adları değiştirirken hiçbir tuple'ın ilişkiden dışlanmaması nedeniyle ilişkinin gücü değişmez; 2) idempotent özellik: a) örnekleme işlemi için: σ σ r = σ ; b) projeksiyon işlemi için: r [S'] [S'] = r [S']; c) yeniden adlandırma işlemi için, genel durumda, bağımsız olma özelliği geçerli değildir. Bu özellik, aynı operatörü herhangi bir ilişkiye art arda iki kez uygulamanın, onu bir kez uygulamaya eşdeğer olduğu anlamına gelir. Genel olarak konuşursak, ilişki niteliklerini yeniden adlandırma işlemi için bu özellik uygulanabilir, ancak özel çekinceler ve koşullarla. İdempotans özelliği, bir ifadenin biçimini basitleştirmek ve onu daha ekonomik, gerçek bir biçime getirmek için sıklıkla kullanılır. Ve ele alacağımız son özellik, monotonluğun özelliğidir. Her üç operatörün de her koşulda monoton olduğunu belirtmek ilginçtir; 3) monotonluk özelliği: a) getirme işlemi için: r1 ⊆ r2 ⇒ σ r1 ⇒ σ r2; b) projeksiyon işlemi için: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) yeniden adlandırma işlemi için: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; İlişkisel cebirdeki monotonluk kavramı, sıradan, genel cebirdeki aynı kavrama benzer. Açıklığa kavuşturalım: eğer başlangıçta ilişkiler r1 ve r2 r ⊆ r olacak şekilde birbirleriyle ilişkiliydi2, ardından üç seçim, yansıtma veya yeniden adlandırma işlecinden herhangi birini uyguladıktan sonra bile bu ilişki korunacaktır. Ders No. 5. İlişkisel cebir. İkili İşlemler 1. Birleşim, kesişim, fark işlemleri Herhangi bir işlemin, ifadelerin ve eylemlerin anlamlarını kaybetmemesi için uyulması gereken kendi uygulanabilirlik kuralları vardır. Birleşim, kesişim ve farkın ikili küme teorik işlemleri, yalnızca aynı ilişki şemasıyla zorunlu olarak iki ilişkiye uygulanabilir. Bu tür ikili işlemlerin sonucu, işlemlerin koşullarını karşılayan, ancak işlenenlerle aynı ilişki şemasına sahip olan demetlerden oluşan ilişkiler olacaktır. 1. Sonuç sendika operasyonları iki ilişki r1(S) ve r2(S) yeni bir ilişki olacak r3(S) r ilişki demetlerinden oluşan1(S) ve r2(S) orijinal ilişkilerden en az birine ait ve aynı ilişki şemasına sahip. Yani iki ilişkinin kesişimi: r3(K) = r1(S) r2(K) = {t(K) | t ∈r1 ∪t ∈r2}; Netlik için, tablolar açısından bir örnek: İki bağıntı verilsin: r1(S):
r2(S):
Birinci ve ikinci ilişkilerin şemalarının aynı olduğunu görüyoruz, sadece farklı sayıda demetleri var. Bu iki ilişkinin birleşimi r ilişkisi olacaktır.3(S), aşağıdaki tabloya karşılık gelecektir: r3(K) = r1(S) r2(S):
Yani S ilişkisinin şeması değişmedi, sadece demet sayısı arttı. 2. Aşağıdaki ikili işlemin değerlendirilmesine geçelim - kavşak işlemleri iki ilişki. Okul geometrisinden bildiğimiz gibi, sonuçta ortaya çıkan ilişki, yalnızca her iki ilişkide de aynı anda mevcut olan orijinal ilişkilerin demetlerini içerecektir.1(S) ve r2(S) (yine aynı ilişki düzenine dikkat edin). İki ilişkinin kesişme işlemi şöyle görünecektir: r4(K) = r1(S) ∩r2(K) = {t(K) | t ∈ r1 & t ∈ r2}; Ve yine, bu işlemin tablolar şeklinde sunulan ilişkiler üzerindeki etkisini düşünün: r1(S):
r2(S):
İlişkilerin kesişimi ile işlemin tanımına göre r1(S) ve r2(S) yeni bir ilişki olacak r4(S), tablo görünümü şöyle görünecektir: r4(K) = r1(S) ∩r2(S):
Gerçekten de, birinci ve ikinci başlangıç bağıntılarının demetlerine bakarsanız, aralarında yalnızca bir ortak nokta vardır: {b, 2}. Yeni ilişkinin tek demeti oldu r4(S). 3. Fark işlemi iki ilişki önceki işlemlere benzer şekilde tanımlanır. Operand ilişkileri, önceki işlemlerde olduğu gibi, aynı ilişki şemalarına sahip olmalıdır, o zaman ortaya çıkan ilişki, birinci ilişkinin ikincide olmayan tüm demetlerini içerecektir, yani: r5(K) = r1(S)\r2(K) = {t(K) | t ∈ r1 & t ∉ r2}; Zaten iyi bilinen ilişkiler r1(S) ve r2(S), şuna benzeyen bir tablo görünümünde: r1(S):
r2(S):
İki ilişkinin kesişim işleminde her iki işleneni de ele alacağız. Ardından, bu tanımı takiben ortaya çıkan r5(S) ilişkisi şöyle görünecektir: r5(K) = r1(S)\r2(S):
Dikkate alınan ikili işlemler temeldir; diğer işlemler, daha karmaşık olanlar bunlara dayanır. 2. Kartezyen çarpım ve doğal birleştirme işlemleri Kartezyen çarpım işlemi ve doğal birleştirme işlemi, ürün türündeki ikili işlemlerdir ve daha önce tartıştığımız iki ilişki işleminin birleşimine dayanır. Kartezyen çarpım işleminin eylemi birçok kişiye tanıdık gelse de, ilk işlemden daha genel bir durum olduğu için yine de doğal ürün işlemiyle başlayacağız. Bu nedenle, doğal birleştirme işlemini düşünün. Bu eylemin işlenenlerinin, üç ikili birleştirme, kesişme ve yeniden adlandırma işleminin aksine, farklı şemalarla ilişkiler olabileceği hemen belirtilmelidir. Farklı ilişki şemalarına sahip iki ilişkiyi ele alırsak, r1(S1) ve r2(S2), sonra onlar doğal bileşik yeni bir ilişki olacak r3(S3), yalnızca ilişki şemalarının kesiştiği noktada eşleşen işlenen demetlerinden oluşacaktır. Buna göre, yeni ilişkinin şeması, orijinal ilişkilerin ilişki şemalarından herhangi birinden daha büyük olacaktır, çünkü bu onların bağlantısı, "yapıştırma". Bu arada, bu "yapıştırmanın" gerçekleştiğine göre iki işlenen ilişkisinde özdeş olan demetlere denir. bağlanabilir. Doğal birleştirme işleminin tanımını veritabanı yönetim sistemlerinin formül dilinde yazalım: r3(S3) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}; Doğal bir bağlantının çalışmasını, "yapıştırmasını" iyi gösteren bir örnek düşünelim. İki bağıntı r olsun1(S1) ve r2(S2), sırasıyla tablo şeklinde temsil edilir, eşittir: r1(S1):
r2(S2):
Bu ilişkilerin S şemalarının kesişiminde çakışan demetlere sahip olduğunu görüyoruz.1 ve S2 ilişkiler. Bunları sıralayalım: 1) r ilişkisinin {a, 1} demeti1(S1) r ilişkisinin {1, x} demetiyle eşleşir2(S2); 2) r'den {b, 1} demeti1(S1) ayrıca r'den {1, x} demetiyle de eşleşir2(S2); 3) {c, 3} tanımlama grubu, {3, z} tanımlama grubu ile aynıdır. Dolayısıyla, doğal birleşme altında, yeni ilişki r3(S3) tam olarak bu demetler üzerine "yapıştırma" ile elde edilir. yani r3(S3) bir tablo görünümünde şöyle görünecektir: r3(S3) = r1(S1)xr2(S2):
Tanım gereği ortaya çıkıyor: şema S3 şema S ile uyuşmuyor1, ne de şema S ile2, doğal birleşmelerini elde etmek için iki orijinal şemayı kesişen demetlerle "yapıştırdık". Doğal birleştirme işlemi uygulanırken demetlerin nasıl birleştirildiğini şematik olarak gösterelim. ilişki r olsun1 koşullu bir formu vardır:
ve r oranı2 - görüş:
O zaman doğal bağlantıları şöyle görünecek:
İlişki işlenenlerinin "yapıştırmasının", örneği göz önünde bulundurarak daha önce verdiğimiz şemaya göre gerçekleştiğini görüyoruz. Operasyon kartezyen bağlantı doğal birleştirme işleminin özel bir durumudur. Daha spesifik olarak, Kartezyen çarpım işleminin ilişkiler üzerindeki etkisini düşünürken, bu durumda sadece kesişmeyen ilişki şemalarından bahsedebileceğimizi kasten şart koşuyoruz. Her iki işlemin uygulanmasının bir sonucu olarak, işlenen ilişkileri şemalarının birleşimine eşit şemalarla ilişkiler elde edilir, işlenenlerin şemaları hiçbir durumda kesişmediğinden, yalnızca tüm olası demet çiftleri iki ilişkinin Kartezyen ürününe düşer. Böylece, yukarıdakilere dayanarak, Kartezyen çarpım işlemi için matematiksel bir formül yazıyoruz: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}, S1 ∩S2= ∅; Şimdi Kartezyen ürün işlemini uygularken ortaya çıkan ilişki şemasının nasıl görüneceğini gösteren bir örneğe bakalım. İki bağıntı r olsun1(S1) ve r2(S2), aşağıdaki gibi tablo şeklinde sunulmuştur: r1(S1):
r2(S2):
Böylece, r bağıntı demetlerinin hiçbirinin1(S1) ve r2(S2), gerçekten de kesişmelerinde çakışmaz. Bu nedenle, elde edilen bağıntıda r4(S4) birinci ve ikinci işlenen ilişkilerinin tüm olası demet çiftleri düşecektir. Almak: r4(S4) = r1(S1)xr2(S2):
Yeni bir ilişki şeması elde ettik r4(S4) önceki durumda olduğu gibi demetleri "yapıştırarak" değil, orijinal şemaların kesişiminde eşleşmeyen tüm olası farklı demet çiftlerinin numaralandırılmasıyla. Yine doğal birleştirme durumunda olduğu gibi, Kartezyen çarpım işleminin işleyişinin şematik bir örneğini veriyoruz. r olsun1 aşağıdaki gibi ayarlayın:
ve r oranı2 verilen:
Daha sonra Kartezyen çarpımı şematik olarak aşağıdaki gibi gösterilebilir:
Kartezyen çarpım işlemi uygulanırken ortaya çıkan bağıntı bu şekilde elde edilir. 3. İkili işlemlerin özellikleri Birleşim, kesişim, fark, Kartezyen çarpım ve doğal birleşme ikili işlemlerinin yukarıdaki tanımlarından, özellikler gelir. 1. Birinci özellik, tekli işlemlerde olduğu gibi, şunu gösterir: güç oranı ilişkiler: 1) birleştirme işlemi için: |r1 ∪r2| ≤ |r1| + |r2|; 2) kavşak işlemi için: |r1 ∩r2 | ≤ dk(|r1|, |r2|); 3) fark işlemi için: |r1 \r2| ≤ | r1|; 4) Kartezyen ürün işlemi için: |r1 xr2| = | r1| |r2|; 5) doğal birleştirme işlemi için: |r1 xr2| ≤ | r1| |r2|. Güçlerin oranı, hatırladığımız gibi, bir veya başka bir işlem uygulandıktan sonra ilişkilerdeki demet sayısının nasıl değiştiğini karakterize eder. Peki ne görüyoruz? Güç dernekler iki ilişki r1 ve r2 orijinal işlenen ilişkilerinin kardinalitelerinin toplamından daha az. Bu neden oluyor? Mesele şu ki, birleştirdiğinizde, eşleşen demetler birbiriyle örtüşerek kaybolur. Yani, bu işlemi yaptıktan sonra ele aldığımız örneğe bakarak, ilk ilişkide iki demet olduğunu, ikincide - üç ve sonuçta - dört, yani beşten az (toplamının) olduğunu görebilirsiniz. ilişkiler-işlenenlerin kardinaliteleri). Eşleşen tanımlama grubu {b, 2} ile bu ilişkiler "birbirine yapıştırılır". Sonuç gücü kavşaklar iki ilişki, orijinal işlenen ilişkilerinin minimum kardinalitesinden küçük veya ona eşittir. Bu işlemin tanımına dönelim: sadece her iki ilk ilişkide bulunan demetler sonuçtaki ilişkiye girer. Bu, yeni ilişkinin kardinalitesinin, demet sayısı ikisinden en küçüğü olan ilişki-işlenenin kardinalitesini geçemeyeceği anlamına gelir. Ve sonucun gücü bu minimum kardinaliteye eşit olabilir, çünkü daha düşük bir kardinaliteye sahip bir ilişkinin tüm demetleri, ikinci ilişki işleneninin bazı demetleriyle çakıştığında duruma her zaman izin verilir. operasyon durumunda farklılıklar her şey oldukça önemsiz. Gerçekten de, ikinci ilişkide de bulunan tüm demetler birinci ilişki işleneninden "çıkarılırsa", sayıları (ve dolayısıyla güçleri) azalacaktır. Birinci bağıntının tek bir demeti, ikinci ilişkinin herhangi bir demeti ile eşleşmediği takdirde, yani "çıkarılacak" bir şey yoksa, gücü azalmayacaktır. İlginçtir, eğer operasyon Kartezyen ürün ortaya çıkan ilişkinin gücü, iki işlenen ilişkisinin güçlerinin ürününe tam olarak eşittir. Bunun, orijinal ilişkilerin tüm olası demet çiftlerinin sonuca yazılması ve hiçbir şeyin hariç tutulmaması nedeniyle olduğu açıktır. Ve son olarak, operasyon doğal bağlantı kardinalitesi iki orijinal ilişkinin kardinalitelerinin çarpımına eşit veya daha büyük olan bir ilişki elde edilir. Yine bu, işlenen ilişkilerinin eşleşen demetler tarafından "yapıştırılması" ve eşleşmeyenlerin sonuçtan tamamen dışlanması nedeniyle olur. 2. Idempotency özelliği: 1) birleştirme işlemi için: r ∪ r = r; 2) kesişim işlemi için: r ∩ r = r; 3) fark işlemi için: r \ r ≠ r; 4) Kartezyen ürün işlemi için (genel durumda, özellik geçerli değildir); 5) doğal birleştirme işlemi için: r x r = r. İlginç bir şekilde, idempotency özelliği yukarıdaki işlemlerin tümü için doğru değildir ve Kartezyen çarpımının çalışması için hiç geçerli değildir. Gerçekten de, herhangi bir ilişkiyi kendisiyle birleştirir, kesişir veya doğal olarak bağlarsanız, bu değişmeyecektir. Ancak buna tam olarak eşit bir bağıntıdan çıkarırsanız, sonuç boş bir ilişki olacaktır. 3. Değişmeli özellik: 1) birleştirme işlemi için: r1 ∪r2 = r2 ∪r1; 2) kavşak işlemi için: r ∩ r = r ∩ r; 3) fark işlemi için: r1 \r2 ≠r2 \r1; 4) Kartezyen ürün işlemi için: r1 xr2 = r2 xr1; 5) doğal birleştirme işlemi için: r1 xr2 = r2 xr1. Değişebilirlik özelliği, fark işlemi dışındaki tüm işlemler için geçerlidir. Bunu anlamak kolaydır, çünkü bileşimleri (tupler) ilişkileri yer yer yeniden düzenlemekten değişmez. Ve fark işlemini uygularken, işlenen bağıntılardan hangisinin önce geldiği önemlidir, çünkü hangi bağıntının hangi kümelerin referans olarak alınacağına, yani diğer kümelerin dışlama için hangi kümelerle karşılaştırılacağına bağlıdır. 4. İlişkilendirme özelliği: 1) birleştirme işlemi için: (r1 ∪r2) ∪r3 = r1 ∪(r2 ∪r3); 2) kavşak işlemi için: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) fark işlemi için: (r1 \r2)\r3 ≠r1 \ (R2 \r3); 4) Kartezyen ürün işlemi için: (r1 xr2)xr3 = r1 x(r2 xr3); 5) doğal birleştirme işlemi için: (r1 xr2)xr3 = r1 x(r2 xr3). Ve yine özelliğin, fark işlemi dışındaki tüm işlemler için yürütüldüğünü görüyoruz. Bu, değişme özelliğinin uygulanması durumunda olduğu gibi açıklanır. Genel olarak, birleşim, kesişim, fark ve doğal birleştirme işlemleri, işlenen ilişkilerinin hangi sırada olduğu ile ilgilenmez. Ancak ilişkiler birbirinden "alındığında" düzen baskın bir rol oynar. Yukarıdaki özelliklere ve akıl yürütmeye dayanarak, şu sonuca varılabilir: son üç özellik, yani bağımsız olma, değişme ve birleşme özelliği, iki ilişkinin farkının işleyişi dışında, ele aldığımız tüm işlemler için doğrudur. belirtilen üç özelliğin hiçbirinin yerine getirilmediği ve yalnızca bir durumda özelliğin uygulanamaz olduğu tespit edildi. 4. Bağlantı işlemi seçenekleri Seçim, izdüşüm, yeniden adlandırma ve daha önce ele alınan birleşme, kesişim, fark, Kartezyen çarpım ve doğal birleştirmenin ikili işlemlerini temel alarak (hepsi genellikle denir) bağlantı işlemleri), yukarıdaki kavram ve tanımlar kullanılarak türetilen yeni işlemleri tanıtabiliriz. Bu aktiviteye derleme denir. birleştirme işlemi seçenekleri. Birleştirme işlemlerinin bu tür ilk varyantı, işlemdir. iç bağlantı Belirtilen bağlantı koşuluna göre. Bir iç birleştirmenin belirli bir koşulla çalışması, Kartezyen çarpım ve seçim işlemlerinden türev bir işlem olarak tanımlanır. Bu işlemin formül tanımını yazalım: r1(S1) X P r2(S2) = σ (r1 xr2), S1 ∩S2 = ∅; Burada P = P<S1 ∪S2> - orijinal ilişkiler-işlenenlerin iki şemasının birleştirilmesine dayatılan bir koşul. Bu koşulla, demetler r bağıntılarından seçilir.1 ve r2 ortaya çıkan ilişkiye girer. İç birleştirme işleminin farklı ilişki şemalarına sahip ilişkilere uygulanabileceğini unutmayın. Bu şemalar herhangi biri olabilir, ancak hiçbir durumda kesişmemelidir. İç birleştirme işleminin sonucu olan orijinal ilişki işlenenlerinin demetlerine denir. birleştirilebilir demetler. İç birleştirme işleminin işleyişini görsel olarak göstermek için aşağıdaki örneği vereceğiz. Bize iki bağıntı verilsin r1(S1) ve r2(S2) farklı ilişki şemaları ile: r1(S1):
r2(S2):
Aşağıdaki tablo, P = (b1 = b2) koşuluna iç birleştirme işleminin uygulanmasının sonucunu verecektir. r1(S1) X P r2(S2):
Dolayısıyla, ilişkileri temsil eden iki tablonun gerçekten de "yapışmasının", tam olarak P = (b1 = b2) iç birleştirme işleminin koşulunun yerine getirildiği demetlerde meydana geldiğini görüyoruz. Şimdi, daha önce tanıtılan iç birleştirme işlemine dayanarak, işlemi tanıtabiliriz. Sol dış katılma и sağ dış birleşim. Açıklayalım. Sol dış birleştirme işleminin sonucu, sol kaynak ilişkisi işleneninin birleştirilemeyen demetleri ile tamamlanan iç birleştirmenin sonucudur. Benzer şekilde, bir sağ dış birleştirme işleminin sonucu, sağ elini kullanan kaynak ilişki-işleneninin birleştirilemeyen demetleri ile genişletilmiş bir iç birleştirme işleminin sonucu olarak tanımlanır. Sol ve sağ dış birleşimlerin işlemlerinin sonucunda ortaya çıkan ilişkilerin nasıl yenileneceği sorusu oldukça bekleniyor. Bir ilişki işleneninin demetleri, başka bir ilişki işleneninin şeması üzerinde tamamlanır. boş değerler. Bu şekilde tanıtılan sol ve sağ dış birleştirme işlemlerinin, iç birleştirme işleminden türetilmiş işlemler olduğunu belirtmekte fayda var. Sol ve sağ dış birleştirme işlemleri için genel formülleri yazmak için bazı ek yapılar yapacağız. Bize iki bağıntı verilsin r1(S1) ve r2(S2) farklı ilişki şemaları ile S1 ve S2, birbirini kesmeyen. Sol ve sağ iç birleştirme işlemlerinin türev olduğunu zaten belirttiğimiz için, sol dış birleştirme işlemini belirlemek için aşağıdaki yardımcı formülleri elde edebiliriz: 1) r3 (S2 ∪S1) ≔r1(S1) X Pr2(S2); r 3 (S2 ∪S1) basitçe r ilişkilerinin iç birleşiminin sonucudur.1(S1) ve r2(S2). Sol dış birleştirme, iç birleştirmenin bir türev işlemidir, bu yüzden inşaatlarımıza onunla başlıyoruz; 2) r4(S1) ≔r 3(S2 ∪S1) [S1]; Böylece, bir tekli izdüşüm işleminin yardımıyla, sol ilk ilişki işleneni r'nin tüm birleştirilebilir demetlerini seçtik.1(S1). Sonuç r olarak belirlenir4(S1) kullanım kolaylığı için; 3) r5 (S1) ≔r1(S1)\r4(S1); burada r1(S1) tümü sol kaynak ilişkisi işleneninin demetleridir ve r4(S1) - kendi tuple'ları, yalnızca bağlı. Böylece, r'ye göre farkın ikili işlemi kullanılarak5(S1) sol işlenen ilişkisinin birleştirilemeyen tüm demetlerini aldık; 4) r6(S2)≔{∅(S2)}; {∅(S2)} şema (S) ile yeni bir ilişkidir.2) yalnızca bir demet içerir ve Null değerlerden oluşur. Kolaylık olması için bu oranı r olarak belirttik.6(S2); 5) r7 (S2 ∪S1) ≔r5(S1)xr6(S2); Burada sol işlenen ilişkisinin bağlantısız demetlerini aldık (r5(S1)) ve onları ikinci ilişki işleneni S'nin şemasına ekledi2 Boş değerler, yani Kartezyen, bu aynı birleştirilemeyen demetlerden oluşan ilişkiyi r ilişkisiyle çarpar.6(S2) dördüncü paragrafta tanımlanan; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪r7 (S2 ∪S1); Bu, Sol dış katılma, görülebileceği gibi, orijinal ilişkilerin-işlenenlerinin Kartezyen çarpımının birleşimiyle elde edilir r1 ve r2 ve ilişkiler r7 (S2 ∪ S1) XNUMX. paragrafta tanımlanmıştır. Şimdi sadece sol dış birleşimin çalışmasını değil, aynı zamanda analoji yoluyla da sağ dış birleşimin çalışmasını belirlemek için gerekli tüm hesaplamalara sahibiz. Yani: 1) operasyon Sol dış katılma katı biçimde şöyle görünür: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \ (R1 x P r2) [S1]) x {∅(S2)}]; 2) operasyon sağ dış birleşim sol dış birleştirme işlemine benzer şekilde tanımlanır ve aşağıdaki forma sahiptir: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \ (R1 x P r2) [S2]) x {∅(S1)}]; Bu iki türetilmiş işlemin bahsetmeye değer sadece iki özelliği vardır. 1. Değişebilirliğin özelliği: 1) sol dış birleştirme işlemi için: r1(S1) →x P r2(S2) ≠r2(S2) →x P r1(S1); 2) sağ dış birleştirme işlemi için: r1(S1) ←x P r2(S2) ≠r2(S2) ←x P r1(S1) Böylece, genel bir biçimde bu işlemler için değişme özelliğinin karşılanmadığını görüyoruz, ancak aynı zamanda sol ve sağ dış birleşimlerin işlemleri karşılıklı olarak birbirinin tersidir, yani aşağıdaki doğrudur: 1) sol dış birleştirme işlemi için: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) sağ dış birleştirme işlemi için: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. Sol ve sağ dış birleştirme işlemlerinin ana özelliği, yeniden belirli bir birleştirme işleminin nihai sonucuna göre ilk ilişki işleneni, yani aşağıdakiler gerçekleştirilir: 1) sol dış birleştirme işlemi için: r1(S1) = (r1 →x P r2) [S1]; 2) sağ dış birleştirme işlemi için: r2(S2) = (r1 ←x P r2) [S2]. Böylece, ilk orijinal ilişki işleneninin, sol-sağ birleştirme işleminin sonucundan ve daha spesifik olarak, bu birleştirmenin sonucuna (r) uygulanarak geri yüklenebileceğini görüyoruz.1 xr2) şema S üzerine tekli projeksiyon işlemi1,[S1]. Ve benzer şekilde, ikinci orijinal ilişki işleneni, sağ dış birleştirme (r) uygulanarak geri yüklenebilir.1 xr2) S ilişkisi şemasına projeksiyonun tekli işlemi2. Sol ve sağ dış birleşimlerin işlemlerinin işleyişini daha detaylı bir şekilde ele almak için bir örnek verelim. Zaten tanıdık ilişkileri tanıtalım r1(S1) ve r2(S2) farklı ilişki şemaları ile: r1(S1):
r2(S2):
Sol ilişki işleneni r'nin birleştirilemez demeti2(S2) bir tanımlama grubudur {d, 4}. Tanımı takiben, iki ilk ilişki işleneninin iç bağlantısının sonucunu tamamlaması gerekenler onlardır. r ilişkilerinin iç birleştirme koşulu1(S1) ve r2(S2) aynısını bırakıyoruz: P = (b1 = b2). Daha sonra işlemin sonucu Sol dış katılma aşağıdaki tablo olacaktır: r1(S1) →x P r2(S2):
Gerçekten de, görebildiğimiz gibi, sol dış birleştirme işleminin etkisinin bir sonucu olarak, iç birleştirme işleminin sonucu, solun birleştirilemeyen demetleriyle, yani bizim durumumuzda, ilk ilişki- ile dolduruldu. işlenen. Tanım olarak, ikinci (sağ) kaynak ilişki-işleneni şemasındaki demetin yenilenmesi, Boş değerlerin yardımıyla gerçekleşti. Ve sonuca benzer sağ dış birleşim öncekiyle aynı şekilde, orijinal ilişkiler-işlenenlerin r P = (b1 = b2) koşulu1(S1) ve r2(S2) aşağıdaki tablodur: r1(S1) ←x P r2(S2):
Gerçekten de, bu durumda, iç birleştirme işleminin sonucu, sağın birleştirilemeyen demetleri ile, bizim durumumuzda, ikinci ilk ilişki işleneni ile doldurulmalıdır. Böyle bir demet, görülmesi zor olmadığı için, ikinci bağıntıda r2(S2) bir, yani {2, y}. Daha sonra, sağ dış birleştirme işleminin tanımına göre hareket ederiz, ilk işlenenin şemasındaki ilk (sol) işlenenin demetini Boş değerlerle tamamlarız. Son olarak yukarıdaki birleştirme işlemlerinin üçüncü versiyonuna bakalım. Tam dış birleştirme işlemi. Bu işlem sadece iç birleştirme işlemlerinden türetilen bir işlem olarak değil, sol ve sağ dış birleştirme işlemlerinin birleşimi olarak da düşünülebilir. Tam dış birleştirme işlemi aynı iç birleştirmenin (sol ve sağ dış birleştirmelerin tanımı durumunda olduğu gibi) hem sol hem de sağ ilk işlenen ilişkilerinin birleştirilemeyen demetleri ile tamamlanmasının sonucu olarak tanımlanır. Bu tanıma dayanarak, bu tanımın formüler biçimini veriyoruz: r1(S1) ↔x P r2(S2) = (r1 →x P r2)∪(r1 ←x P r2); Tam dış birleştirme işlemi de sol ve sağ dış birleştirme işlemlerine benzer bir özelliğe sahiptir. Yalnızca tam dış birleştirme işleminin orijinal karşılıklı doğası nedeniyle (sonuçta, sol ve sağ dış birleştirme işlemlerinin birleşimi olarak tanımlandı), gerçekleştirir. değişme özelliği: r1(S1) ↔x P r2(S2)=r2(S2) ↔x P r1(S1); Ve birleştirme işlemleri için seçeneklerin değerlendirilmesini tamamlamak için, tam bir dış birleştirme işleminin çalışmasını gösteren bir örneğe bakalım. İki ilişki tanıtıyoruz r1(S1) ve r2(S2) ve birleştirme koşulu. Let r1(S1)
r2(S2):
Ve ilişkilerin bağlantı koşulu r olsun1(S1) ve r2(S2) olacaktır: P = (b1 = b2), önceki örneklerde olduğu gibi. Daha sonra r ilişkilerinin tam dış birleştirme işleminin sonucu1(S1) ve r2(S2) P = (b1 = b2) koşuluna göre aşağıdaki tablo olacaktır: r1(S1) ↔x P r2(S2):
Böylece, tam dış birleştirme işleminin, sol ve sağ dış birleştirme işlemlerinin sonuçlarının birleşimi olarak tanımını açıkça haklı çıkardığını görüyoruz. İç birleştirme işleminin ortaya çıkan ilişkisi, soldaki gibi aynı anda birleştirilemeyen demetlerle tamamlanır (ilk, r1(S1)) ve sağ (ikinci, r2(S2)) orijinal ilişki işleneninin. 5. Türev işlemler Bu nedenle, ilişkisel cebirin sekiz orijinal işleminin türevleri olan iç birleştirme, sol, sağ ve tam dış birleştirme işlemleri gibi çeşitli birleştirme işlemleri türevlerini düşündük: tekli seçme, yansıtma, yeniden adlandırma ve ikili işlemlerin ikili işlemleri. birleşim, kesişim, fark, Kartezyen çarpım ve doğal bağlantı. Ancak bu orijinal işlemler arasında bile türev işlemlerin örnekleri vardır. 1. Örneğin, operasyon kavşaklar iki oran, aynı iki oranın farkının işleminin bir türevidir. Hadi gösterelim. Kavşak işlemi aşağıdaki formülle ifade edilebilir: r1(S) ∩r2(K) = r1 \r1 \r2 veya aynı sonucu veren: r1(S) ∩r2(K) = r2 \r2 \r1; 2. Sekiz orijinal işlemden türetilen bir temel işlemin başka bir örneği, işlemdir. doğal bağlantı. En genel biçimiyle, bu işlem, Kartezyen çarpımının ikili işleminden ve niteliklerin seçilmesi, yansıtılması ve yeniden adlandırılmasının tekli işlemlerinden türetilir. Bununla birlikte, sırayla, iç birleştirme işlemi, ilişkilerin Kartezyen çarpımının aynı işleminin bir türev işlemidir. Bu nedenle, doğal birleştirme işleminin türev bir işlem olduğunu göstermek için aşağıdaki örneği göz önünde bulundurun. Doğal ve iç birleştirme işlemleri için önceki örnekleri karşılaştıralım. Bize iki bağıntı verilsin r1(S1) ve r2(S2) işlenenler olarak hareket edecek. Onlar eşit: r1(S1):
r2(S2):
Daha önce aldığımız gibi, bu ilişkilerin doğal birleştirme işleminin sonucu aşağıdaki biçimde bir tablo olacaktır: r3(S3) ≔r1(S1)xr2(S2):
Ve aynı ilişkilerin iç birleşiminin sonucu r1(S1) ve r2(S2) P = (b1 = b2) koşuluna göre aşağıdaki tablo olacaktır: r4(S4) ≔r1(S1) X P r2(S2):
Bu iki sonucu karşılaştıralım, ortaya çıkan yeni ilişkiler r3(S3) ve r4(S4). Doğal birleştirme işleminin iç birleştirme işlemi ile ifade edildiği açıktır, ancak en önemlisi, özel bir formda birleştirme koşulu ile. Doğal birleştirme işleminin eylemini iç birleştirme işleminin bir türevi olarak tanımlayan bir matematiksel formül yazalım. r1(S1)xr2(S2) = { ρ<ϕ1>r1 x E ρ<ϕ2>r2}[S1 ∪S2], nerede E - bağlantı durumu demetler; E= ∀a ∈S1 ∩S2 [IsNull(b1) & IsNull(2) ∪b1 = b2]; b1 = ϕ1 (isim(a)), b2 = ϕ2 (isim(a)); İşte bunlardan biri işlevleri yeniden adlandırma ϕ1 aynıdır ve başka bir yeniden adlandırma işlevi (yani, ϕ2) şemalarımızın kesiştiği özellikleri yeniden adlandırır. Demetler için E bağlantı koşulu, Null değerlerinin olası oluşumu dikkate alınarak genel bir biçimde yazılır, çünkü iç birleştirme işlemi (yukarıda bahsedildiği gibi) iki ilişkinin Kartezyen çarpımının işleminden türev bir işlemdir ve tekli seçim işlemi. 6. İlişkisel cebirin ifadeleri Daha önce ele alınan ilişkisel cebirin ifade ve işlemlerinin çeşitli veritabanlarının pratik işlemlerinde nasıl kullanılabileceğini gösterelim. Örneğin, bazı ticari veritabanlarının bir parçası elimizde olsun: Tedarikçiler (Tedarikçi kodu, Satıcı adı, Satıcı şehri); Aletler (Araç kodu, Araç adı,...); Teslimatlar (Tedarikçi kodu, Parça kodu); Altı çizili nitelik adları[1], her biri kendi ilişkisi içinde olan anahtar (yani tanımlayıcı) niteliklerdir. Bu veritabanının geliştiricileri ve bu konudaki bilgilerin sorumluları olarak, bu tedarikçilerin herhangi bir araç tedarik etmemesi durumunda, tedarikçilerin adlarını (Tedarikçi Adı) ve konumlarını (Tedarikçi Şehri) almamız emredildiğini varsayalım. genel bir isim "Pliers". Muhtemelen çok büyük veritabanımızda bu gereksinimi karşılayan tüm tedarikçileri belirlemek için birkaç ilişkisel cebir ifadesi yazıyoruz. 1. Her bir tedarikçi ile kendisi tarafından sağlanan parçaların kodlarını eşleştirmek için "Tedarikçiler" ve "Malzemeler" ilişkilerinin doğal bir bağlantısını oluşturuyoruz. Yeni ilişki - doğal birleştirme işleminin uygulanmasının sonucu - daha fazla uygulama kolaylığı için, r ile gösterilir.1. Tedarikçiler x Sarf Malzemeleri ≔ r1 (Tedarikçi Kodu, Tedarikçi Adı, Tedarikçi Şehri, Bu doğal birleştirme işleminde yer alan ilişkilerin tüm özelliklerini parantez içinde listeledik. "Satıcı Kimliği" özniteliğinin yinelendiğini görebiliriz, ancak işlem özet kaydında her öznitelik adı yalnızca bir kez görünmelidir, yani: Tedarikçiler x Sarf Malzemeleri ≔ r1 (Tedarikçi kodu, Tedarikçi adı, Tedarikçi şehri, Cihaz kodu); 2. Yine doğal bir bağlantı oluşturuyoruz, ancak bu sefer birinci paragrafta elde edilen ilişki ve Araçlar ilişkisi. Bunu, bu aracın adını önceki paragrafta elde edilen her bir araç koduyla eşleştirmek için yapıyoruz. r1 x Araçlar [Takım Kodu, Takım Adı] ≔ r2 (Tedarikçi Kodu, Tedarikçi Adı, Tedarikçi Şehri, Ortaya çıkan sonuç r ile gösterilecektir.2, yinelenen özellikler hariç tutulur: r1 x Araçlar [Takım Kodu, Takım Adı] ≔ r2 (Tedarikçi kodu, Tedarikçi adı, Tedarikçi şehri, Cihaz kodu, Cihaz adı); Araçlar ilişkisinden yalnızca iki öznitelik aldığımızı unutmayın: "Araç Kodu" ve "Araç Adı". Bunu yapmak için, r bağıntısının gösteriminden de görülebileceği gibi,2, tekli projeksiyon işlemini uyguladı: Araçlar [Araç kodu, Araç adı], yani ilişki Araçlar bir tablo şeklinde sunulduysa, bu projeksiyon işleminin sonucu "Araç kodu" başlıklı ilk iki sütun olacaktır. ve "Araç adı" sırasıyla ". Daha önce ele aldığımız ilk iki adımın oldukça genel olduğunu, yani diğer istekleri uygulamak için kullanılabileceğini belirtmek ilginçtir. Ancak sonraki iki nokta, önümüze konulan belirli görevi başarmak için somut adımları temsil ediyor. 3. r oranına göre <"Tool name" = "Pliers"> koşuluna göre bir tekli seçim işlemi yazın2önceki paragrafta elde edilmiştir. Biz de sırasıyla bu özniteliklerin tüm değerlerini elde etmek için bu işlemin sonucuna tekli projeksiyon işlemini [Tedarikçi Kodu, Tedarikçi Adı, Tedarikçi Şehri] uyguluyoruz, çünkü bu bilgiyi esas alarak almamız gerekiyor. emir. Yani: (σ<Alet adı = "Pliers"> r2) [Tedarikçi Kodu, Tedarikçi Adı, Tedarikçi Şehri] ≔ r3 (Tedarikçi kodu, Tedarikçi adı, Tedarikçi şehri, Takım kodu, Takım adı). Ortaya çıkan oranda, r ile gösterilir3, yalnızca bu tedarikçilerin (tüm tanımlama verileriyle birlikte) "Pliers" jenerik adıyla araçlar tedarik ettiği ortaya çıktı. Ancak sipariş nedeniyle, tam tersine bu tür araçları tedarik etmeyen tedarikçileri ayırmamız gerekiyor. Bu nedenle, algoritmamızın bir sonraki adımına geçelim ve aradığımız bilgiyi bize verecek olan son ilişkisel cebir ifadesini yazalım. 4. İlk olarak, "Tedarikçiler" ilişkisi ile r ilişkisi arasındaki farkı yaratırız.3, ve bu ikili işlemi uyguladıktan sonra "Tedarikçi Adı" ve "Tedarikçi Şehri" öznitelikleri üzerinde tekli projeksiyon işlemini uyguluyoruz. (Tedarikçiler\r3) [Tedarikçi Adı, Tedarikçi Şehri] ≔ r4 (Tedarikçi kodu, Tedarikçi adı, Tedarikçi şehri); Sonuç r olarak belirlenir4, bu ilişki yalnızca orijinal "Tedarikçiler" ilişkisinin düzenimizin durumuna karşılık gelen demetlerini içeriyordu. Böylece, ilişkisel cebirin ifadeleri ve işlemlerini kullanarak, her türlü işlemi keyfi veritabanları ile nasıl gerçekleştirebileceğinizi, çeşitli siparişleri gerçekleştirebileceğinizi vb. gösterdik. Ders No. 6. SQL dili Önce biraz tarihsel arka plan verelim. Veritabanlarıyla etkileşim kurmak için tasarlanan SQL dili 1970'lerin ortalarında ortaya çıktı. (ilk yayınlar 1974 yılına kadar uzanır) ve deneysel bir ilişkisel veritabanı yönetim sistemi projesinin parçası olarak IBM tarafından geliştirilmiştir. Dilin orijinal adı SEQUEL'dir (Structured English Sorgu Dili) - bu dilin özünü yalnızca kısmen yansıttı. Başlangıçta, icadından hemen sonra ve SQL dilinin birincil çalışma döneminde adı, "Yapılandırılmış Sorgu Dili" olarak tercüme edilen Yapılandırılmış Sorgu Dili ifadesinin kısaltmasıydı. Tabii ki, dil esas olarak, kullanıcılar için uygun ve anlaşılır olan ilişkisel veritabanlarına yönelik sorguların formüle edilmesine odaklandı. Ama aslında, neredeyse en başından beri, sorguları formüle etme ve veritabanlarını manipüle etme araçlarına ek olarak aşağıdaki özellikleri sağlayan eksiksiz bir veritabanı diliydi: 1) veritabanı şemasını tanımlama ve manipüle etme araçları; 2) bütünlük kısıtlamalarını ve tetikleyicileri (daha sonra bahsedilecektir) tanımlama araçları; 3) veritabanı görünümlerini tanımlama araçları; 4) isteklerin verimli bir şekilde yürütülmesini destekleyen fiziksel katman yapılarını tanımlama araçları; 5) ilişkilere ve alanlarına erişime izin verme araçları. Dil, paralel işlemler tarafından veritabanı nesnelerine erişimi açıkça senkronize etme araçlarından yoksundu: en başından beri, gerekli senkronizasyonun veritabanı yönetim sistemi tarafından örtülü olarak gerçekleştirildiği varsayıldı. Şu anda SQL artık bir kısaltma değil, bağımsız bir dilin adıdır. Ayrıca, şu anda yapılandırılmış sorgu dili, tüm ticari ilişkisel veritabanı yönetim sistemlerinde ve başlangıçta ilişkisel bir yaklaşıma dayanmayan neredeyse tüm VTYS'lerde uygulanmaktadır. Tüm üretim şirketleri, uygulamalarının SQL standardına uygun olduğunu iddia eder ve aslında Yapılandırılmış Sorgu Dilinin uygulanan lehçeleri çok yakındır. Bu hemen sağlanmadı. Çoğu modern ticari veritabanı yönetim sisteminin mevcut SQL lehçelerini karşılaştırmayı zorlaştıran bir özelliği, dilin tek tip bir tanımının olmamasıdır. Tipik olarak, açıklama çeşitli kılavuzlara dağılmıştır ve yapılandırılmış sorgu diliyle doğrudan ilgili olmayan sisteme özgü dil özelliklerinin bir açıklaması ile karıştırılmıştır. Bununla birlikte, veritabanı şemasını belirleme, veri alma ve işleme, veri erişimine izin verme, SQL'i programlama dillerine gömme desteği ve dinamik SQL ifadeleri içeren ifadeleri içeren temel SQL ifadeleri setinin iyi kurulmuş olduğu söylenebilir. ticari uygulamalar ve az çok standarda uygundur. Zaman içinde ve Structured Query Language üzerinde çalışarak, veri alma ifadelerinin sözdiziminin ve semantiğinin net bir standardizasyonu, veri manipülasyonu ve veritabanı bütünlüğü kısıtlamalarının düzeltilmesi için bir standart elde etmek mümkün olmuştur. İlişkilerin birincil ve yabancı anahtarlarını ve hemen kontrol edilen SQL bütünlük kısıtlamalarının bir alt kümesi olan bütünlük denetimi kısıtlamaları olarak adlandırılan araçları tanımlamak için araçlar belirtilmiştir. Yabancı anahtarları tanımlama araçları, veritabanlarının (daha sonra bahsedeceğimiz) sözde referans bütünlüğünün gereksinimlerini formüle etmeyi kolaylaştırır. İlişkisel veritabanlarında yaygın olan bu gereksinim, SQL bütünlük kısıtlamalarının genel mekanizması temelinde de formüle edilebilir, ancak yabancı anahtar kavramına dayalı formülasyon daha basit ve daha anlaşılırdır. Dolayısıyla, tüm bunlar dikkate alındığında, şu anda yapılandırılmış sorgu dili yalnızca bir dilin adı değil, tüm bir dil sınıfının adıdır, çünkü mevcut standartlara rağmen, yapılandırılmış sorgu dilinin çeşitli lehçeleri uygulanmaktadır. elbette ortak bir temeli olan çeşitli veritabanı yönetim sistemlerinde. 1. Select ifadesi, Yapılandırılmış Sorgu Dilinin temel ifadesidir. SQL yapılandırılmış sorgu dilindeki merkezi yer, veritabanlarıyla çalışırken en çok talep edilen işlemi - sorguları uygulayan Select ifadesi tarafından işgal edilir. Select ifadesi hem ilişkisel hem de sözde ilişkisel cebir ifadelerini değerlendirir. Bu kursta, daha önce ele aldığımız ilişkisel cebirin yalnızca tekli ve ikili işlemlerinin uygulanmasını ve ayrıca alt sorgular olarak adlandırılan sorguların uygulanmasını ele alacağız. Bu arada, ilişkisel cebir işlemleriyle çalışılması durumunda, ortaya çıkan ilişkilerde yinelenen demetlerin görünebileceği belirtilmelidir. Yapılandırılmış sorgu dilinin kurallarında (sıradan ilişkisel cebirin aksine) ilişkilerde yinelenen satırların bulunmasına karşı kesin bir yasak yoktur, bu nedenle yinelenenleri sonuçtan çıkarmak gerekli değildir. Şimdi Select ifadesinin temel yapısına bakalım. Oldukça basittir ve aşağıdaki standart zorunlu ifadeleri içerir: Seç ... Şu ... Nerede... ; Her satırdaki üç nokta yerine, belirli bir veritabanının ilişkileri, nitelikleri ve koşulları ve bunun için görevler olmalıdır. En genel durumda, temel Select yapısı şöyle görünmelidir: seç bazı özellikleri seçin Konum böyle bir ilişkiden Nerede örnekleme demetleri için böyle ve böyle koşullarla Bu nedenle, hangi ilişkilerden (ve görünüşe göre birkaç tane olabilir) seçimimizi yaptığımızı ve son olarak, seçimimizi hangi koşullarda durdurduğumuzu belirtirken, ilişki şemasından (bazı sütunların başlıkları) nitelikler seçeriz. belirli tuple'lar. Öznitelik referanslarının isimleri kullanılarak yapıldığına dikkat etmek önemlidir. Böylece, aşağıdakiler elde edilir iş algoritması bu temel Select ifadesi: 1) ilişkiden demet seçme koşulları hatırlanır; 2) Hangi tuple'ların belirtilen özellikleri sağladığı kontrol edilir. Bu tür demetler hatırlanır; 3) Select deyiminin temel yapısının ilk satırında listelenen öznitelikler değerleri ile birlikte çıktılanır. (İlişkinin tablo biçiminden bahsedersek, başlıkları gerekli nitelikler olarak listelenen tablonun bu sütunları görüntülenecektir; elbette, sütunlar tamamen görüntülenmeyecek, her birinde yalnızca bu demetler belirtilen koşulları karşılayan kalacaktır.) Bir örneği düşünün. Bize aşağıdaki r bağıntısı verilsin1, bazı kitapçı veritabanının bir parçası olarak:
Select deyimi ile birlikte şu ifadeyi de verelim: seç Kitabın Adı, Kitabın Yazarı Konum r1 Nerede Kitap fiyatı > 200; Bu operatörün sonucu aşağıdaki demet parçası olacaktır: (Cep telefonu, S. King). (İleride, bu temel yapıyı kullanan birçok sorgu uygulaması örneğini ele alacağız ve uygulamasını ayrıntılı olarak inceleyeceğiz.) 2. Yapılandırılmış sorguların dilinde tekli işlemler Bu bölümde, zaten bilinen tekli seçme, yansıtma ve yeniden adlandırma işlemlerinin Select operatörü kullanılarak yapılandırılmış sorgu dilinde nasıl uygulandığını ele alacağız. Daha önce sadece bireysel işlemlerle çalışabiliyor olsaydık, genel durumda tek bir Select deyimi bile tek bir işlemi değil tüm bir ilişkisel cebir ifadesini tanımlamamıza izin verir. Öyleyse doğrudan tekli işlemlerin yapısal sorgular dilinde temsilinin analizine geçelim. 1. Örnekleme işlemi. SQL'deki seçim işlemi, aşağıdaki formun Select ifadesi tarafından uygulanır: seç tüm nitelikler Konum ilişki adı Nerede seçim koşulu; Burada "tüm nitelikler" yazmak yerine "*" işaretini kullanabilirsiniz. Yapılandırılmış sorgu dili teorisinde bu simge, ilişki şemasından tüm öznitelikleri seçmek anlamına gelir. Buradaki seçim koşulu (ve diğer tüm işlem uygulamalarında), (değil) ve (ve) veya (veya) olmayan standart bağlaçlarla mantıksal bir ifade olarak yazılır. İlişki nitelikleri isimleriyle anılır. Bir örnek düşünün. Aşağıdaki ilişki şemasını tanımlayalım: akademik performans (Not defteri numarası, Sömestr, Ders kodu, Derecelendirme, Tarih); Burada, daha önce belirtildiği gibi, altı çizili nitelikler ilişki anahtarını oluşturur. Tekli seçim işlemini uygulayan aşağıdaki formda bir Select ifadesi oluşturalım: Seç * Akademik performanstan Not Defteri # = 100 ve Dönem = 6 olduğunda; Bu operatörün sonucunda makinenin altıncı yarıyıl için yüz kayıt sayısı ile öğrencinin ilerlemesini göstereceği açıktır. 2. Projeksiyon işlemi. Yapılandırılmış Sorgu Dili'ndeki projeksiyon işleminin uygulanması, getirme işleminden bile daha kolaydır. Yansıtma işlemini uygularken satırların değil (seçim işlemini uygularken olduğu gibi) sütunların seçildiğini hatırlayın. Bu nedenle, herhangi bir dış koşul belirtmeden, gerekli sütunların (yani nitelik adlarının) başlıklarını listelemek yeterlidir. Toplamda, aşağıdaki biçimde bir operatör elde ederiz: seç özellik isimleri listesi Konum ilişki adı; Bu ifadeyi uyguladıktan sonra, makine, bu Select ifadesinin ilk satırında isimleri belirtilen ilişki tablosunun sütunlarını döndürür. Daha önce de belirttiğimiz gibi, yinelenen satırları ve sütunları sonuçtaki ilişkiden çıkarmak gerekli değildir. Ancak bir siparişte veya görevde yinelenenleri ortadan kaldırmak gerekiyorsa, yapılandırılmış sorgu dilinin özel bir seçeneğini kullanmalısınız - farklı. Bu seçenek, ilişkiden yinelenen tanımlama gruplarının otomatik olarak ortadan kaldırılmasını ayarlar. Bu seçenek uygulandığında Select ifadesi şu şekilde görünecektir: seç öznitelik adlarının ayrı listesi Konum ilişki adı; SQL'de, ifadelerin isteğe bağlı öğeleri için özel bir gösterim vardır - köşeli parantezler [...]. Bu nedenle, en genel haliyle projeksiyon işlemi şu şekilde görünecektir: seç [farklı] nitelik adlarının listesi Konum ilişki adı; Ancak, işlemin uygulanmasının sonucunun kopya içermemesi garanti ediliyorsa veya yinelemeler hala kabul edilebilirse, o zaman seçenek farklı kaydı karıştırmamak için, yani operatör performansı nedeniyle belirtmemek daha iyidir. Yinelemelerin yokluğunda %XNUMX güven olasılığını gösteren bir örnek düşünelim. Bize zaten bilinen ilişkilerin şemasını verelim: akademik performans (Not defteri numarası, Sömestr, Ders kodu, Derecelendirme, Tarih). Aşağıdaki Select ifadesinin verilmesine izin verin: seç Not defteri numarası, Sömestr, Ders kodu Konum akademik performans; Burada, operatör tarafından döndürülen üç özelliğin ilişkinin anahtarını oluşturduğunu görmek kolaydır. Bu yüzden seçenek farklı gereksiz hale gelir, çünkü hiçbir kopya olmayacağı garanti edilir. Bu, benzersiz bir kısıtlama adı verilen anahtarlar için bir gereksinimden kaynaklanır. Bu özelliği daha sonra daha ayrıntılı olarak ele alacağız, ancak öznitelik anahtar ise, içinde kopya yoktur. 3. İşlemi yeniden adlandırın. Yapılandırılmış sorgu dilinde öznitelikleri yeniden adlandırma işlemi oldukça basittir. Yani, gerçekte aşağıdaki algoritma ile somutlaştırılmıştır: 1) Select ifadesinin öznitelik adları listesinde, yeniden adlandırılması gereken öznitelikler listelenir; 2) belirtilen her bir özniteliğe eklenen özel anahtar kelime; 3) as kelimesinin her oluşumundan sonra, orijinal adın değiştirilmesi gereken ilgili özelliğin adı belirtilir. Böylece, yukarıdakilerin tümü dikkate alındığında, niteliklerin yeniden adlandırılması işlemine karşılık gelen ifade şöyle görünecektir: seç özellik adı 1, yeni özellik adı 1 olarak... Konum ilişki adı; Bu operatörün nasıl çalıştığını bir örnekle gösterelim. Bize zaten tanıdık olan ilişki şemasını verelim: akademik performans (Not defteri numarası, Sömestr, Ders kodu,Derecelendirme, Tarih); Bazı özniteliklerin isimlerini değiştirmek için bir sıralama yapalım, yani "Hesap defteri numarası" yerine "Hesap numarası" ve "Puan" - "Puan" yerine "Hesap numarası" olmalıdır. Bu yeniden adlandırma işlemini uygulayan Select ifadesinin nasıl görüneceğini yazalım: seç Not Defteri numarası olarak Not Defteri, Dönem, Konu kodu, Puan olarak Not, Tarih Konum akademik performans; Böylece, bu operatörün uygulanmasının sonucu, iki öznitelik adına orijinal "Başarı" ilişki şemasından farklı olan yeni bir ilişki şeması olacaktır. 3. Yapılandırılmış sorguların dilinde ikili işlemler Tekli işlemler gibi, ikili işlemler de yapılandırılmış sorgu dilinde veya SQL'de kendi uygulamalarına sahiptir. Öyleyse, daha önce geçtiğimiz ikili işlemlerin, yani birleşim, kesişim, fark, Kartezyen çarpım, doğal birleştirme, iç ve sol, sağ, tam dış birleşim işlemlerinin bu dilde uygulamasını ele alalım. 1. Birlik operasyonu. İki ilişkiyi birleştirme işlemini uygulamak için, her biri orijinal ilişkiler işlenenlerinden birine karşılık gelen iki Select operatörünü aynı anda kullanmak gerekir. Ve bu iki temel Select ifadesine özel bir işlem uygulanmalıdır. sendika. Yukarıdakilerin hepsini göz önünde bulundurarak, yapılandırılmış sorgu dilinin semantiğini kullanarak union işleminin nasıl görüneceğini yazalım: seç 1. ilişkinin nitelik adlarını listele Konum ilişki adı 1 sendika seç 2. ilişkinin nitelik adlarını listele Konum ilişki adı 2; Birleştirilen iki ilişkinin öznitelik adlarının listelerinin, uyumlu türlerin özniteliklerine başvurması ve tutarlı bir sırada listelenmesi gerektiğine dikkat etmek önemlidir. Bu gereksinim karşılanmazsa isteğiniz yerine getirilemez ve bilgisayar bir hata mesajı görüntüler. Ancak ilginç olan, bu ilişkilerde özniteliklerin adlarının farklı olabileceğidir. Bu durumda, ortaya çıkan ilişkiye ilk Select deyiminde belirtilen öznitelik adları atanır. Ayrıca, Birleştirme işlemini kullanmanın, tüm yinelenen demetleri sonuçtaki ilişkiden otomatik olarak hariç tuttuğunu bilmeniz gerekir. Bu nedenle, sonuçta tüm yinelenen satırların korunmasına ihtiyacınız varsa, Union işlemi yerine, bu işlemin bir modifikasyonunu kullanmalısınız - işlem Birlik Tümü. Bu durumda, iki ilişkiyi birleştirme işlemi şöyle görünecektir: seç 1. ilişkinin nitelik adlarını listele Konum ilişki adı 1 Birlik Tümü seç 2. ilişkinin nitelik adlarını listele Konum ilişki adı 2; Bu durumda, yinelenen demetler sonuçtaki ilişkiden çıkarılmayacaktır. Select deyimlerinde isteğe bağlı öğeler ve seçenekler için daha önce bahsedilen gösterimi kullanarak, yapılandırılmış sorgu dilinde iki ilişkiyi birleştirme işleminin en genel biçimini yazıyoruz: seç 1. ilişkinin nitelik adlarını listele Konum ilişki adı 1 Birlik [Tümü] seç 2. ilişkinin nitelik adlarını listele Konum ilişki adı 2; 2. Kavşak işlemi. Yapılandırılmış sorgu dilinde kesişim işlemi ve iki ilişkinin farkının işlemi benzer şekilde uygulanır (en basit temsil yöntemini düşünüyoruz, çünkü yöntem ne kadar basitse, o kadar ekonomik, daha alakalı ve bu nedenle en aranılan). Bu nedenle, kullanarak kavşak işlemini gerçekleştirmenin yolunu analiz edeceğiz. Anahtarların. Bu yöntem, iki Select yapısının katılımını içerir, ancak bunlar eşit değildir (birleşim işleminin temsilinde olduğu gibi), bunlardan biri deyim yerindeyse bir "alt yapı", "alt döngü"dür. Böyle bir operatör genellikle denir alt sorgu. Diyelim ki iki ilişki şemamız var (R1 ve R2), kabaca şu şekilde tanımlanır: R1 (anahtar,...) ve R2 (anahtar,...); Bu işlemi kaydederken özel seçeneği de kullanacağız. in, kelimenin tam anlamıyla "içinde" veya (bu özel durumda olduğu gibi) "içerilir" anlamına gelir. Dolayısıyla yukarıdakilerin tümü dikkate alınarak yapılandırılmış sorgu dili kullanılarak iki ilişkinin kesişim işlemi şu şekilde yazılacaktır: seç * Konum R1 Nerede veri girişi (seç ключ R'den2); Böylece, bu durumda alt sorgunun parantez içindeki operatör olacağını görüyoruz. Bizim durumumuzda bu alt sorgu, R ilişkisinin anahtar değerlerinin bir listesini döndürür.2. Ve, operatörlerin gösteriminden, seçim koşulunun analizinden aşağıdaki gibi, yalnızca R ilişkisinin demetleri sonuçtaki ilişkiye düşecektir.1, anahtarı R ilişkisinin anahtarları listesinde bulunan2. Yani, son bağıntıda, iki ilişkinin kesişim tanımını hatırlayacak olursak, yalnızca her iki ilişkiye ait olan demetler kalacaktır. 3. Fark işlemi. Daha önce belirtildiği gibi, iki ilişkinin farkının tekli işlemi, kesişme işlemine benzer şekilde uygulanır. Burada, Select operatörlü ana sorguya ek olarak, ikinci bir yardımcı sorgu kullanılır - sözde alt sorgu. Ancak önceki işlemin uygulanmasından farklı olarak, fark işlemini uygularken başka bir anahtar kelime kullanmak gerekir, yani değil, kelimenin tam anlamıyla çevirisi "içinde değil" veya (düşünmekte olduğumuz durumumuzda tercüme edilmesi uygun olduğu gibi) - "içerilmemektedir" anlamına gelir. Öyleyse, önceki örnekte olduğu gibi iki ilişki şemamız olsun (R1 ve R2), yaklaşık olarak şu şekilde verilir: R1 (anahtar,...) ve R2 (anahtar,...); Gördüğünüz gibi, anahtar nitelikler yine bu ilişkilerin nitelikleri arasında yer almaktadır. Böylece, yapılandırılmış sorgu dilinde fark işlemini temsil etmek için aşağıdaki formu elde ederiz: Seç * Konum R1 Nerede ключ değil (seç ключ Konum R2); Böylece, yalnızca R ilişkisinin demetleri1, anahtarı R ilişkisinin anahtarları listesinde yer almayan2. Notasyonu kelimenin tam anlamıyla düşünürsek, o zaman gerçekten R bağıntısından ortaya çıkıyor.1 R oranı "çıkarıldı"2. Buradan, bu operatördeki seçim koşulunun doğru yazıldığı (sonuçta, iki ilişkinin farkının tanımının yapıldığı) ve kesişme işleminin uygulanması durumunda olduğu gibi tuşların kullanımının tamamen doğrulandığı sonucuna varıyoruz. . Gördüğümüz "anahtar yönteminin" iki kullanımı en yaygın olanlarıdır. Bu, ilişkileri temsil eden operatörlerin yapımında anahtarların kullanımına ilişkin çalışmayı sonuçlandırmaktadır. İlişkisel cebirin kalan tüm ikili işlemleri başka şekillerde yazılır. 4. Kartezyen ürün işlemi Önceki derslerden hatırladığımız gibi, iki ilişki işleneninin Kartezyen ürünü, nitelikler üzerindeki tüm olası adlandırılmış değer çiftlerinin bir kümesi olarak oluşur. Bu nedenle, yapılandırılmış sorgu dilinde, Kartezyen ürün işlemi, anahtar kelime ile gösterilen bir çapraz birleştirme kullanılarak uygulanır. çapraz birleştirme, kelimenin tam anlamıyla "çapraz birleştirme" veya "çapraz birleştirme" anlamına gelir. Yapılandırılmış Sorgu Dili'nde Kartezyen ürün işlemini temsil eden yapıda yalnızca bir Seç operatörü vardır ve aşağıdaki forma sahiptir: Seç * Konum R1 çapraz birleştirme R2 İşte r1 ve R2 - ilk ilişkilerin-işlenenlerin isimleri. Seçenek çapraz birleştirme sonuçtaki ilişkinin tüm nitelikleri (hepsi, çünkü operatörün ilk satırında "*" işareti vardır) tüm ilişki demetleri çiftlerine karşılık gelen içermesini sağlar.1 ve R2. Kartezyen ürün işleminin uygulanmasının bir özelliğini hatırlamak çok önemlidir. Bu özellik, Kartezyen çarpımının ikili işleminin tanımının bir sonucudur. Hatırlayın: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈r1 &t(S2) ∈r2}, S1 ∩S2= ∅; Yukarıdaki tanımdan da görülebileceği gibi, demet çiftleri, zorunlu olarak kesişmeyen ilişki şemaları ile oluşturulur. Bu nedenle, SQL yapılandırılmış sorgu dilinde çalışırken, ilk işlenen ilişkilerinin eşleşen öznitelik adlarına sahip olmaması her zaman şart koşulmuştur. Ancak bu ilişkiler hala aynı isimlere sahipse, öznitelik yeniden adlandırma işlemi kullanılarak mevcut durum kolayca çözülebilir, yani bu gibi durumlarda, seçeneği kullanmanız yeterlidir. as, daha önce bahsedilen. Aynı öznitelik adlarından bazılarına sahip iki ilişkinin Kartezyen çarpımını bulmamız gereken bir örneği ele alalım. Yani, aşağıdaki ilişkiler göz önüne alındığında: R1 (A, B), R2 (M.Ö); R özelliklerinin olduğunu görüyoruz.1.B ve R2.B aynı isimlere sahiptir. Bunu akılda tutarak, bu Kartezyen ürün işlemini yapılandırılmış sorgu dilinde uygulayan Select ifadesi şöyle görünecektir: seç bir, R1.B as B1, Sağ2.B as B2, Ç Konum R1 çapraz birleştirme R2; Bu nedenle, yeniden adlandırma seçeneğini farklı kullanarak, makinenin iki orijinal işlenen ilişkisinin eşleşen adları hakkında "soruları" olmayacaktır. 5. İç birleştirme işlemleri İlk bakışta, doğal birleştirme işleminden önce iç birleştirme işlemini ele almamız garip görünebilir, çünkü ikili işlemlerden geçtiğimizde her şey tam tersiydi. Ancak, yapılandırılmış sorgu dilindeki işlemlerin ifadesini analiz ederek, doğal birleştirme işleminin iç birleştirme işleminin özel bir durumu olduğu sonucuna varılabilir. Bu nedenle bu işlemleri bu sırayla ele almak mantıklıdır. O halde önce, daha önce üzerinden geçtiğimiz iç birleştirme işleminin tanımını hatırlayalım: r1(S1) X P r2(S2) = σ (r1 xr2), S1 ∩ S2 = ∅. Bizim için, bu tanımda, dikkate alınan ilişki-işlenen S şemalarının özellikle önemlidir.1 ve S2 kesişmemelidir. Yapılandırılmış sorgu dilinde iç birleştirme işlemini uygulamak için özel bir seçenek vardır. iç birleşim, kelimenin tam anlamıyla İngilizce'den "iç birleştirme" veya "iç birleştirme" olarak çevrilmiştir. Bir iç birleştirme işlemi durumunda Select ifadesi şöyle görünecektir: Seç * Konum R1 iç birleşim R2; Burada, daha önce olduğu gibi, R1 ve R2 - ilk ilişkilerin-işlenenlerin isimleri. Bu işlemi uygularken, ilişki işlenenlerinin şemalarının geçmesine izin verilmemelidir. 6. Doğal birleştirme işlemi Daha önce de söylediğimiz gibi doğal birleştirme işlemi, iç birleştirme işleminin özel bir durumudur. Neden? Niye? Evet, çünkü doğal bir birleştirme eylemi sırasında, orijinal işlenen ilişkilerinin demetleri özel bir koşula göre birleştirilir. Yani, ilişki-işlenenlerin kesiştiği noktada demetlerin eşitliği koşuluyla, iç birleştirme işleminin eylemi ile böyle bir duruma izin verilemezdi. Düşündüğümüz doğal birleştirme işlemi, iç birleştirme işleminin özel bir durumu olduğundan, bunu uygulamak için önceki düşünülen işlemle aynı seçenek kullanılır, yani seçenek iç birleşim. Ancak, doğal birleştirme işlemi için Select operatörünü derlerken, orijinal işlenen ilişkilerinin demetlerinin şemalarının kesişme noktasında eşitlik koşulunu da hesaba katmak gerektiğinden, belirtilen seçeneğe ek olarak, anahtar kelime uygulanır on. İngilizce'den çevrilmiş, kelimenin tam anlamıyla "açık" anlamına gelir ve anlamımıza göre "tabii" olarak tercüme edilebilir. Doğal bir birleştirme işlemi gerçekleştirmek için Select ifadesinin genel biçimi aşağıdaki gibidir: Seç * Konum ilişki adı 1 iç birleşim ilişki adı 2 on demet eşitlik koşulu; Bir örneği düşünün. İki bağıntı verilsin: R1 (A, B, C), R2 (B,C,D); Bu ilişkilerin doğal birleştirme işlemi aşağıdaki operatör kullanılarak gerçekleştirilebilir: seç bir, R1.B, R1.C, D Konum R1 iç birleşim R2 on R1.B=R2.B ve R1.C=R2.C Bu işlemin bir sonucu olarak, Select operatörünün ilk satırında belirtilen, belirtilen kesişme noktasında eşit olan demetlere karşılık gelen öznitelikler sonuçta görüntülenecektir. Burada sadece isim olarak değil, ortak B ve C niteliklerine atıfta bulunduğumuza dikkat edilmelidir. Bu, Kartezyen ürün işleminin uygulanması durumundakiyle aynı nedenle değil, aksi takdirde hangi ilişkiye atıfta bulundukları açık olmayacağı için yapılmalıdır. İlginç bir şekilde, birleştirme koşulunun kullanılan ifadesi (R1.B=R2.B ve R1.C=R2.C), birleştirilmiş Boş-değer ilişkilerinin paylaşılan niteliklerine izin verilmediğini varsayar. Bu, en başından itibaren Yapılandırılmış Sorgu Dili sistemine yerleştirilmiştir. 7. Sol dış birleştirme işlemi Sol dış birleştirme işleminin SQL yapılandırılmış sorgu dili ifadesi, anahtar kelimeyi değiştirerek doğal birleştirme işleminin uygulanmasından elde edilir. iç anahtar kelime başına sol dış. Böylece, yapılandırılmış sorguların dilinde bu işlem aşağıdaki gibi yazılacaktır: Seç * Konum ilişki adı 1 Sol dış katılma ilişki adı 2 on demet eşitlik koşulu; 8. Sağ dış birleştirme işlemi Yapılandırılmış sorgu dilinde bir sağ dış birleştirme işlemi ifadesi, anahtar kelimeyi değiştirerek doğal bir birleştirme işlemi gerçekleştirerek elde edilir. iç anahtar kelime başına sağ dış. Böylece, SQL yapılandırılmış sorgu dilinde sağ dış birleştirme işleminin aşağıdaki gibi yazılacağını anlıyoruz: Seç * Konum ilişki adı 1 sağ dış birleşim ilişki adı 2 on demet eşitlik koşulu; 9. Tam dış birleştirme işlemi Tam bir dış birleştirme işlemi için Yapılandırılmış Sorgu Dili ifadesi, önceki iki durumda olduğu gibi, doğal birleştirme işlemi için ifadeden anahtar kelime değiştirilerek elde edilir. iç anahtar kelime başına tam dış. Böylece, yapılandırılmış sorguların dilinde bu işlem aşağıdaki gibi yazılacaktır: Seç * Konum ilişki adı 1 tam dış birleşim ilişki adı 2 on demet eşitlik koşulu; Bu seçeneklerin SQL yapılandırılmış sorgu dilinin semantiğine dahil edilmesi çok uygundur, çünkü aksi takdirde her programcının bunları bağımsız olarak çıkarması ve her yeni veritabanına girmesi gerekir. 4. Alt sorguları kullanma İşlenen materyalden de anlaşılacağı gibi, yapılandırılmış sorgu dilindeki "alt sorgu" kavramı temel bir kavramdır ve oldukça yaygın olarak uygulanabilir (bu arada bazen SQL sorguları olarak da adlandırılırlar. Gerçekten de, programlama pratiği ve veritabanlarıyla çalışmak, çeşitli ilgili görevleri çözmek için bir alt sorgu sistemi derlemenin, yapılandırılmış bilgilerle çalışmanın diğer bazı yöntemlerine kıyasla çok daha ödüllendirici bir etkinlik olduğunu gösterir. Bu nedenle, alt sorgularla eylemleri, bunların derlenmesini daha iyi anlamak için bir örnek düşünelim. ve kullan. Herhangi bir eğitim kurumunda kullanılabilecek belirli bir veritabanının aşağıdaki parçası olsun: Öğeler (Ürün Kodu, Öğe adı); öğrenciler (kayıt defteri numarası, Ad Soyad); Oturum (Konu kodu, not defteri numarası, Seviye); Öğrencinin not defteri numarasını, soyadını ve adının baş harflerini ve "Veritabanları" adlı ders için notunu gösteren bir ifade döndüren bir SQL sorgusu formüle edelim. Üniversitelerin bu tür bilgileri her zaman ve zamanında alması gerekir, bu nedenle aşağıdaki sorgu bu tür veritabanlarını kullanan belki de en popüler programlama birimidir. Kolaylık olması açısından ayrıca "Soyadı", "Ad" ve "Patronimik" özniteliklerinin Boş değerlere izin vermediğini ve boş olmadığını varsayalım. Bu gereklilik oldukça anlaşılır ve mantıklıdır, çünkü herhangi bir eğitim kurumunun veri tabanına yeni bir öğrenci için girilen verilerin ilki, soyadı, adı ve soyadı hakkındaki verilerdir. Ve böyle bir veri tabanında bir öğrenci hakkında veri içeren ancak aynı zamanda adı bilinmeyen bir giriş olamayacağını söylemeye gerek yok. "Öğeler" ilişki şemasının "Öğe Adı" özniteliğinin bir anahtar olduğuna dikkat edin, bu nedenle tanımdan anlaşılacağı gibi (bundan sonra daha fazlası), tüm öğe adları benzersizdir. Bu, anahtarın temsilini açıklamadan da anlaşılabilir, çünkü bir eğitim kurumunda öğretilen tüm dersler farklı isimlere sahip olmalıdır. Şimdi, operatörün metnini derlemeye başlamadan önce, ilerlerken bize faydalı olacak iki işlevi tanıtacağız. İlk olarak, fonksiyona ihtiyacımız olacak Süs, Trim ("dize") yazılır, yani bu işlevin argümanı bir dizedir. Bu işlev ne yapar? Bu satırın başında ve sonunda boşluk olmadan argümanın kendisini döndürürler, yani bu fonksiyon, örneğin şu durumlarda kullanılır: Trim ("Bogucharnikov") veya Trim ("Maksimenko"), argümanlardan sonra veya önce olduğunda birkaç ekstra boşluğa değer. İkincisi, Sol (dize, sayı) olarak yazılan Sol işlevini de dikkate almak gerekir, yani, biri daha önce olduğu gibi bir dize olan zaten iki argümanın bir işlevi. İkinci argümanı bir sayıdır, sonuçta dizgenin sol tarafından kaç karakter çıkması gerektiğini gösterir. Örneğin, işlemin sonucu: Sol ("Mikhail, 1") + "." + Sol ("Zinovievich, 1") baş harfleri "M. Z" olacaktır. Sorgumuzda bu fonksiyonu kullanacağımız öğrencilerin baş harflerini görüntülemek içindir. Öyleyse, istenen sorguyu derlemeye başlayalım. İlk önce, ana, ana sorguda kullanacağımız küçük bir yardımcı sorgu yapalım: seç Not defteri numarası, Not Konum Oturum, toplantı, celse Nerede Ürün kodu = (seç Ürün Kodu Konum nesneleri Nerede Öğe Adı = "Veritabanları") as "Tahminler" Veritabanları "; Burada as seçeneğini kullanmak, bu sorguyu "Veritabanı Tahminleri" olarak adlandırdığımız anlamına gelir. Bunu, bu istekle daha fazla çalışmanın rahatlığı için yaptık. Ardından, bu sorguda bir alt sorgu: seç Ürün Kodu Konum nesneleri Nerede Öğe Adı = "Veritabanları"; "Oturum" ilişkisinden, söz konusu konuyla, yani veritabanlarıyla ilgili olan demetleri seçmenize olanak tanır. İlginçtir ki, bu iç alt sorgu yalnızca bir değer döndürebilir, çünkü "Öğe Adı" özelliği "Öğeler" ilişkisinin anahtarıdır, yani tüm değerleri benzersizdir. Ve "Puan "Veritabanı" sorgusunun tamamı, alt sorguda belirtilen koşulu karşılayan öğrenciler (not defteri numaraları ve notları) hakkında "Oturum" ilişki verileri arasından seçim yapmanıza olanak tanır, yani "Veritabanı" olarak adlandırılan konu hakkında bilgi . Şimdi, zaten alınan sonuçları kullanarak ana isteği yapacağız. seç Öğrenciler kayıt defteri numarası, Süs (Soyadı) + " " + Sol (İsim, 1) + "." + Sol (Patronimik, 1) + "."as Tam ad, Tahminler "Veritabanları". Seviye Konum öğrenciler iç birleşim ( seç Not defteri numarası, Not Konum Oturum, toplantı, celse Nerede Ürün kodu = (seç Ürün Kodu Konum nesneleri Nerede Öğe Adı = "Veritabanları") ) gibi "Tahminler" Veritabanları ". on Öğrenciler Not Defteri # = "Veritabanı" notları. Kayıt defteri numarası. Bu yüzden ilk olarak sorgu tamamlandıktan sonra görüntülenmesi gerekecek olan özellikleri listeliyoruz. "Sınıf defteri numarası" niteliğinin Öğrenci ilişkisinden, oradan - "Soyadı", "Ad" ve "Patronimik" öznitelikleri olduğu belirtilmelidir. Doğru, son iki öznitelik tam olarak çıkarılmamış, yalnızca ilk harfler çıkarılmıştır. Daha önce girdiğimiz 'Veritabanı Puanı' sorgusundan da 'Puan' özelliğinden bahsediyoruz. Tüm bu öznitelikleri "Öğrenciler" ilişkisinin iç birleşiminden ve "Veritabanı notları" sorgusundan seçiyoruz. Bu iç birleştirme, gördüğümüz gibi, kayıt defterindeki sayıların eşitliği şartıyla tarafımızdan alınmaktadır. Bu iç birleştirme işlemi sonucunda öğrenci ilişkisine notlar eklenir. "Soyadı", "Ad" ve "Patronimik" nitelikleri koşula göre Boş değerlere izin vermediğinden ve boş olmadığından, "Ad" özniteliğini döndüren hesaplama formülünün (Süs (Soyadı) + " " + Sol (İsim, 1) + "." + Sol (Patronimik, 1) + "."as Tam ad), sırasıyla ek kontroller gerektirmez, basitleştirilmiştir. Ders numarası 7. Temel ilişkiler Bildiğimiz gibi, veritabanları, temel amacı ilişkiler şeklinde sunulan verileri depolamak olan bir tür kapsayıcı gibidir. Doğalarına ve yapılarına bağlı olarak ilişkilerin şu şekilde bölündüğünü bilmelisiniz: 1) temel ilişkiler; 2) sanal ilişkiler. Temel görünüm ilişkileri yalnızca bağımsız verileri içerir ve diğer veritabanı ilişkileri açısından ifade edilemez. Ticari veritabanı yönetim sistemlerinde, temel ilişkiler genellikle basitçe şu şekilde ifade edilir: tablolar sanal ilişkiler kavramına karşılık gelen temsillerin aksine. Bu kursta, sadece temel ilişkileri, onlarla çalışmanın ana tekniklerini ve ilkelerini biraz ayrıntılı olarak ele alacağız. 1. Temel veri türleri İlişkiler gibi veri türleri şu şekilde ayrılır: temel и sanal. (Sanal veri türlerinden biraz sonra bahsedeceğiz; bu konuya ayrı bir bölüm ayıracağız.) Temel veri türleri - bunlar, veritabanı yönetim sistemlerinde başlangıçta tanımlanan, yani varsayılan olarak orada bulunan herhangi bir veri türüdür (temel veri türünden geçtikten hemen sonra analiz edeceğimiz kullanıcı tanımlı bir veri türünün aksine). Gerçek temel veri türlerinin değerlendirilmesine geçmeden önce, genel olarak ne tür verilerin olduğunu listeliyoruz: 1) sayısal veriler; 2) mantıksal veriler; 3) dizi verileri; 4) tarih ve saati tanımlayan veriler; 5) kimlik verileri. Varsayılan olarak, veritabanı yönetim sistemleri, her biri listelenen veri türlerinden birine ait olan en yaygın veri türlerinden birkaçını tanıtmıştır. Onları arayalım. 1. sayısal veri türü ayırt edilir: 1) Tamsayı. Bu anahtar sözcük genellikle bir tamsayı veri türünü belirtir; 2) Gerçek, gerçek veri türüne karşılık gelen; 3) Ondalık(n, m). Bu bir ondalık veri türüdür. Ayrıca, gösterimde n, sayının toplam basamak sayısını sabitleyen bir sayıdır ve m, ondalık noktadan sonra kaç karakter olduğunu gösterir; 4) Para veya Para Birimi, özellikle parasal veri türünün uygun veri gösterimi için tanıtıldı. 2. mantıklı veri türü genellikle yalnızca bir temel tür tahsis eder, bu Mantıksaldır. 3. Sicim veri türünün dört temel türü vardır (yani elbette en yaygın olanları): 1) Bit(n). Bunlar sabit uzunlukta n olan bit dizileridir; 2) Varbit(n). Bunlar aynı zamanda bit dizileridir, ancak değişken uzunlukları n biti aşmaz; 3) Karakter(n). Bunlar, sabit uzunlukta n olan karakter dizileridir; 4) Varchar(n). Bunlar, değişken uzunluğu n karakteri geçmeyen karakter dizileridir. 4. Tip tarih ve saat aşağıdaki temel veri türlerini içerir: 1) Tarih - tarih veri türü; 2) Zaman - günün saatini ifade eden veri tipi; 3) Tarih-saat, hem tarih hem de saati ifade eden bir veri türüdür. 5. kimlik Veri türü, veritabanı yönetim sistemine varsayılan olarak dahil edilen yalnızca bir tür içerir ve bu, GUID'dir (Globally Unique Identifier). Tüm temel veri türlerinin farklı veri temsil aralıklarının varyantlarına sahip olabileceğine dikkat edilmelidir. Örnek vermek gerekirse, dört baytlık tamsayı veri türünün varyantları sekiz bayt (bigint) ve iki bayt (smallint) veri türleri olabilir. Temel GUID veri türü hakkında ayrıca konuşalım. Bu tür, küresel olarak benzersiz tanımlayıcı olarak adlandırılan on altı baytlık değerleri depolamak için tasarlanmıştır. Bu tanımlayıcının tüm farklı değerleri, özel bir yerleşik işlev çağrıldığında otomatik olarak oluşturulur. YeniKimlik(). Bu atama, kelimenin tam anlamıyla "yeni tanımlayıcı değeri" anlamına gelen tam İngilizce New Identification ifadesinden gelir. Belirli bir bilgisayarda oluşturulan her tanımlayıcı değeri, üretilen tüm bilgisayarlarda benzersizdir. GUID tanımlayıcısı, özellikle veritabanı çoğaltmasını düzenlemek için, yani mevcut bazı veritabanlarının kopyalarını oluştururken kullanılır. Bu tür GUID'ler, diğer temel türlerle birlikte veritabanı geliştiricileri tarafından kullanılabilir. GUID türü ile diğer taban türleri arasındaki bir ara konum, başka bir özel taban türü tarafından işgal edilir - tür tezgah. Bu tür verileri belirtmek için özel bir anahtar sözcük kullanılır. Sayaç(x0, ∆x), kelimenin tam anlamıyla İngilizce'den tercüme edilir ve "sayaç" anlamına gelir. parametre x0 başlangıç değerini ayarlar ve Δx - artış adımı. Bu Sayaç türünün değerleri mutlaka tamsayılardır. Bu temel veri türüyle çalışmanın çok sayıda ilginç özelliği içerdiğine dikkat edilmelidir. Örneğin, bu Sayaç türünün değerleri ayarlanmaz, diğer tüm veri türleri ile çalışırken alıştığımız gibi, bunlar küresel olarak benzersiz tanımlayıcı türünün değerlerine çok benzer şekilde talep üzerine oluşturulur. Sayaç tipinin yalnızca tablo tanımlanırken ve ancak o zaman belirtilebilmesi de olağandışıdır! Bu tür kodda kullanılamaz. Ayrıca bir tablo tanımlarken sayaç tipinin yalnızca bir sütun için belirtilebileceğini de unutmamalısınız. Satır eklendiğinde sayaç veri değerleri otomatik olarak oluşturulur. Ayrıca, bu nesil tekrar olmadan gerçekleştirilir, böylece sayaç her satırı her zaman benzersiz bir şekilde tanımlayacaktır. Ancak bu, sayaç verileri içeren tablolarla çalışırken bazı rahatsızlıklar yaratır. Örneğin, tablo tarafından verilen ilişkideki veriler değişirse ve bunların silinmesi veya değiştirilmesi gerekiyorsa, özellikle deneyimsiz bir programcı çalışıyorsa, sayaç değerleri kolayca "kartları karıştırabilir". Böyle bir durumu anlatan bir örnek verelim. Dört satırın girildiği bir ilişkiyi temsil eden aşağıdaki tablo verilsin:
Sayaç, her yeni satıra otomatik olarak benzersiz bir ad verdi. Şimdi ikinci ve dördüncü satırları tablodan çıkaralım ve ardından bir satır daha ekleyelim. Bu işlemler, kaynak tablonun aşağıdaki dönüşümüyle sonuçlanacaktır:
Böylece sayaç, benzersiz adlarıyla birlikte ikinci ve dördüncü satırları kaldırdı ve beklendiği gibi onları yeni satırlara "yeniden atamadı". Ayrıca, veritabanı yönetim sistemi, aynı anda birden fazla sayacı tek bir tabloda bildirmenize izin vermeyeceği gibi, sayacın değerini manuel olarak değiştirmenize asla izin vermez. Tipik olarak sayaç, tablodaki bir vekil, yani yapay bir anahtar olarak kullanılır. Dört baytlık bir sayacın benzersiz değerlerinin saniyede bir değer oluşturma hızında 100 yıldan fazla süreceğini bilmek ilginçtir. Nasıl hesaplandığını gösterelim: 1 yıl = 365 gün * 24 sa * 60 s * 60 s < 366 gün * 24 sa * 60 s * 60 s < 225 ile. 1 saniye > 2-25 год. 24*8 değerler / 1 değer/saniye = 232 c > 27 yıl > 100 yıl. 2. Özel veri türü Özel bir veri türü, tüm temel türlerden farklıdır, çünkü başlangıçta veritabanı yönetim sisteminde yerleşik değildir, varsayılan veri türü olarak bildirilmemiştir. Bu tip, herhangi bir kullanıcı ve veritabanı programcısı tarafından kendi istek ve gereksinimlerine göre oluşturulabilir. Bu nedenle, kullanıcı tanımlı bir veri türü, bazı temel türlerin bir alt türüdür, yani izin verilen değerler kümesinde bazı kısıtlamalara sahip bir temel türdür. Sözde kod gösteriminde, aşağıdaki standart ifade kullanılarak özel bir veri türü oluşturulur: Alt tür oluştur alt tür adı Tip temel tip adı As alt tür kısıtlaması; Bu nedenle, ilk satırda, yeni, kullanıcı tanımlı veri türümüzün adını, ikincisinde - mevcut temel veri türlerinden hangisini model olarak aldığımızı, kendimizinkini oluşturduğumuzu ve son olarak üçüncü olarak belirtmeliyiz. - temel veri türünün değer kümesindeki kısıtlamalara mevcut olanlara eklememiz gereken kısıtlamalar - örnek. Alt tür kısıtlamaları, tanımlanan alt türün adına bağlı bir koşul olarak yazılır. Create ifadesinin nasıl çalıştığını daha iyi anlamak için aşağıdaki örneği inceleyin. Örneğin, postada çalışmak için kendi özel veri türümüzü oluşturmamız gerektiğini varsayalım. Bu, posta kodu numaraları gibi verilerle çalışacak tür olacaktır. Sayılarımız, yalnızca pozitif olabilmeleri bakımından sıradan altı basamaklı ondalık sayılardan farklı olacaktır. İhtiyacımız olan alt türü oluşturmak için bir operatör yazalım: Alt tür oluştur Posta kodu Tip ondalık(6, 0) As Posta kodu > 0. Neden ondalık sayıyı (6, 0) seçtik? İndeksin alışılmış biçimini hatırladığımızda, bu tür sayıların sıfırdan dokuza kadar altı tam sayıdan oluşması gerektiğini görüyoruz. Bu yüzden temel veri türü olarak ondalık türü aldık. Genel olarak, temel veri türüne dayatılan koşulun, yani alt tür kısıtlamasının, mantıksal bağlaçları içerebileceğini ve genel olarak herhangi bir keyfi karmaşıklığın ifadesi olabileceğini belirtmek ilginçtir. Bu şekilde tanımlanan özel veri alt türleri, hem program kodunda hem de tablo sütunlarında veri türleri tanımlanırken diğer temel veri türleri ile birlikte serbestçe kullanılabilir, yani bunlarla çalışırken temel veri türleri ve kullanıcı veri türleri tamamen eşittir. Görsel geliştirme ortamında, diğer temel veri türleri ile birlikte geçerli türlerin listelerinde görünürler. Kendimize ait yeni bir veritabanı tasarlarken belgesiz (kullanıcı tanımlı) bir veri türüne ihtiyaç duyma ihtimalimiz oldukça yüksektir. Aslında, varsayılan olarak, en yaygın görevleri çözmek için sırasıyla uygun olan veritabanı yönetim sistemine yalnızca en yaygın veri türleri dikilir. Konu veritabanlarını derlerken, kendi veri türlerinizi tasarlamadan yapmanız neredeyse imkansızdır. Ancak ilginç bir şekilde, eşit olasılıkla, kodu dağıtmamak ve karmaşıklaştırmamak için oluşturduğumuz alt türü kaldırmamız gerekebilir. Bunu yapmak için, veritabanı yönetim sistemlerinde genellikle yerleşik özel bir operatör bulunur. düşürmek, bu "kaldır" anlamına gelir. Gereksiz özel türleri kaldırmak için bu operatörün genel biçimi aşağıdaki gibidir: Alt türü bırak özel türün adı; Yeterince genel olan alt türler için genellikle özel veri türleri önerilir. 3. Varsayılan değerler Veritabanı yönetim sistemleri, herhangi bir isteğe bağlı varsayılan değer veya aynı zamanda varsayılan olarak da adlandırıldığı gibi oluşturma yeteneğine sahip olabilir. Herhangi bir programlama ortamında bu işlem oldukça büyük bir ağırlığa sahiptir, çünkü hemen hemen her görevde sabitler, değişmez varsayılan değerler eklemek gerekli olabilir. Veritabanı yönetim sistemlerinde bir varsayılan oluşturmak için, kullanıcı tanımlı bir veri tipinin geçişinden bize zaten aşina olduğumuz fonksiyon kullanılır. oluşturmak. Yalnızca varsayılan bir değer oluşturulması durumunda ek bir anahtar kelime de kullanılır. varsayılan, bu "varsayılan" anlamına gelir. Başka bir deyişle, mevcut bir veritabanında varsayılan bir değer oluşturmak için aşağıdaki ifadeyi kullanmanız gerekir: Varsayılan oluştur varsayılan ad As sabit ifade; Bu operatörü uygularken sabit bir değer yerine varsayılan değer veya ifade yapmak istediğimiz değeri veya ifadeyi yazmanız gerektiği açıktır. Ve tabi ki veri tabanımızda hangi isim altında kullanmamızın uygun olacağına karar vermemiz ve operatörün ilk satırına bu ismi yazmamız gerekiyor. Bu özel durumda, bu Create ifadesinin Microsoft SQL Server sisteminde yerleşik olan Transact-SQL sözdizimini izlediğini unutmayın. Peki elimizde ne var? Varsayılanın, tıpkı nesnesi gibi, veritabanlarında depolanan adlandırılmış bir sabit olduğu sonucuna vardık. Görsel geliştirme ortamında varsayılanlar, vurgulanan varsayılanlar listesinde görünür. İşte bir varsayılan oluşturmaya bir örnek. Veritabanımızın doğru çalışması için, içinde bir şeyin sınırsız ömrü anlamına gelen bir değer fonksiyonunun gerekli olduğunu varsayalım. Ardından, bu veritabanının değerler listesine bu gereksinimi karşılayan varsayılan değeri girmeniz gerekir. Bu gerekli olabilir, çünkü kod metninde bu oldukça hantal ifadeyle her karşılaştığınızda, tekrar yazmak son derece elverişsiz olacaktır. Bu nedenle, bir şeyin sınırsız ömrü anlamına gelen bir varsayılan oluşturmak için yukarıdaki Create ifadesini kullanacağız. Varsayılan oluştur "zaman sınırı yok" As ‘9999-12-31 23: 59:59’ Transact-SQL sözdizimi burada da kullanılmıştır, buna göre tarih-zaman sabitlerinin değerleri (bu durumda, '9999-12-31 23:59:59') belirli bir yöndeki karakter dizileri olarak yazılmıştır. Karakter dizilerinin tarih saat değerleri olarak yorumlanması, dizilerin kullanıldığı bağlam tarafından belirlenir. Örneğin, bizim özel durumumuzda, sabit satıra önce yılın sınır değeri, ardından saat yazılır. Ancak, tüm yararlılıkları için, kullanıcı tanımlı bir veri türü gibi varsayılanlar bazen bunların kaldırılmasını da gerektirebilir. Veritabanı yönetim sistemleri genellikle, artık ihtiyaç duyulmayan daha kullanıcı tanımlı bir veri türünü kaldıran bir operatöre benzer, özel bir yerleşik yüklem içerir. Bu bir yüklem Damla ve operatörün kendisi şöyle görünür: Varsayılanı bırak varsayılan ad; 4. Sanal Nitelikler Veritabanı yönetim sistemlerindeki tüm nitelikler (ilişkilerle mutlak analoji ile) temel ve sanal olarak ayrılır. Lafta temel nitelikler bir kereden fazla kullanılması gereken depolanmış özelliklerdir ve bu nedenle kaydedilmesi tavsiye edilir. Ve sırayla, sanal nitelikler saklanmaz, ancak hesaplanan öznitelikler. Bunun anlamı ne? Bu, sözde sanal özniteliklerin değerlerinin gerçekte depolanmadığı, ancak verilen formüller aracılığıyla anında temel öznitelikler aracılığıyla hesaplandığı anlamına gelir. Bu durumda, hesaplanan sanal özniteliklerin etki alanları otomatik olarak belirlenir. İki özniteliğin adi, temel ve üçüncü özniteliğin sanal olduğu bir ilişkiyi tanımlayan bir tablo örneği verelim. Özel olarak girilmiş bir formüle göre hesaplanacaktır.
Böylece, "Kg Ağırlık" ve "Kg Başına Fiyat Rub" niteliklerinin temel nitelikler olduğunu görüyoruz, çünkü sıradan değerlere sahipler ve veritabanımızda saklanıyorlar. Ancak "Maliyet" özniteliği sanal bir özniteliktir, çünkü hesaplama formülüne göre belirlenir ve aslında veritabanında depolanmayacaktır. Sanal özniteliklerin doğası gereği varsayılan değerleri alamayacağını ve genel olarak bir sanal öznitelik için varsayılan değer kavramının anlamsız olduğunu ve dolayısıyla uygulanabilir olmadığını belirtmek ilginçtir. Ayrıca, sanal özniteliklerin etki alanları otomatik olarak belirlense de, hesaplanan değerlerin türünün bazen mevcut olandan diğerine değiştirilmesi gerektiğini de bilmelisiniz. Bunu yapmak için, veritabanı yönetim sistemlerinin dili, hesaplanan ifadenin türünün yeniden tanımlanabileceği yardımı ile özel bir Dönüştürme yüklemine sahiptir. Convert, sözde açık tür dönüştürme işlevidir. Aşağıdaki gibi yazılmıştır: dönüştürmek (veri tipi, ifade); Dönüştür işlevinin ikinci argümanı olan ifade, türü işlevin ilk argümanı tarafından belirtilen bu tür veriler olarak hesaplanır ve çıktılanır. Bir örnek düşünün. "2 * 2" ifadesinin değerini hesaplamamız gerektiğini varsayalım, ancak bunu bir "4" tamsayı olarak değil, bir karakter dizisi olarak çıkarmamız gerekiyor. Bu görevi gerçekleştirmek için aşağıdaki Dönüştür işlevini yazıyoruz: dönüştürmek (Karakter(1), 2 * 2). Böylece, Convert fonksiyonunun bu gösteriminin tam olarak ihtiyacımız olan sonucu vereceğini görebiliriz. 5. Anahtar kavramı Bir temel ilişkinin şemasını bildirirken, birden çok anahtarın bildirimleri verilebilir. Bununla daha önce birçok kez karşılaştık. Son olarak, ilişki anahtarlarının ne olduğu hakkında daha ayrıntılı konuşmanın ve genel ifadeler ve yaklaşık tanımlarla sınırlı kalmamanın zamanı geldi. Öyleyse, bir ilişki anahtarının kesin bir tanımını verelim. İlişki şeması anahtarı Bildirildiği bir veya daha fazla öznitelikten oluşan orijinal şemanın bir alt şemasıdır. benzersizlik koşulu ilişki demetlerindeki değerler. Teklik koşulunun ne olduğunu veya aynı zamanda denildiği gibi anlamak için, benzersiz kısıtlama, bir tanımlama grubu tanımı ve bir tanımlama grubunu bir alt devreye yansıtmanın tekli işlemi ile başlayalım. Onları getirelim: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - bir demet tanımı, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S tekli izdüşüm işleminin tanımıdır; Tuple'ın alt şema üzerindeki izdüşümünün tablo satırının bir alt dizisine karşılık geldiği açıktır. Öyleyse, anahtar nitelik benzersizliği kısıtlaması tam olarak nedir? S ilişkisi şeması için K anahtarının bildirilmesi, daha önce de söylediğimiz gibi, aşağıdaki değişmez koşulun formülasyonuna yol açar: benzersizlik kısıtlaması ve şu şekilde gösterilir: Env < K → S > r(S): Inv < K → S > r(S) = ∀t1T,2 ∈ r(t 1[K]=t2 [K] → t 1(K) = t2(S)), K ⊆ S; Dolayısıyla, K anahtarının bu benzersizlik kısıtlaması Inv < K → S > r(S), eğer herhangi iki tuple t1 и t2, r(S) ilişkisine ait, K anahtarına izdüşümde eşittir, o zaman bu zorunlu olarak bu iki kümenin eşitliğini ve S ilişkisinin tüm şemasına izdüşümü gerektirir. Diğer bir deyişle, tüm değerler Anahtar niteliklere ait olan demetler benzersizdir, ilişkilerinde benzersizdir. Ve bir ilişki anahtarı için ikinci önemli gereksinim şudur: fazlalık gereksinimi. Bunun anlamı ne? Bu gereksinim, anahtarın kesin bir alt kümesinin benzersiz olması gerekmediği anlamına gelir. Sezgisel düzeyde, anahtar niteliğin, ilişkinin her bir demetini benzersiz ve kesin olarak tanımlayan ilişki niteliği olduğu açıktır. Örneğin, bir tablo tarafından verilen aşağıdaki ilişkide:
Anahtar özellik "Not Defteri #" özelliğidir, çünkü farklı öğrenciler aynı not defteri numarasına sahip olamaz, yani bu özellik benzersiz bir kısıtlamaya tabidir. Herhangi bir ilişkinin şemasında çeşitli anahtarların oluşabilmesi ilginçtir. Ana anahtar türlerini listeleriz: 1) basit anahtar bir ve daha fazla öznitelikten oluşan bir anahtardır. Örneğin, belirli bir konunun sınav kağıdında, herhangi bir öğrenciyi benzersiz bir şekilde tanımlayabildiğinden, kredi kartı numarası basit bir anahtardır; 2) bileşik anahtar iki veya daha fazla öznitelikten oluşan bir anahtardır. Örneğin, derslik listesindeki bir bileşik anahtar, bina numarası ve sınıf numarasıdır. Ne de olsa, her bir kitleyi bu niteliklerden biriyle benzersiz bir şekilde tanımlamak mümkün değildir ve bunu bütünlükleriyle, yani bileşik bir anahtarla yapmak oldukça kolaydır; 3) süper anahtar herhangi bir anahtarın herhangi bir üst kümesidir. Bu nedenle, ilişkinin şeması kesinlikle bir süper anahtardır. Bundan, herhangi bir ilişkinin teorik olarak en az bir anahtarı olduğu ve bunlardan birkaçına sahip olabileceği sonucuna varabiliriz. Ancak, normal bir anahtar yerine bir süper anahtar bildirmek, otomatik olarak uygulanan benzersizlik kısıtlamasını gevşetmeyi içerdiğinden mantıksal olarak yasa dışıdır. Sonuçta, süper anahtar, benzersiz olma özelliğine sahip olmasına rağmen, fazlalık olmama özelliğine sahip değildir; 4) birincil anahtar temel ilişki tanımlandığında ilk bildirilen anahtardır. Bir ve yalnızca bir birincil anahtarın bildirilmesi önemlidir. Ayrıca, birincil anahtar öznitelikleri hiçbir zaman boş değerler alamaz. Bir sözde kod girişinde bir temel ilişki oluştururken, birincil anahtar belirtilir birincil anahtar ve parantez içinde bu anahtar olan özniteliğin adıdır; 5) aday anahtarlar birincil anahtardan sonra bildirilen diğer tüm anahtarlardır. Aday anahtarlar ile birincil anahtarlar arasındaki temel farklar nelerdir? Birincisi, birkaç aday anahtar olabilirken, yukarıda belirtildiği gibi birincil anahtar yalnızca bir tane olabilir. İkinci olarak, eğer birincil anahtarın nitelikleri Null değerleri alamıyorsa, aday anahtarların niteliklerine bu koşul empoze edilmez. Sözde kodda, bir temel ilişki tanımlanırken, aday anahtarlar şu kelimeler kullanılarak bildirilir: aday anahtarı ve sonraki parantez içinde, bir birincil anahtarın bildirilmesi durumunda olduğu gibi, verilen aday anahtar olan özniteliğin adı belirtilir; 6) harici anahtar aynı veya başka bir temel ilişkinin birincil veya aday anahtarına da atıfta bulunan bir temel ilişkide bildirilen bir anahtardır. Bu durumda, yabancı anahtarın atıfta bulunduğu ilişkiye referans (veya ebeveyn) davranış. Yabancı anahtar içeren bir ilişkiye denir. çocuk. Sahte kodda, yabancı anahtar şu şekilde gösterilir: yabancı anahtar, bu kelimelerden hemen sonra parantez içinde yabancı bir anahtar olan bu ilişkinin niteliğinin adı belirtilir ve ondan sonra anahtar kelime yazılır. referanslar ("belirtilir") ve temel ilişkinin adını ve bu özel yabancı anahtarın atıfta bulunduğu özniteliğin adını belirtin. Ayrıca, bir temel ilişki oluştururken, her bir yabancı anahtar için bir koşul yazılır. referans bütünlüğü kısıtlaması, ancak bunun hakkında daha sonra ayrıntılı olarak konuşacağız. Ders #8 Bu dersin konusu, temel ilişki oluşturma operatörünün oldukça ayrıntılı bir tartışması olacaktır. Operatörün kendisini bir sözde kod kaydında analiz edeceğiz, tüm bileşenlerini ve çalışmalarını analiz edeceğiz ve değişiklik yöntemlerini, yani temel ilişkileri değiştirmeyi analiz edeceğiz. 1. Üst dil sembolleri Temel ilişki oluşturma operatörünün sözde kodda yazılmasında kullanılan sözdizimsel yapılar açıklanırken çeşitli yöntemler kullanılır. üst dil sembolleri. Bunlar her türlü açma ve kapama parantezleri, çeşitli nokta ve virgül kombinasyonları, tek kelimeyle, her biri kendi anlamını taşıyan ve programcının kod yazmasını kolaylaştıran sembollerdir. Temel ilişkilerin tasarımında en sık kullanılan ana dilbilimsel sembollerin anlamlarını tanıtalım ve açıklayalım. Yani: 1) üst dil karakteri "{}". Kıvrımlı parantezlerdeki sözdizimsel yapılar zorunlu sözdizimsel birimler. Bir temel ilişki tanımlarken, gerekli öğeler, örneğin, temel niteliklerdir; temel nitelikler bildirilmeden hiçbir ilişki tasarlanamaz. Bu nedenle, temel ilişki oluşturma operatörü sözde kodda yazılırken, temel nitelikler kaşlı ayraçlar içinde listelenir; 2) üst dil sembolü "[]". Bu durumda, bunun tersi doğrudur: köşeli parantez içindeki sözdizimi yapıları şunları temsil eder: isteğe bağlı sözdizimi öğeleri. Temel ilişki oluşturma operatöründeki isteğe bağlı sözdizimsel birimler, sırasıyla, birincil, aday ve yabancı anahtarların sanal öznitelikleridir. Burada, elbette, incelikler de var, ancak daha sonra, temel ilişkiyi oluşturmak için doğrudan operatörün tasarımına geçtiğimizde bunlardan bahsedeceğiz; 3) üst dil sembolü "|". Bu sembol tam anlamıyla "veya", matematikteki analog sembol gibi. Bu üstdilsel sembolün kullanımı, kişinin bu sembolle ayrılmış iki veya daha fazla yapı arasında seçim yapması gerektiği anlamına gelir; 4) üst dilsel sembol "...". Herhangi bir sözdizimsel birimin hemen sonrasına yerleştirilen üç nokta, şu olasılığı ifade eder: tekrarlar üstdilsel simgeden önce gelen bu sözdizimsel öğeler; 5) üstdil sembolü ",..". Bu sembol, bir öncekiyle neredeyse aynı anlama gelir. Yalnızca üst dil sembolü ",.." kullanıldığında, tekrarlama sözdizimsel yapılar oluşur virgüllerle ayrılmışki bu genellikle çok daha uygundur. Bunu akılda tutarak, aşağıdaki iki sözdizimsel yapının denkliğinden bahsedebiliriz: birim [, birim]... и birim,.. ; 2. Bir sözde kod girişinde temel bir ilişki oluşturma örneği Temel ilişki oluşturma operatörünü sözde kodda yazarken kullanılan ana dilbilimsel sembollerin anlamlarını açıklığa kavuşturduğumuza göre, bu operatörün asıl değerlendirmesine geçebiliriz. Yukarıdaki referanslardan da anlaşılacağı gibi, sözde kod girişinde bir temel ilişki yaratma operatörü, temel ve sanal özniteliklerin, birincil, aday ve yabancı anahtarların bildirimlerini içerir. Ek olarak, yukarıda gösterilip açıklanacağı gibi, bu operatör aynı zamanda öznitelik değeri kısıtlamalarını ve tanımlama grubu kısıtlamalarını ve ayrıca sözde referans bütünlük kısıtlamalarını da kapsar. İlk iki kısıtlama, yani öznitelik değeri kısıtlaması ve tanımlama grubu kısıtlaması, özel ayrılmış kelimeden sonra bildirilir. Kontrol. Bilgi bütünlüğü kısıtlamaları iki tür olabilir: güncellemede"güncellenirken" anlamına gelen ve silindiğinde, bu da "silmede" anlamına gelir. Bunun anlamı ne? Bu, bir yabancı anahtar tarafından başvurulan ilişkilerin özniteliklerini güncellerken veya silerken durum bütünlüğünün korunması gerektiği anlamına gelir. (Bunun hakkında daha sonra konuşacağız.) Temel ilişki oluşturma operatörünün kendisi, tarafımızdan daha önce incelenmiş olarak kullanılmaktadır - operatör oluşturmak, yalnızca temel bir ilişki oluşturmak için anahtar kelime eklenir tablo ("davranış"). Ve elbette, ilişkinin kendisi daha büyük olduğundan ve daha önce tartışılan tüm yapıları ve ayrıca yeni ek yapıları içerdiğinden, oluşturma operatörü oldukça etkileyici olacaktır. Öyleyse, temel ilişkileri oluşturmak için kullanılan operatörün genel biçimini sözde kodda yazalım: Tablo oluştur temel ilişki adı { temel özellik adı temel nitelik değer türü Kontrol (özellik değeri sınırı) {Boş | geçersiz değil} varsayılan (varsayılan değer) },.. [sanal öznitelik adı as (hesaplama formülü) ],.. [,Kontrol (grup kısıtlaması)] [,birincil anahtar (özellik adı,..)] [,aday anahtarı (özellik adı,..)]... [,yabancı anahtar (özellik adı, ..) referanslar referans ilişki adı (özellik adı, ..) güncellemede { Kısıtla | Çağlayan | Boş Ayarla} silindiğinde { Kısıtla | Çağlayan | Boş Ayarla} ] ... Bu nedenle, karşılık gelen sözdizimsel yapılardan sonra bir üst dil sembolü ",.." olduğundan, birkaç temel ve sanal öznitelik, aday ve yabancı anahtarın bildirilebileceğini görüyoruz. Birincil anahtarın bildirilmesinden sonra, bu sembol mevcut değildir, çünkü daha önce belirtildiği gibi temel ilişkiler yalnızca bir birincil anahtara izin verir. Şimdi, bildirim mekanizmasına daha yakından bakalım. temel nitelikler. Temel ilişki oluşturma operatöründe herhangi bir özniteliği tanımlarken genel durumda adı, türü, değerleri üzerindeki kısıtlamalar, Boş-değerler geçerlilik bayrağı ve varsayılan değerler belirtilir. Bir özniteliğin türünün ve değer kısıtlamalarının, etki alanını, yani söz konusu öznitelik için kelimenin tam anlamıyla geçerli değerler kümesini belirlediğini görmek kolaydır. Özellik Değer Kısıtlaması öznitelik adına bağlı bir koşul olarak yazılır. Bu materyalin anlaşılmasını kolaylaştırmak için küçük bir örnek: Tablo oluştur temel ilişki adı Seyir tamsayı Kontrol (1 <= Ders ve Ders <= 5; Burada, "1 <= Başlık ve Başlık <= 5" koşulu, bir tamsayı veri türünün tanımıyla birlikte, özniteliğin izin verilen değer kümesini, yani tam anlamıyla alanını gerçekten tamamen koşullandırır. Boş değerler ödeneği bayrağı (Null | Null değil) yasaklar (Boş değil) veya tersine, nitelik değerleri arasında Boş değerlerin görünmesini sağlar (Boş). Az önce tartışılan örneği alarak, Null-geçerlilik bayraklarını uygulama mekanizması aşağıdaki gibidir: Tablo oluştur temel ilişki adı Seyir tamsayı Kontrol (1 <= Ders ve Ders <= 5); Geçersiz değil; Bu nedenle, bir öğrencinin ders numarası asla boş olamaz, veritabanı derleyicileri tarafından bilinemez ve var olamaz. Varsayılan değerler (varsayılan (varsayılan değer)), öznitelik değerleri ekleme ifadesinde açıkça ayarlanmamışsa, bir ilişkiye bir tanımlama grubu eklerken kullanılır. Belirli bir öznitelik için Null değerlerinin geçerli olduğu bildirildiği sürece, varsayılan değerlerin de Null değerler olabileceğini belirtmek ilginçtir. Şimdi tanımı düşünün sanal özellik temel ilişki oluşturma operatöründe. Daha önce de söylediğimiz gibi, bir sanal öznitelik belirlemek, diğer temel öznitelikler aracılığıyla hesaplanması için formüller oluşturmaktan ibarettir. Bir sanal öznitelik "Cost Rub" bildirme örneğini ele alalım. "Ağırlık Kg" ve "Kg Başına Fiyat Rub." temel özelliklerine bağlı bir formül şeklinde. Tablo oluştur temel ilişki adı Ağırlık (kg temel nitelik değer türü Ağırlık Kg Kontrol (Ağırlık Kg öznitelik değerinin kısıtlaması) geçersiz değil varsayılan (varsayılan değer) Fiyat, ovmak. kg başına Fiyat Rublesi temel özelliğinin değer türü. kg başına Kontrol (Kg Başına Fiyat Rub. özelliğinin değerinin sınırlandırılması) geçersiz değil varsayılan (varsayılan değer) ... Maliyet, ovmak. as (Ağırlık Kg * Kg Başına Fiyat Rub.) Biraz önce, öznitelik adlarına bağlı koşullar olarak yazılan öznitelik kısıtlamalarına baktık. Şimdi, bir temel ilişki oluştururken bildirilen ikinci tür kısıtlamaları düşünün, yani demet kısıtlamaları. Tuple kısıtlaması nedir, nitelik kısıtlamasından farkı nedir? Bir tanımlama grubu kısıtlaması, temel öznitelik adına bağlı bir koşul olarak da yazılır, ancak yalnızca tanımlama grubu kısıtlaması durumunda, koşul aynı anda birden çok öznitelik adına bağlı olabilir. Tuple kısıtlamalarıyla çalışma mekanizmasını gösteren bir örnek düşünün: Tablo oluştur temel ilişki adı min Ağırlık Kg temel özelliğin değer türü min Ağırlık Kg Kontrol (min Ağırlık Kg öznitelik değerinin kısıtlaması) geçersiz değil varsayılan (varsayılan değer) maksimum Ağırlık Kg temel özelliğin değer türü maks Ağırlık Kg Kontrol (maksimum Ağırlık Kg öznitelik değerinin kısıtlaması) geçersiz değil varsayılan (varsayılan değer) Kontrol (0 < dk Ağırlık Kg ve min Ağırlık Kg < maks Ağırlık Kg); Bu nedenle, bir demete bir kısıtlama uygulamak, öznitelik adları için demetin değerlerini ikame etmek anlamına gelir. Temel ilişki oluşturma operatörünü ele almaya devam edelim. Bir kez bildirildiğinde, temel ve sanal öznitelikler bildirilebilir veya bildirilmeyebilir. ключи: birincil, aday ve harici. Daha önce de söylediğimiz gibi, başka bir (veya aynı) temel ilişkide, birinci ilişki bağlamında bir birincil veya aday anahtara karşılık gelen bir temel ilişkinin alt şemasına denir. yabancı anahtar. Yabancı anahtarlar temsil eder bağlantı mekanizması bazı ilişkilerin demetleri diğer ilişkilerin demetleri üzerinde, yani. daha önce bahsedilen sözde referans bütünlüğü kısıtlamaları. (Durum bütünlüğü (yani, bütünlük kısıtlamaları tarafından uygulanan bütünlük) temel ilişkinin ve tüm veritabanının başarısı için kritik olduğundan, bu kısıtlama bir sonraki dersin odak noktası olacaktır.) Birincil ve aday anahtarları bildirmek, daha önce tartıştığımız temel ilişki şemasına uygun benzersizlik kısıtlamalarını dayatır. Ve son olarak, temel ilişkinin silinme olasılığı hakkında söylenmelidir. Çoğu zaman veritabanı tasarımı uygulamasında, program kodunu karıştırmamak için eski bir gereksiz ilişkiyi kaldırmak gerekir. Bu, zaten bilinen operatör kullanılarak yapılabilir. Damla. Tam genel biçiminde, temel ilişki silme operatörü şöyle görünür: Tabloyu bırak temel ilişkinin adı; 3. Devlete göre bütünlük kısıtlaması Bütünlük kısıtlaması ilişkisel veri nesnesi itibariyle sözde veri değişmezidir. Aynı zamanda, bütünlük, verileri ifşa etmek, değiştirmek veya yok etmek için verilerin yetkisiz erişime karşı korunması anlamına gelen güvenlikten güvenle ayırt edilmelidir. Genel olarak, ilişkisel veri nesneleri üzerindeki bütünlük kısıtlamaları sınıflandırılır. hiyerarşi seviyelerine göre bu aynı ilişkisel veri nesneleri (ilişkisel veri nesnelerinin hiyerarşisi, iç içe geçmiş kavramların bir dizisidir: "öznitelik - demet - ilişki - veritabanı"). Ne anlama geliyor? Bu, bütünlük kısıtlamalarının şunlara bağlı olduğu anlamına gelir: 1) nitelik düzeyinde - nitelik değerlerinden; 2) demet düzeyinde - demet değerlerinden, yani. birkaç özelliğin değerlerinden; 3) ilişkiler düzeyinde - bir ilişkiden, yani. birkaç demetten; 4) veritabanı düzeyinde - birkaç ilişkiden. Bu nedenle, şimdi bize yalnızca yukarıdaki kavramların her birinin durumu üzerindeki bütünlük kısıtlamalarını daha ayrıntılı olarak ele almak kalıyor. Ama önce, durum bütünlüğü kısıtlamaları için prosedürel ve bildirimsel destek kavramlarını verelim. Bu nedenle, bütünlük kısıtlamaları için destek iki tür olabilir: 1) prosedürel, yani program kodu yazılarak oluşturulmuş; 2) bildirimsel, yani, yukarıdaki iç içe kavramların her biri için belirli kısıtlamalar bildirilerek oluşturulur. Bütünlük kısıtlamaları için bildirime dayalı destek, temel ilişkiyi oluşturmak için Create deyimi bağlamında uygulanır. Bunun hakkında daha ayrıntılı konuşalım. İlişkisel veri nesnelerinin hiyerarşik merdivenimizin altından, yani bir öznitelik kavramından kısıtlamalar kümesini düşünmeye başlayalım. Öznitelik Düzeyi Kısıtlaması Bu içerir: 1) nitelik değerlerinin türüyle ilgili kısıtlamalar. Örneğin, değerler için bir tamsayı koşulu, yani daha önce tartışılan temel ilişkilerden birinden "Kurs" niteliği için bir tamsayı koşulu; 2) nitelik adına bağlı bir koşul olarak yazılan bir nitelik değeri kısıtlaması. Örneğin, bir önceki paragraftakiyle aynı temel ilişkiyi analiz ettiğimizde, bu ilişkide seçeneği kullanarak öznitelik değerleri üzerinde de bir kısıtlama olduğunu görüyoruz. Kontrol, yani: Kontrol (1 <= Ders ve Ders <= 5); 3) Nitelik düzeyi kısıtlaması, iyi bilinen geçerlilik bayrağı (Boş) veya tersine, Boş değerlerin kabul edilemezliği (Boş değil) tarafından tanımlanan Boş değer kısıtlamalarını içerir. Daha önce bahsettiğimiz gibi, ilk iki kısıtlama, özniteliğin etki alanı kısıtlamasını, yani tanım kümesinin değerini tanımlar. Ayrıca, ilişkisel veri nesnelerinin hiyerarşik merdivenine göre, demetler hakkında konuşmamız gerekir. Yani, demet seviyesi kısıtlaması bir demet kısıtlamasına indirgenir ve ilişki şemasının birkaç temel özniteliğinin adlarına bağlı bir koşul olarak yazılır, yani bu durum bütünlüğü kısıtlaması, benzer olandan çok daha küçük ve basittir, yalnızca özniteliğe karşılık gelir. Ve yine, şimdi ihtiyacımız olan demet kısıtlamasına sahip olan, daha önce üzerinden geçtiğimiz temel ilişki örneğini hatırlamak faydalı olacaktır, yani: Kontrol (0 < dk Ağırlık Kg ve min Ağırlık Kg < maks Ağırlık Kg); Ve son olarak, devlet üzerindeki bütünlük kısıtlaması bağlamında son önemli kavram, ilişki düzeyi kavramıdır. Daha önce de söylediğimiz gibi, ilişki düzeyi kısıtlaması birincil değerlerin sınırlandırılmasını içerir (birincil anahtar) ve aday (aday anahtarı) anahtarlar. Veritabanlarına uygulanan kısıtlamaların artık durum bütünlüğü kısıtlamaları değil, referans bütünlüğü kısıtlamaları olması ilginçtir. 4. Referans Bütünlüğü Kısıtlamaları Bu nedenle, veritabanı düzeyi kısıtlaması, yabancı anahtar referans bütünlüğü kısıtlamasını (yabancı anahtar). Temel ilişki ve yabancı anahtarlar oluştururken referans bütünlüğü kısıtlamalarından bahsettiğimizde bundan kısaca bahsetmiştik. Şimdi bu kavram hakkında daha ayrıntılı konuşmanın zamanı geldi. Daha önce de söylediğimiz gibi, beyan edilen temel ilişkinin yabancı anahtarı, başka bir (çoğunlukla) temel ilişkinin birincil veya aday anahtarını ifade eder. Bu durumda, yabancı anahtarın başvurduğu ilişkinin çağrıldığını hatırlayın. referans veya ebeveyn, çünkü bir tür referans temel ilişkisinde bir veya birden çok niteliği "yumurtlar". Ve sırayla, bir yabancı anahtar içeren bir ilişkiye denir. çocuk, ayrıca bariz nedenlerle. Nedir referans bütünlüğü kısıtlaması? Ve, yabancı anahtarın değeri herhangi bir özellikte Null değerler içermedikçe, çocuk ilişkisinin yabancı anahtarının her değerinin, mutlaka üst ilişkinin herhangi bir anahtarının değerine karşılık gelmesi gerektiği gerçeğinden oluşur. Bu koşulu ihlal eden bir çocuk ilişkisinin demetlerine denir. asılı. Gerçekten de, alt ilişkinin yabancı anahtarı, ebeveyn ilişkisinde gerçekte var olmayan bir özniteliğe atıfta bulunuyorsa, o zaman hiçbir şeye atıfta bulunmaz. Mümkün olan her şekilde kaçınılması gereken tam da bu durumlardandır ve bu, referans bütünlüğünü korumak anlamına gelir. Ancak, hiçbir veritabanının sarkan bir demet oluşturulmasına asla izin vermeyeceğini bilen geliştiriciler, veritabanında başlangıçta sarkan demetler olmadığından ve mevcut tüm anahtarların üst ilişkinin çok gerçek bir niteliğine atıfta bulunduğundan emin olurlar. Bununla birlikte, veritabanının çalışması sırasında sarkan demetlerin oluştuğu durumlar vardır. Bu durumlar nelerdir? Tuple'lar üst ilişkiden çıkarıldığında veya ebeveyn ilişkisinin bir demetinin anahtar değeri güncellendiğinde, referans bütünlüğünün ihlal edilebileceği, yani sarkan demetlerin meydana gelebileceği bilinmektedir. Bir yabancı anahtar değeri bildirirken bunların oluşma olasılığını dışlamak için aşağıdakilerden biri belirtilir: üç mevcut kurallar üst ilişkideki anahtar değeri güncellerken uygun şekilde uygulanan referans bütünlüğünü korumak (yani, daha önce bahsettiğimiz gibi, güncellemede) veya üst ilişkiden bir demeti çıkarırken (silindiğinde). Ana ilişkiye yeni bir demet eklemenin, bariz nedenlerden dolayı referans bütünlüğünü bozamayacağına dikkat edilmelidir. Ne de olsa, bu demet temel ilişkiye yeni eklendiyse, yokluğu nedeniyle daha önce hiçbir öznitelik ona atıfta bulunamazdı! Peki veritabanlarında referans bütünlüğünü korumak için kullanılan bu üç kural nedir? Onları listeleyelim. 1. kısıtlamak, veya kısıtlama kuralı. Temel ilişkimizi ayarlarken, bir referans bütünlüğü kısıtlamasında yabancı anahtarları bildirirken, bu koruma kuralını uyguladıysak, o zaman üst ilişkideki bir anahtarı güncellemek veya üst ilişkiden bir kümeyi silmek, bu küme, basitçe gerçekleştirilemez. alt ilişkinin en az bir demeti tarafından başvurulur, yani işlem kısıtlamak asılı demetlerin ortaya çıkmasına neden olabilecek herhangi bir eylemi gerçekleştirmeyi kesinlikle yasaklar. Bu kuralın uygulamasını aşağıdaki örnekle gösteriyoruz. İki bağıntı verilsin: ebeveyn tutumu
çocuk ilişkisi
Çocuk ilişkileri tuple'larının (2,...) ve (2,...) ana ilişki tuple'ına (..., 2), çocuk ilişkileri tuple'ının (3,...) ise ebeveyn ilişki tuple'ına (...,...) atıfta bulunduğunu görüyoruz. ( ..., 3) ebeveyn tutumu. Çocuk ilişkisinin tuple'ı (100,...) sarkıyor ve geçerli değil. Burada yalnızca ana ilişki tuple'ları (..., 1) ve (..., 4), alt ilişkinin yabancı anahtarlarından herhangi biri tarafından referans alınmadığı için anahtar değerlerinin güncellenmesine ve tuple'ların silinmesine izin verir. Yukarıdaki tüm anahtarların bildirimini içeren temel bir ilişki oluşturmak için operatörü oluşturalım: Tablo oluştur ebeveyn tutumu Birincil anahtar Tamsayı geçersiz değil birincil anahtar (Birincil anahtar) Tablo oluştur çocuk ilişkisi Yabancı anahtar Tamsayı Null yabancı anahtar (Yabancı anahtar) referanslar Ebeveyn İlişkisi (Birincil_anahtar) güncellemede sil Kısıtla 2. Çağlayan, veya kademeli değişiklik kuralı. Temel ilişkimizde yabancı anahtarları bildirirken, referans bütünlüğünü koruma kuralını kullandıysak Çağlayan, ardından üst ilişkideki bir anahtarın güncellenmesi veya üst ilişkiden bir demetin silinmesi, alt ilişkinin ilgili anahtarlarının ve demetlerinin otomatik olarak güncellenmesine veya silinmesine neden olur. Kademeli değiştirme kuralının nasıl çalıştığını daha iyi anlamak için bir örneğe bakalım. Önceki örnekten zaten aşina olduğumuz temel ilişkiler verilsin: ebeveyn tutumu
и çocuk ilişkisi
“Ana ilişki” ilişkisini tanımlayan tablodaki bazı demetleri güncellediğimizi, yani demet (..., 2) demetini (..., 20) ile değiştirdiğimizi, yani yeni bir ilişki elde ettiğimizi varsayalım: ebeveyn tutumu
Ve aynı zamanda, yabancı anahtarları bildirirken temel ilişkimizi "Alt ilişki" oluşturma ifadesinde, referans bütünlüğünü koruma kuralını kullandık. Çağlayan, yani temel ilişkimizi oluşturma operatörü şöyle görünür: Tablo oluştur ebeveyn tutumu Birincil anahtar Tamsayı geçersiz değil birincil anahtar (Birincil anahtar) Tablo oluştur çocuk ilişkisi Yabancı anahtar Tamsayı Null yabancı anahtar (Yabancı anahtar) referanslar Ebeveyn İlişkisi (Birincil_anahtar) güncellemede Cascade Silinen Cascade O zaman ebeveyn ilişkisi yukarıda açıklanan şekilde güncellendiğinde çocuk ilişkisine ne olur? Aşağıdaki formu alacaktır: çocuk ilişkisi
Böylece, gerçekten, kural Çağlayan üst ilişkideki güncellemelere yanıt olarak alt ilişkideki tüm kümelerin basamaklı bir güncellemesini sağlar. 3. Boş Ayarla, veya boş atama kuralı. Temel ilişkimizi oluşturma ifadesinde, yabancı anahtarları bildirirken referans bütünlüğünü koruma kuralını uygularız. Boş Ayarla, daha sonra bir üst ilişkinin anahtarının güncellenmesi veya bir üst ilişkiden bir demetin silinmesi, alt ilişkinin Null değerlerine izin veren yabancı anahtar niteliklerine otomatik olarak Null değerleri atamayı gerektirir. Bu nedenle, bu tür niteliklerin mevcut olması durumunda kural geçerlidir. Daha önce kullandığımız bir örneğe bakalım. Bize iki temel bağıntı verildiğini varsayalım: "Ebeveynlik"
çocuk ilişkisi
Gördüğünüz gibi, alt ilişki nitelikleri Null değerlere izin verir, dolayısıyla kural Boş Ayarla bu özel durumda geçerlidir. Şimdi önceki örnekte olduğu gibi tuple'ın (..., 1) ana ilişkiden kaldırıldığını ve tuple'ın (..., 2) güncellendiğini varsayalım. Böylece ebeveyn ilişkisi aşağıdaki formu alır: ebeveyn tutumu
Daha sonra çocuk ilişkisinin yabancı anahtarlarını bildirirken referans bütünlüğünü sağlama kuralını uyguladığımızı dikkate alarak Boş Ayarla, çocuk ilişkisi şöyle görünecektir: çocuk ilişkisi
Tuple'a (..., 1) herhangi bir alt ilişki anahtarı tarafından başvurulmadığı için onu silmenin hiçbir sonucu yoktur. Kuralı kullanan temel ilişki oluşturma operatörünün kendisi Boş Ayarla yabancı anahtarları bildirirken ilişki şöyle görünür: Tablo oluştur ebeveyn tutumu Birincil anahtar Tamsayı geçersiz değil birincil anahtar (Birincil anahtar) Tablo oluştur çocuk ilişkisi Yabancı anahtar Tamsayı Null yabancı anahtar (Yabancı anahtar) referanslar Ebeveyn İlişkisi (Birincil_anahtar) güncellemede Set Null Sil Set Null'da Dolayısıyla, referans bütünlüğünü korumak için üç farklı kuralın varlığının, ifadelerde bunu sağladığını görüyoruz. güncellemede и silindiğinde fonksiyonlar değişebilir. Bir çocuk ilişkisine demet eklemenin veya çocuk ilişkilerinin temel değerlerini güncellemenin, bu, referans bütünlüğünün ihlaline, yani sözde sarkan demetlerin görünümüne yol açması durumunda gerçekleştirilmeyeceğinin hatırlanması ve anlaşılması gerekir. Bir alt ilişkiden demetleri hiçbir koşulda kaldırmak, referans bütünlüğünün ihlaline yol açmaz. Diğer temel ilişkilerin yabancı anahtarları bazı özniteliklerini birincil anahtarlar olarak adlandırıyorsa, bir çocuk ilişkisinin referans bütünlüğünü korumak için kendi kurallarıyla aynı anda bir üst ilişki olarak hareket edebilmesi ilginçtir. Programcılar, referans bütünlüğünün yukarıdaki standart kurallar dışında bazı kurallar tarafından uygulanmasını sağlamak istiyorlarsa, referans bütünlüğünü korumak için bu tür standart olmayan kurallar için prosedürel destek, sözde tetikleyicilerin yardımıyla sağlanır. Ne yazık ki, bu kavramın ayrıntılı bir şekilde ele alınması, derslerimizin seyrine inmiyor. 5. Endeks kavramı Temel ilişkilerde anahtarların oluşturulması, otomatik olarak dizinlerin oluşturulmasıyla bağlantılıdır. İndeks kavramını tanımlayalım. Indeks - bu, bu değerlerin meydana geldiği ilişkinin bu demetlerine bağlantıları olan bir anahtarın mutlaka sıralı bir değerler listesini içeren bir sistem veri yapısıdır. Veritabanı yönetim sistemlerinde iki tür dizin vardır: 1) basit. Tek bir öznitelikten temel ilişkinin şema alt şeması için basit bir dizin alınır; 2) bileşik. Buna göre, bir bileşik indeks, birkaç öznitelikten oluşan bir alt şema için bir indekstir. Ancak, basit ve bileşik dizinlere bölünmenin yanı sıra, veritabanı yönetim sistemlerinde dizinlerin benzersiz ve benzersiz olmayan bir bölümü vardır. Yani: 1) benzersiz dizinler, en fazla bir özniteliğe atıfta bulunan dizinlerdir. Benzersiz dizinler genellikle ilişkinin birincil anahtarına karşılık gelir; 2) benzersiz olmayan dizinler, aynı anda birkaç özniteliği eşleştirebilen dizinlerdir. Benzersiz olmayan anahtarlar, genellikle ilişkinin yabancı anahtarlarına karşılık gelir. Dizinlerin benzersiz ve benzersiz olmayan olarak bölünmesini gösteren bir örnek düşünün, yani tablolar tarafından tanımlanan aşağıdaki ilişkileri göz önünde bulundurun:
Burada sırasıyla Birincil anahtar ilişkinin birincil anahtarı, Yabancı anahtar ise yabancı anahtardır. Bu ilişkilerde, Birincil anahtar özniteliğinin dizininin, birincil anahtara, yani bir özniteliğe karşılık geldiği için benzersiz olduğu ve Yabancı anahtar özniteliğinin dizininin benzersiz olmadığı açıktır, çünkü yabancı anahtara karşılık gelir. anahtarlar. Ve "20" değeri, ilişki tablosunun hem birinci hem de üçüncü satırlarına karşılık gelir. Ancak bazen anahtarlardan bağımsız olarak dizinler oluşturulabilir. Bu, sıralama ve arama işlemlerinin performansını desteklemek için veritabanı yönetim sistemlerinde yapılır. Örneğin, demetlerdeki bir dizin değeri için ikili bir arama, yirmi yinelemede veritabanı yönetim sistemlerinde uygulanacaktır. Bu bilgi nereden geldi? Basit hesaplamalarla elde edildiler, yani. aşağıdaki gibi: 106 = (103)2 = 220; Dizinler, veritabanı yönetim sistemlerinde zaten bildiğimiz Create deyimi kullanılarak, ancak yalnızca index anahtar sözcüğünün eklenmesiyle oluşturulur. Böyle bir operatör şöyle görünür: Dizin oluştur dizin adı On temel ilişki adı (özellik adı,..); Burada, virgülle ayrılmış bir argümanı tekrarlama olasılığını belirten tanıdık üstdilsel sembol ",.." görüyoruz, yani bu operatörde çeşitli niteliklere karşılık gelen bir indeks oluşturulabilir. Benzersiz bir dizin bildirmek istiyorsanız, benzersiz anahtar sözcüğü dizin sözcüğünden önce eklersiniz ve ardından temel dizin ilişkisindeki tüm oluşturma ifadesi şu şekilde olur: Benzersiz dizin oluştur dizin adı On temel ilişki adı (özellik adı); Daha sonra, en genel biçimde, isteğe bağlı öğeleri belirleme kuralını hatırlarsak (üst dil sembolü []), temel ilişkideki dizin oluşturma operatörü şöyle görünecektir: [benzersiz] dizin oluştur dizin adı On temel ilişki adı (özellik adı,..); Halihazırda var olan bir dizini temel ilişkiden kaldırmak istiyorsanız, bizim de zaten bildiğimiz Drop operatörünü kullanın: düşüş indeksi {temel ilişki adı. Dizin adı},.. ; Nitelikli dizin adı neden "temel ilişki adı. Dizin adı" burada kullanılıyor? Dizin bırakma operatörü her zaman nitelikli adını kullanır, çünkü dizin adı aynı ilişki içinde benzersiz olmalıdır, ancak daha fazlası olmamalıdır. 6. Temel ilişkilerin değiştirilmesi Çeşitli temel ilişkilerle başarılı ve verimli bir şekilde çalışmak için geliştiricilerin çoğu zaman bu temel ilişkiyi bir şekilde değiştirmesi gerekir. Veritabanı tasarımı uygulamasında en sık karşılaşılan temel değişiklik seçenekleri nelerdir? Bunları sıralayalım: 1) demetlerin eklenmesi. Çoğu zaman, önceden oluşturulmuş bir temel ilişkiye yeni demetler eklemeniz gerekir; 2) nitelik değerlerinin güncellenmesi. Ve programlama pratiğinde bu değişikliğe duyulan ihtiyaç, öncekinden daha da yaygındır, çünkü veritabanınızın argümanları hakkında yeni bilgiler geldiğinde, kaçınılmaz olarak bazı eski bilgileri güncellemeniz gerekecektir; 3) demetlerin çıkarılması. Ve yaklaşık olarak eşit olasılıkla, alınan yeni bilgiler nedeniyle veritabanınızda varlığı artık gerekli olmayan demetleri temel ilişkiden çıkarmak gerekli hale gelir. Bu nedenle, temel ilişkileri değiştirmenin ana noktalarını özetledik. Bu hedeflerin her birine nasıl ulaşılabilir? Veritabanı yönetim sistemlerinde, çoğu zaman yerleşik, temel ilişki değiştirme operatörleri bulunur. Bunları bir sözde kod girişinde tanımlayalım: 1) operatör ekle yeni demetlerin temel ilişkisine. bu operatör Ekle. Şuna benziyor: Takın temel ilişki adı (özellik adı, ..) Değerler (özellik değeri,..); Öznitelik adı ve öznitelik değerinden sonraki üstdilsel sembol ",..", bize bu operatörün temel ilişkiye aynı anda birden çok özniteliğin eklenmesine izin verdiğini söyler. Bu durumda, öznitelik adlarını ve öznitelik değerlerini virgülle ayırarak tutarlı bir sırada listelemelisiniz. Kelimeler içine operatörün genel adı ile birlikte Ekle "içine ekle" anlamına gelir ve parantez içindeki niteliklerin hangi ilişkide ekleneceğini belirtir. Kelimeler Değerler bu ifadede ve bu yeni bildirilen özniteliklere atanan "değerler", "değerler" anlamına gelir; 2) şimdi düşünün güncelleme operatörü temel ilişkideki öznitelik değerleri. Bu operatör denir Güncelleme, İngilizce'den çevrilmiştir ve kelimenin tam anlamıyla "güncelleme" anlamına gelir. Bu operatörün tam genel formunu sözde kod gösterimi ile verelim ve deşifre edelim: Güncelleme temel ilişki adı set {öznitelik adı - öznitelik değeri},.. Nerede şart; Bu nedenle, operatörün anahtar kelimeden sonraki ilk satırında Güncelleme güncellemelerin yapılacağı baz ilişkinin adı yazılır. Set anahtar sözcüğü İngilizce'den "set" olarak çevrilir ve ifadenin bu satırı güncellenecek özniteliklerin adlarını ve karşılık gelen yeni öznitelik değerlerini belirtir. ",.." üst dil sembolünün kullanımından sonra, tek bir ifadede birkaç özelliği aynı anda güncellemek mümkündür. Anahtar kelimeden sonraki üçüncü satırda Nerede bu temel ilişkinin tam olarak hangi özelliklerinin güncellenmesi gerektiğini gösteren bir koşul yazılır; 3) operatör Silizin kaldırmak temel ilişkiden herhangi bir demet. Tam biçimini sözde kodda yazalım ve tüm bireysel sözdizimsel birimlerin anlamını açıklayalım: Sil temel ilişki adı Nerede şart; Kelimeler itibaren operatörün adıyla birlikte Sil "kaldır" olarak tercüme edilir. Ve operatörün ilk satırındaki bu anahtar kelimelerden sonra, herhangi bir demetin çıkarılması gereken temel ilişkinin adı belirtilir. Anahtar kelimeden sonra operatörün ikinci satırında Nerede ("nerede"), temel ilişkimizde artık gerekli olmayan tanımlama gruplarının seçildiği koşulu belirtir. Ders numarası 9. İşlevsel bağımlılıklar 1. Fonksiyonel bağımlılığın kısıtlanması Bir ilişkinin birincil ve aday anahtar bildirimleri tarafından dayatılan benzersizlik kısıtlaması, kavramla ilişkili kısıtlamanın özel bir durumudur. işlevsel bağımlılıklar. İşlevsel bağımlılık kavramını açıklamak için aşağıdaki örneği göz önünde bulundurun. Bize belirli bir oturumun sonuçlarıyla ilgili verileri içeren bir ilişki verilsin. Bu ilişkinin şeması şöyle görünür: Oturum (kayıt defteri numarası, Ad Soyad, Konu, Seviye); "Sınıf defteri numarası" ve "Konu" öznitelikleri (iki öznitelik bir anahtar olarak bildirildiğinden) bu ilişkinin birincil anahtarını oluşturur. Gerçekten de, bu iki nitelik, diğer tüm niteliklerin değerlerini benzersiz bir şekilde belirleyebilir. Ancak, bu anahtarla ilişkilendirilen benzersizlik kısıtlamasına ek olarak, ilişki mutlaka bir not defterinin belirli bir kişiye verilmesi koşuluna tabi olmalıdır ve bu nedenle bu açıdan aynı not defteri numarasına sahip demetler aynı değerleri içermelidir. "Soyadı" niteliklerinin , "Adı ve ikinci adı".
Belirli bir oturumdan sonra bir eğitim kurumunun belirli bir öğrenci veritabanının aşağıdaki parçasına sahipsek, o zaman not defteri numarası 100 olan demetlerde "Soyadı", "Ad" ve "Patronimik" nitelikleri aynıdır, ve "Konu" ve "Değerlendirme" nitelikleri - uyuşmuyor (ki bu anlaşılabilir, çünkü farklı konulardan ve içlerindeki performanstan bahsediyorlar). Bu, "Soyadı", "Ad" ve "Patronimik" niteliklerinin işlevsel olarak bağımlı "Sınıf defteri numarası" özniteliği üzerinde, "Konu" ve "Değerlendirme" öznitelikleri ise işlevsel olarak bağımsızdır. Bu durumda, işlevsel bağımlılık veritabanı yönetim sistemlerinde tablolanan tek değerli bir bağımlılıktır. Şimdi işlevsel bağımlılığın kesin bir tanımını veriyoruz. Tanım: X, Y, S şeması üzerinde tanımlayan, S ilişkisinin şemasının alt şemaları olsun. fonksiyonel bağımlılık diyagramı X → Y ("X ok Y"yi okuyun). tanımlayalım işlevsel bağımlılık kısıtlamaları inv<X → Y> şema S ile ilgili olarak, X alt şemasına izdüşümünde eşleşen herhangi iki demetin, izdüşümde Y alt şemasına da eşleşmesi gerektiğini belirten bir ifade olarak. Aynı tanımı formül biçiminde yazalım: Env<X → Y> r(K) = t1T,2 ∈ r(t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; İlginçtir ki, bu tanım daha önce karşılaştığımız tekli izdüşüm işlemi kavramını kullanır. Gerçekten de, bu işlemi ilişki tablosunun satırlarının değil de iki sütununun birbirine eşitliğini göstermek için kullanmazsanız başka nasıl olur? Bu nedenle, bu işlem açısından yazdık ki, bazı nitelikler veya birkaç nitelik (alt şema X) üzerine izdüşümdeki demetlerin çakışması, Y'nin işlevsel olarak bağımlı olması durumunda, kesinlikle aynı sütun demetlerinin Y alt şemasındaki çakışmasını gerektirecektir. X. Y'nin X'e işlevsel bağımlılığı durumunda, X'in de söylendiğini belirtmek ilginçtir. işlevsel olarak tanımlar Y veya ne Y işlevsel olarak bağımlı X üzerinde. X → Y işlevsel bağımlılık şemasında, X alt devresi sol taraf ve Y alt devresi sağ taraf olarak adlandırılır. Veritabanı tasarımı uygulamasında, işlevsel bağımlılık şemasına genel olarak kısalık için işlevsel bağımlılık denir. Tanımın sonu. Özel durumda, işlevsel bağımlılığın sağ tarafı, yani Y alt şeması, ilişkinin tüm şemasıyla eşleştiğinde, işlevsel bağımlılık kısıtlaması, birincil veya aday anahtar benzersizlik kısıtlaması olur. Yok canım: env r(S) = ∀ t1T,2 ∈ r(t1[K] = t2 [K] → t1(K) = t2(S)), K ⊆ S; Sadece işlevsel bir bağımlılığı tanımlarken, X alt şeması yerine, K anahtarının atamasını almanız ve işlevsel bağımlılığın sağ tarafı, Y alt şeması yerine, tüm S ilişkileri şemasını almanız gerekir, yani, aslında, ilişkilerin anahtarlarının benzersizliği üzerindeki kısıtlama, sağ taraf, ilişki şeması boyunca eşit işlevsel bağımlılık şemaları olduğunda, işlevsel bağımlılığın kısıtlanmasının özel bir durumudur. İşlevsel bağımlılık görüntüsüne ilişkin örnekler: {Hesap defteri numarası} → {Soyadı, Adı, Patronimik}; {not defteri numarası, konu} → {derece}; 2. Armstrong'un çıkarım kuralları Herhangi bir temel ilişki vektör tanımlı fonksiyonel bağımlılıkları sağlıyorsa, o zaman çeşitli özel çıkarım kurallarının yardımıyla bu temel ilişkinin kesinlikle tatmin edeceği başka fonksiyonel bağımlılıklar elde etmek mümkündür. Bu tür özel kurallara iyi bir örnek, Armstrong'un çıkarım kurallarıdır. Ancak Armstrong çıkarım kurallarının kendilerinin analizine geçmeden önce, yeni bir üst dil sembolü olan "├" adını verelim. türetilebilirlik meta-onay sembolü. Bu sembol, kurallar formüle edilirken iki sözdizimsel ifade arasına yazılır ve sağındaki formülün solundaki formülden türetildiğini gösterir. Şimdi Armstrong çıkarım kurallarını aşağıdaki teorem biçiminde formüle edelim. Teorem. Armstrong'un çıkarım kuralları olarak adlandırılan aşağıdaki kurallar geçerlidir. Çıkarım Kuralı 1. ├ X → X; Çıkarım Kuralı 2. X → Y├ X ∪ Z → Y; Çıkarım Kuralı 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Burada X, Y, Z, W, S ilişkisi şemasının keyfi alt şemalarıdır. Türetilebilirlik meta-ifadesi sembolü, öncüller listelerini ve iddialar (sonuçlar) listelerini ayırır. 1. İlk çıkarım kuralına "refleksivite" ve şu şekilde okunur: "kural çıkarılmıştır:" X işlevsel olarak X'i gerektirir "". Bu, Armstrong'un türetme kurallarının en basitidir. Kelimenin tam anlamıyla ince havadan türetilmiştir. Hem sol hem de sağ kısımlara sahip işlevsel bir bağımlılığa denildiğini belirtmek ilginçtir. dönüşlü. Dönüşlülük kuralına göre, dönüşlü bağımlılık kısıtlaması otomatik olarak gerçekleştirilir. 2. İkinci çıkarım kuralına "ikmal" ve şu şekilde okunur: "X işlevsel olarak Y'yi belirlerse, kural türetilir: "X ve Z alt devrelerinin birleşimi işlevsel olarak Y'yi gerektirir"". Tamamlama kuralı, işlevsel bağımlılık kısıtlamasının sol tarafını genişletmenize olanak tanır. 3. Üçüncü çıkarım kuralına "yalancı geçişlilik" ve şu şekilde okunur: "X alt devresi işlevsel olarak Y alt devresini gerektiriyorsa ve Y ve W alt devrelerinin birleşimi işlevsel olarak Z'yi gerektiriyorsa, kural türetilir: "X ve W alt devrelerinin birleşimi işlevsel olarak Z alt devresini belirler"". Sahte geçişlilik kuralı, özel W: = 0 durumuna karşılık gelen geçişlilik kuralını genelleştirir. Bu kuralın biçimsel bir gösterimini verelim: X→Y, Y→Z ├X→Z. Daha önce verilen öncüllerin ve sonuçların, işlevsel bağımlılık şemalarının tanımlarıyla kısaltılmış bir biçimde sunulduğuna dikkat edilmelidir. Genişletilmiş biçimde, aşağıdaki işlevsel bağımlılık kısıtlamalarına karşılık gelirler. Çıkarım Kuralı 1. inv r(S); Çıkarım Kuralı 2. inv r(S) ⇒ inv r(S); Çıkarım Kuralı 3. inv r(S) & inv r(S) ⇒ inv r(S); Çekmek kanıt bu çıkarım kuralları. 1. Kuralın kanıtı refleksivite X alt şeması Y alt devresi ile değiştirildiğinde, doğrudan fonksiyonel bağımlılık kısıtlamasının tanımından çıkar. Gerçekten de, işlevsel bağımlılık kısıtlamasını alın: env r(S) ve içine Y yerine X koyun, şunu elde ederiz: env r(S) ve bu refleksivite kuralıdır. Yansıma kuralı kanıtlanmıştır. 2. Kuralın kanıtı ikmal Fonksiyonel bağımlılığın diyagramlarını açıklayalım. İlk diyagram paket diyagramıdır: öncül: X → Y
İkinci diyagram: sonuç: X ∪ Z → Y
Tuple'lar X ∪ Z'de eşit olsun. O zaman X'te eşitler. Öncüllere göre Y'de de eşit olacaklar. İkmal kuralı kanıtlanmıştır. 3. Kuralın kanıtı sözde geçişlilik Ayrıca, bu özel durumda üç olacak olan diyagramları da göstereceğiz. İlk diyagram ilk öncüldür: 1. öncül: X → Y
2. öncül: Y ∪ W → Z
Ve son olarak, üçüncü diyagram sonuç diyagramıdır: sonuç: X ∪ W → Z
Demetler X ∪ W üzerinde eşit olsun. O zaman hem X hem de W üzerinde eşitler. Öncül 1'e göre, Y'de de eşit olacaklar.Dolayısıyla, Öncül 2'ye göre, Z'de de eşit olacaklar. Sahte geçişlilik kuralı kanıtlanmıştır. Tüm kurallar kanıtlanmıştır. 3. Türetilmiş çıkarım kuralları Gerekirse, yeni işlevsel bağımlılık kuralları türetilebilecek başka bir kural örneği, sözde türetilmiş çıkarım kuralları. Bu kurallar nelerdir, nasıl elde edilir? Bilinmektedir ki, eğer diğerleri, mevcut bazı kurallardan meşru mantıksal yöntemlerle çıkarılıyorsa, o zaman bu yeni kurallara denir. türevler, orijinal kurallarla birlikte kullanılabilir. Bu çok keyfi kuralların, tam olarak Armstrong'un daha önce incelediğimiz çıkarsama kurallarından "türevler" olduğuna özellikle dikkat edilmelidir. İşlevsel bağımlılıkları türetmek için türetilmiş kuralları aşağıdaki teorem biçiminde formüle edelim. Teorem. Aşağıdaki kurallar Armstrong'un çıkarım kurallarından türetilmiştir. Çıkarım Kuralı 1. ├ X ∪ Z → X; Çıkarım Kuralı 2. X → Y, X → Z ├ X ∪ Y → Z; Çıkarım Kuralı 3. X → Y ∪ Z ├ X → Y, X → Z; Burada X, Y, Z, W, önceki durumda olduğu gibi, S ilişkisi şemasının keyfi alt şemalarıdır. 1. İlk türetilmiş kural denir önemsizlik kuralı ve şöyle okur: "Kural türetilmiştir: 'X ve Z alt devrelerinin birleşimi işlevsel olarak X'i gerektirir'". Sol tarafın sağ tarafın bir alt kümesi olduğu işlevsel bir bağımlılığa denir. önemsiz. Önemsizlik kuralına göre, önemsiz bağımlılık kısıtlamaları otomatik olarak uygulanır. İlginç bir şekilde, önemsizlik kuralı, dönüşlülük kuralının bir genellemesidir ve ikincisi gibi, doğrudan işlevsel bağımlılık kısıtlamasının tanımından türetilebilir. Bu kuralın türetilmiş olması tesadüfi değildir ve Armstrong'un kurallar sisteminin eksiksizliği ile ilgilidir. Armstrong'un kurallar sisteminin bütünlüğü hakkında biraz sonra konuşacağız. 2. İkinci türetilmiş kural denir toplama kuralı ve şu şekilde okunur: "X alt devresi Y alt devresini işlevsel olarak belirlerse ve X aynı anda işlevsel olarak Z'yi belirlerse, bu kurallardan şu kural çıkarılır: "X, Y ve Z alt devrelerinin birleşimini işlevsel olarak belirler"". 3. Üçüncü türetilmiş kural denir yansıtma kuralı veya kuraltoplamsallığın tersine çevrilmesi". Aşağıdaki gibidir: "X alt devresi Y ve Z alt devrelerinin birleşimini işlevsel olarak belirlerse, bu kuraldan aşağıdaki kural çıkarılır: "X, Y alt devresini işlevsel olarak belirler ve aynı zamanda X, alt devreyi işlevsel olarak belirler. Z" ", yani, gerçekten, bu türetilmiş kural, tersine çevrilmiş toplamsallık kuralıdır. Aynı sol kısımlara sahip işlevsel bağımlılıklara uygulanan toplama ve yansıtma kurallarının, bağımlılığın sağ kısımlarını birleştirmeye veya tersine bölmeye izin vermesi ilginçtir. Çıkarım zincirleri oluşturulurken, tüm öncüller formüle edildikten sonra, sonuca sağ tarafla işlevsel bir bağımlılığı dahil etmek için geçişlilik kuralı uygulanır. Çekmek kanıt Listelenen keyfi çıkarım kuralları. 1. Kuralın kanıtı önemsiz şeyler. Sonraki tüm deliller gibi bunu da adım adım uygulayalım: 1) elimizde: X → X (Armstrong'un çıkarsama refleksivitesi kuralından); 2) ayrıca elimizde: X ∪ Z → X (önce Armstrong'un çıkarım tamamlama kuralı uygulanarak ve ardından ispatın ilk adımının bir sonucu olarak elde edilir). Önemsizlik kuralı kanıtlanmıştır. 2. Kuralın adım adım kanıtını gerçekleştireceğiz toplanabilirlik: 1) elimizde: X → Y (bu 1. öncüldür); 2) elimizde: X → Z (bu öncül 2'dir); 3) elimizde: Y ∪ Z → Y ∪ Z (Armstrong'un çıkarımın yansıtıcılığı kuralından); 4) elimizde: X ∪ Z → Y ∪ Z (Armstrong'un çıkarımının sözde geçişlilik kuralı uygulanarak ve ardından ispatın birinci ve üçüncü adımlarının bir sonucu olarak elde edilir); 5) elimizde: X ∪ X → Y ∪ Z (Armstrong'un çıkarımın sözde geçişliliği kuralı uygulanarak elde edilir ve ardından ikinci ve dördüncü adımlardan takip edilir); 6) X → Y ∪ Z'ye sahibiz (beşinci adımdan sonra gelir). Toplama kuralı ispatlanmıştır. 3. Ve son olarak kuralın kanıtını oluşturacağız yansıtma: 1) elimizde: X → Y ∪ Z, X → Y ∪ Z (bu bir öncüldür); 2) elimizde: Y → Y, Z → Z (Armstrong'un çıkarım refleksivitesi kuralı kullanılarak türetilmiştir); 3) elimizde: Y ∪ z → y, Y ∪ z → Z (Armstrong'un çıkarsama tamamlama kuralından ve ispatın ikinci adımından elde edilen sonuç); 4) elimizde: X → Y, X → Z (Armstrong'un çıkarımının sözde geçişlilik kuralı uygulanarak ve ardından ispatın birinci ve üçüncü adımlarının bir sonucu olarak elde edilir). Projektivite kuralı kanıtlanmıştır. Tüm türev çıkarım kuralları kanıtlanmıştır. 4. Armstrong kuralları sisteminin eksiksizliği F(S), S ilişki şeması üzerinde tanımlanan belirli bir fonksiyonel bağımlılıklar kümesi olsun. ile belirtmek inv bu işlevsel bağımlılıklar kümesinin dayattığı kısıtlama. Onu da yazalım: env r(S) = ∀X → Y ∈F(S) [env r(S)]. Dolayısıyla, fonksiyonel bağımlılıklar tarafından dayatılan bu kısıtlamalar dizisi şu şekilde deşifre edilir: fonksiyonel bağımlılıklar F(S) kümesine ait X → Y fonksiyonel bağımlılıklar sisteminden herhangi bir kural için, fonksiyonel bağımlılıkların kısıtlaması inv r(S), r(S) ilişkisi kümesi üzerinden tanımlanır. Bir r(S) bağıntısının bu kısıtlamayı sağlamasına izin verin. F(S) kümesi için tanımlanan işlevsel bağımlılıklara Armstrong'un çıkarım kurallarını uygulayarak, daha önce söylediğimiz ve kanıtladığımız gibi, yeni işlevsel bağımlılıklar elde edilebilir. Ve gösterge niteliğinde olan F(S) ilişkisi, Armstrong'un çıkarım kurallarının genişletilmiş biçiminden görülebileceği gibi, bu işlevsel bağımlılıkların kısıtlamalarını otomatik olarak karşılayacaktır. Bu genişletilmiş çıkarım kurallarının genel biçimini hatırlayın: Çıkarım Kuralı 1. inv r(S); Çıkarım Kuralı 2. inv r(S) ⇒ inv<X ∪ Z → Y> r(S); Çıkarım Kuralı 3. inv r(S) & inv ∪ W → Z> r(S) ⇒ inv<X ∪ W→Z>; Akıl yürütmemize dönersek, F(S) kümesini Armstrong kurallarını kullanarak ondan türetilen yeni bağımlılıklarla dolduralım. Artık yeni işlevsel bağımlılıklar almayana kadar bu yenileme prosedürünü uygulayacağız. Bu yapının bir sonucu olarak, adı verilen yeni bir dizi işlevsel bağımlılık elde edeceğiz. kapatma F(S) ayarlayın ve gösterilir F+(S). Aslında, böyle bir isim oldukça mantıklıdır, çünkü biz kişisel olarak, uzun bir inşa yoluyla, var olan işlevsel bağımlılıklar kümesini kendi kendine "kapattık", mevcut olanlardan kaynaklanan tüm yeni işlevsel bağımlılıkları (dolayısıyla "+") ekledik. Unutulmamalıdır ki, bir kapatma inşa etme süreci sonludur, çünkü tüm bu inşaların üzerinde gerçekleştirildiği ilişki şemasının kendisi sonludur. Kapanmanın, kümenin kapanmasının bir üst kümesi olduğunu (aslında daha büyüktür!) ve tekrar kapatıldığında hiçbir şekilde değişmediğini söylemeye gerek yok. Az önce söylenenleri kalıplaşmış bir biçimde yazarsak, şunu elde ederiz: F(K) ⊆ F+(S), [K+(S)]+=F+(S); Ayrıca, Armstrong'un çıkarım kurallarının kanıtlanmış doğruluğundan (yani yasallık, meşruiyet) ve kapanış tanımından, belirli bir fonksiyonel bağımlılıklar kümesinin kısıtlamalarını karşılayan herhangi bir ilişkinin, kapanışa ait bağımlılığın kısıtlamasını tatmin edeceği sonucu çıkar. . X → Y ∈ F+(S) ⇒ ∀r(S) [env r(S) ⇒ env r(S)]; Dolayısıyla, Armstrong'un çıkarım kuralları sistemi için tamlık teoremi, dışsal imaların oldukça meşru ve haklı bir şekilde eşdeğerlik ile değiştirilebileceğini belirtir. (Bu teoremin ispatını ele almayacağız, çünkü ispat sürecinin kendisi bizim özel dersimizde o kadar önemli değildir.) Ders numarası 10. Normal formlar 1. Veritabanı şeması normalleştirmesinin anlamı Bu bölümde ele alacağımız kavram, işlevsel bağımlılıklar kavramıyla ilgilidir, yani veritabanı şemalarını normalleştirmenin anlamı, bir işlevsel bağımlılıklar sistemi tarafından dayatılan kısıtlamalar kavramıyla ayrılmaz bir şekilde bağlantılıdır ve büyük ölçüde bu kavramdan çıkar. Herhangi bir veritabanı tasarımının başlangıç noktası, etki alanını bir veya daha fazla ilişki olarak temsil etmektir ve her tasarım adımında "gelişmiş" özelliklere sahip bir dizi ilişki şeması üretilir. Bu nedenle tasarım süreci, her ardışık normal formun bir anlamda öncekinden daha iyi özelliklere sahip olduğu ilişki kalıplarını normalleştirme sürecidir. Her normal formun belirli bir kısıtlamaları vardır ve bir ilişki, kendi kısıtlamalarını karşılıyorsa, belirli bir normal formdadır. Bir örnek, ilk normal formun kısıtlanmasıdır - ilişkinin tüm niteliklerinin değerleri atomiktir. İlişkisel veritabanı teorisinde, aşağıdaki normal formlar dizisi genellikle ayırt edilir: 1) birinci normal biçim (1 NF); 2) ikinci normal biçim (2 NF); 3) üçüncü normal form (3 NF); 4) Boyce-Codd normal formu (BCNF); 5) dördüncü normal biçim (4 NF); 6) beşinci normal form veya projeksiyon-birleşim normal form (5 NF veya PJ/NF). (Bu ders, temel ilişkilerin ilk dört normal formunun ayrıntılı bir tartışmasını içerir, bu nedenle dördüncü ve beşinci normal formları ayrıntılı olarak analiz etmeyeceğiz.) Normal formların ana özellikleri aşağıdaki gibidir: 1) takip eden her normal form, bir anlamda önceki normal formdan daha iyidir; 2) Bir sonraki normal forma geçerken önceki normal formların özellikleri korunur. Tasarım süreci, normalleştirme yöntemine, yani önceki normal formda olan bir ilişkinin bir sonraki normal formun gereksinimlerini karşılayan iki veya daha fazla ilişkiye ayrıştırılmasına dayanmaktadır (biz bunu normalleştirmemiz gerektiğinde bununla karşılaşacağız). materyali incelerken) veya başka bir temel ilişki). Temel ilişkilerin oluşturulması ile ilgili bölümde bahsedildiği gibi, verilen fonksiyonel bağımlılıklar setleri, temel ilişkilerin şemalarına uygun kısıtlamalar getirir. Bu kısıtlamalar genellikle iki şekilde uygulanır: 1) bildirimsel olarak, yani temel ilişkide çeşitli birincil, aday ve yabancı anahtar türlerini bildirerek (bu en yaygın kullanılan yöntemdir); 2) prosedürel olarak, yani program kodu yazmak (yukarıda bahsedilen tetikleyicileri kullanarak). Basit mantık yardımıyla veritabanı şemalarını normalleştirmenin amacının ne olduğunu anlayabilirsiniz. Veritabanlarını normalleştirmek veya veritabanlarını normal bir forma getirmek, program kodu yazma ihtiyacını en aza indirmek, veritabanı performansını artırmak ve durum ve referans bütünlüğü ile veri bütünlüğünün bakımını kolaylaştırmak için bu tür temel ilişki şemalarını tanımlamak anlamına gelir. Yani, kodu yapmak ve onunla çalışmak, geliştiriciler ve kullanıcılar için mümkün olduğunca basit ve kullanışlı. Normalleştirilmemiş ve normalleştirilmiş bir veritabanının çalışmasını karşılaştırmalı olarak görsel olarak göstermek için aşağıdaki örneği göz önünde bulundurun. Sınav oturumunun sonuçları hakkında bilgi içeren bir temel ilişki kuralım. Daha önce böyle bir veritabanını düşünmüştük. Bu durumda, seçeneği 1 veritabanı şemaları. Oturum (kayıt defteri numarası, Ad Soyad, Konu, Seviye) Bu ilişkide, temel ilişki şeması görüntüsünden de görebileceğiniz gibi, bileşik bir birincil anahtar tanımlanır: Birincil anahtar (ders kitabı numarası, Konu); Ayrıca bu bağlamda, bir işlevsel bağımlılıklar sistemi kurulur: {Hesap defteri numarası} → {Soyadı, Adı, Patronimik}; İşte bu ilişki şemasına sahip bir veritabanının küçük bir parçasının tablo görünümü. Bu parçayı işlevsel bağımlılıkların sınırlamalarını göz önünde bulundurarak zaten kullandık, bu nedenle örneğini kullanarak bu konuyu anlamak bizim için oldukça kolay olacaktır.
Burada, duruma göre verilerin bütünlüğünü korumak için, yani, örneğin soyadı değiştirirken, işlevsel bağımlılık sisteminin {sınıf defteri numarası} → {Soyadı, Adı, Patronimik} kısıtlamasını yerine getirmek için, Bu temel ilişkinin tüm demetlerine bakmak ve sırayla gerekli değişiklikleri girmek gerekir. Ancak, bu oldukça zahmetli ve zaman alıcı bir süreç olduğundan (özellikle büyük bir eğitim kurumunun veri tabanı ile uğraşıyorsak), veri tabanı yönetim sistemleri geliştiricileri, bu sürecin otomatikleştirilmesi gerektiği sonucuna varmışlardır, yani , otomatik yapılır. Şimdi, bu (ve diğer herhangi bir) işlevsel bağımlılığın yerine getirilmesi üzerindeki kontrol, temel ilişkideki çeşitli anahtarların doğru beyanı ve bunun sözde ayrıştırılması (yani, bir şeyi birkaç bağımsız parçaya bölme) kullanılarak otomatik olarak organize edilebilir. ilişki. O halde mevcut "Oturum" ilişki şemamızı iki şemaya ayıralım: Sadece belirli bir eğitim kurumunun öğrencileri hakkında bilgi içeren "Öğrenciler" şeması ve son geçmiş oturum hakkında bilgi içeren "Oturum" şeması. Daha sonra gerekli bilgileri kolayca alabileceğimiz şekilde anahtarları bildireceğiz. Bu yeni ilişki şemalarının anahtarlarıyla nasıl görüneceğini gösterelim. opsiyon 2 veritabanı şemaları. öğrenciler (kayıt defteri numarası, Ad Soyad), Birincil anahtar (sınıf defteri numarası). Oturum (Kayıt defteri numarası, Konu, Seviye), Birincil anahtar (sınıf defteri numarası, Konu), Yabancı anahtar (not defteri numarası) referansları Öğrenciler (not defteri numarası). Şimdi elimizde ne var? "Öğrenciler" ile ilgili olarak, "Sınıf defteri numarası" birincil anahtarı diğer üç özelliği işlevsel olarak belirler: "Soyadı", "Ad" ve "Patronimik". Ve "Oturum" ile ilgili olarak, "Sınıf Defteri No., Konu" bileşik birincil anahtarı da açık bir şekilde, yani, bu ilişki şemasının son niteliğini - "Puan" ı tam anlamıyla işlevsel olarak tanımlar. Ve bu iki ilişki arasındaki bağlantı kurulmuştur: "Öğrenci" ilişkisinde aynı ismin özniteliğine atıfta bulunan "Oturum" ilişkisinin "Defter No" dış anahtarı üzerinden gerçekleştirilir ve istendiğinde, gerekli tüm bilgileri sağlar. Şimdi ikinci seçeneğe karşılık gelen veritabanı şemalarını belirlemeye karşılık gelen tablolarla temsil edilen ilişkilerin nasıl görüneceğini gösterelim.
Böylece, işlevsel bağımlılıkların getirdiği kısıtlamalar açısından normalleştirmenin amacının, temel ilişkilerin çeşitli birincil, aday ve yabancı anahtar türlerinin bildirimlerini kullanarak herhangi bir veritabanına gerekli işlevsel bağımlılıkları dayatma ihtiyacı olduğunu görüyoruz. 2. İlk Normal Form (1NF) Veritabanı tasarımının ve veritabanı yönetim şemalarının geliştirilmesinin ilk aşamalarında, en üretken ve rasyonel kod birimleri olarak basit ve açık öznitelikler kullanıldı. Daha sonra basit ve bileşik niteliklerin yanı sıra tek değerli ve çok değerli niteliklerle birlikte kullanılırlar. Bu kavramların her birinin anlamını açıklayalım. Bileşik NiteliklerBasit olanların aksine, birkaç basit nitelikten oluşan niteliklerdir. Çok değerli özellikler, tek değerli olanların aksine, birden çok değeri temsil eden niteliklerdir. İşte basit, bileşik, tek değerli ve çok değerli niteliklere örnekler. İlişkiyi temsil eden aşağıdaki tabloyu göz önünde bulundurun:
Burada "Telefon" özniteliği basit, açık ve "Adres" özniteliği basit ama çok değerlidir. Şimdi farklı özelliklere sahip başka bir tablo düşünün:
Tablo ile temsil edilen bu ilişkide, "Telefonlar" özniteliği basit ama çok değerlidir ve "Adresler" özniteliği hem bileşik hem de çok değerlidir. Genel olarak, basit veya bileşik niteliklerin çeşitli kombinasyonları mümkündür. Farklı durumlarda, ilişkileri temsil eden tablolar genel olarak şöyle görünebilir:
Programcılar, temel ilişki şemalarını normalleştirirken en yaygın dört normal form türünden birini kullanabilir: birinci normal form (1NF), ikinci normal form (2NF), üçüncü normal form (3NF) veya Boyce-Codd normal form (NFBC) . Açıklığa kavuşturmak için: NF kısaltması, İngilizce Normal Form ifadesinin kısaltmasıdır. Resmi olarak, yukarıdakilere ek olarak, başka normal form türleri de vardır, ancak yukarıdakiler en popüler olanlardan biridir. Şu anda, veritabanı geliştiricileri, kod yazmayı karmaşıklaştırmamak, yapısını aşırı yüklememek ve kullanıcıları şaşırtmamak için bileşik ve çok değerli niteliklerden kaçınmaya çalışıyorlar. Bu düşüncelerden, ilk normal formun tanımı mantıksal olarak takip eder. Tanım. Herhangi bir temel ilişki Birincil normal form ancak ve ancak bu ilişkinin şeması yalnızca basit ve yalnızca tek değerli nitelikler içeriyorsa ve zorunlu olarak aynı anlambilime sahipse. Normalleştirilmiş ve normalleştirilmemiş ilişkiler arasındaki farkları görsel olarak açıklamak için bir örnek düşünün. Aşağıdaki şema ile normalleştirilmemiş bir ilişki olsun. Bu durumda, seçeneği 1 üzerinde tanımlanmış basit bir birincil anahtarla ilişki şemaları: Çalışanlar (personel numarası, Soyadı, Adı, Patronimik, Görev kodu, Telefonlar, Kabul veya işten çıkarılma tarihi); Birincil anahtar (personel numarası); Bu ilişki şemasında hangi hataların olduğunu listeleyelim, yani bu şemayı normalleştirilmemiş yapan işaretleri adlandıracağız: 1) "Soyadı Adı Patronimik" özelliği bileşiktir, yani. heterojen unsurlardan oluşur; 2) "Telefonlar" özelliği birden çok değerlidir, yani değeri bir değerler kümesidir; 3) "Kabul veya işten çıkarılma tarihi" niteliğinin açık bir anlamı yoktur, yani. ikinci durumda hangi tarihin girildiği açık değildir. Örneğin, bir tarihin anlamını daha kesin olarak tanımlamak için ek bir öznitelik eklenirse, bu özniteliğin değeri anlamsal olarak açık olacaktır, ancak yine de her çalışan için belirtilen tarihlerden yalnızca birini saklamak mümkün olmaya devam eder. Bu ilişkiyi normal forma getirmek için ne yapılması gerekiyor? İlk olarak, bu çok bileşik öznitelikleri ve aynı zamanda bileşik anlambilimli öznitelikleri dışlamak için bileşik öznitelikleri basit olanlara bölmek gerekir. İkinci olarak, bu ilişkiyi ayrıştırmak gerekir, yani çok değerli nitelikleri dışlamak için onu birkaç yeni bağımsız ilişkiye bölmek gerekir. Böylece, yukarıdakilerin hepsini dikkate alarak, "Çalışanlar" ilişkisini ayrıştırarak ilk normal biçime veya 1NF'ye indirgedikten sonra, üzerlerinde ayarlanan birincil ve yabancı anahtarlarla aşağıdaki ilişkilerden oluşan bir sistem elde edeceğiz. Bu durumda, seçeneği 2 ilişkiler: Çalışanlar (personel numarası, Soyadı, Adı, Patronimik, Görev kodu, Kabul tarihi, İşten çıkarılma tarihi); Birincil anahtar (personel numarası); telefonlar (Personel Numarası, Telefon); Birincil anahtar (personel numarası, Telefon); Yabancı anahtar (personel numarası) referansları Çalışanlar (personel numarası); Peki ne görüyoruz? "Soyadı Adı Patronimik" bileşik özelliği artık ilişkimizde değil, bunun yerine "Soyadı", "Ad" ve "Patronimik" olmak üzere üç basit özellik var, bu nedenle ilişkinin "anormalliği" için bu neden hariç tutuldu. . Ek olarak, anlamı belirsiz olan "İşe alma veya işten çıkarma tarihi" özniteliği yerine, artık her biri açık bir anlambilime sahip "Kabul tarihi" ve "İşten çıkarma tarihi" olmak üzere iki özniteliğe sahibiz. Dolayısıyla "Çalışan" ilişkimizin normal formda olmamasının ikinci nedeni de güvenle ortadan kaldırılmıştır. Ve son olarak, "Çalışanlar" ilişkisinin normalleştirilmemesinin son nedeni, çok değerli "Telefonlar" özelliğinin varlığıdır. Bu özellikten kurtulmak için tüm ilişkiyi ayrıştırmak gerekiyordu. Bu ayrıştırmanın bir sonucu olarak, "Telefonlar" niteliği, genel olarak "Çalışanlar" orijinal ilişkisinden çıkarıldı, ancak ikinci bir ilişki kuruldu - iki özelliğin bulunduğu "Telefonlar": "çalışanın personel numarası" ve "Telefon" ", yani tüm nitelikler - yine basit, ilk normal forma ait olma koşulu karşılanır. Bu "Çalışan numarası" ve "Telefon" öznitelikleri, "Telefonlar" ilişkisinin birleşik birincil anahtarını oluşturur ve "Çalışan numarası" özniteliği de "Çalışanlar"da aynı adı taşıyan özniteliği ifade eden bir yabancı anahtardır. "ilişki, yani ilişkili olarak birincil anahtarın "Telefonlar" özelliği "personel numarası" da "Çalışanlar" ilişkisinin birincil anahtarına atıfta bulunan bir yabancı anahtardır. Böylece iki ilişki arasında bir bağlantı sağlanır. Bu bağlantıyı kullanarak, herhangi bir çalışanın personel sayısına göre telefonlarının tüm listesini, çok fazla çaba ve zaman harcamadan, bileşik özniteliklerin kullanımına başvurmadan görüntüleyebilirsiniz. Sistemle ilgili işlevsel bağımlılıklar olsaydı, yukarıdaki tüm dönüşümlerden sonra normalizasyonun tamamlanmayacağını unutmayın. Bununla birlikte, bu özel örnekte, işlevsel bağımlılık kısıtlamaları yoktur, bu nedenle bu ilişkinin daha fazla normalleştirilmesi gerekli değildir. 3. İkinci Normal Form (2NF) İkinci normal form veya 2NF tarafından ilişkilere daha güçlü gereksinimler uygulanır. Bunun nedeni, ikinci normal ilişki biçiminin tanımının, birinci normal biçimin aksine, işlevsel bağımlılıklar üzerinde bir kısıtlamalar sisteminin varlığını ima etmesidir. Tanım. Temel ilişki içindedir ikinci normal form belirli bir işlevsel bağımlılıklar kümesine göre, ancak ve ancak birinci normal biçimdeyse ve ayrıca, anahtar olmayan her öznitelik, işlevsel olarak her bir anahtara tamamen bağımlıysa. Bu tanımda anahtar olmayan özellik ilişkinin herhangi bir birincil veya aday anahtarında yer almayan herhangi bir ilişki niteliğidir. Bir anahtara tam işlevsel bağımlılık, o anahtarın herhangi bir parçasına işlevsel bir bağımlılık olmadığı anlamına gelir. Bu nedenle, şimdi, bir ilişkiyi normalleştirirken, ilişkinin birinci normal formda olması için koşulların yerine getirilmesini, yani niteliklerinin basit ve açık olmasını sağlamanın yanı sıra, ilgili ikinci koşulun yerine getirilmesini de izlemeliyiz. fonksiyonel bağımlılıkların kısıtlamaları. Basit anahtarlarla (birincil ve aday) ilişkilerin kesinlikle ikinci normal formda olduğu açıktır. Aslında, bu durumda anahtarın bir parçasına bağımlılık basitçe mümkün görünmemektedir, çünkü anahtarın ayrı bölümleri yoktur. Şimdi, önceki konunun pasajında olduğu gibi, normalleştirilmemiş bir ilişki şeması örneğini ve normalleştirme sürecinin kendisini ele alalım. Bu durumda, seçeneği 1 ilişki şemaları: izleyiciler (Bina No., Oditoryum No., Alan metrekare m, No. kolordu servis komutanı); Birincil anahtar (korpus numarası, izleyici numarası); Ek olarak, aşağıdaki fonksiyonel bağımlılık sistemi tanımlanmıştır: {Kolordu sayısı} → {Kolordu hizmet komutanının sayısı}; Ne görüyoruz? Bu ilişkinin "İzleyici"nin ilk normal formda kalması için tüm koşullar karşılanır, çünkü bu ilişkinin her bir özelliği açık ve basittir. Ancak, anahtar olmayan her öğenin işlevsel olarak anahtara tamamen bağımlı olması şartı yerine getirilmemiştir. Neden? Niye? Evet, çünkü "Kolordu komutanının sayısı" özelliği işlevsel olarak "Kolordu sayısı, seyirci sayısı" bileşik anahtarına değil, bu anahtarın bir kısmına, yani özniteliğe bağlıdır. "Kolordu sayısı". Gerçekten de, hangi komutanın kendisine atandığını tamamen belirleyen kolordu numarasıdır ve sırayla kolordu komutanının personel sayısı herhangi bir oditoryum numarasına bağlı olamaz. Bu nedenle, normalleştirmemizin ana görevi, anahtarların, özellikle "Hayır. Bunu başarmak için, bir önceki paragrafta olduğu gibi, ilişkinin ayrışmasını tekrar uygulamamız gerekecek. Böylece, aşağıdaki ilişkiler sistemi, seçeneği 2 "İzleyici" ilişkisi, orijinal ilişkiden birkaç yeni bağımsız ilişkiye ayrıştırılarak elde edildi: Kolordu (Gövde No., kolordu personel komutanının sayısı); Birincil anahtar (durum numarası); izleyiciler (Bina No., Oditoryum No., Alan metrekare m); Birincil anahtar (korpus numarası, izleyici numarası); Yabancı anahtar (vaka numarası) referansları Vakalar (vaka numarası); Şimdi ne görüyoruz? "Corpus" anahtar olmayan özniteliği ile ilgili olarak, "Kolordu komutanının personel numarası" tamamen işlevsel olarak "Kolordu numarası" birincil anahtarına bağlıdır. Burada ikinci normal formdaki bağıntıyı bulma koşulu tamamen karşılanmıştır. Şimdi ikinci ilişkinin - "İzleyici" ile ilgili değerlendirmeye geçelim. "Kitle" ile ilgili olarak, "Vaka #" birincil anahtar özelliği, aynı zamanda "Vaka" ilişkisinin birincil anahtarına atıfta bulunan bir yabancı anahtardır. Bu bağlamda, "Alan sq. m" anahtar olmayan özniteliği, "Bina #, Oditoryum #" bileşik birincil anahtarının tamamına tamamen bağlıdır ve hiçbir parçasına bağlı değildir, hatta bağımlı olamaz. Böylece, orijinal ilişkiyi ayrıştırarak, ikinci normal formun tanımındaki tüm koşulların tam olarak karşılandığı sonucuna vardık. Bu örnekte, tüm işlevsel bağımlılık gereksinimleri, birincil anahtarların (burada aday anahtar yok) ve yabancı anahtarların bildirilmesiyle uygulanır. Bu nedenle, daha fazla normalleştirmeye gerek yoktur. 4. Üçüncü Normal Form (3NF) Bakacağımız bir sonraki normal form, üçüncü normal formdur (veya 3NF). Birinci normal formun yanı sıra ikinci normal formun aksine, üçüncüsü, ilişki ile birlikte bir fonksiyonel bağımlılıklar sisteminin atanmasını ima eder. Üçüncü normal biçime indirgenmesi için bir ilişkinin hangi özelliklere sahip olması gerektiğini formüle edelim. Tanım. Temel ilişki içindedir üçüncü normal form belirli bir işlevsel bağımlılıklar kümesine göre, ancak ve ancak ikinci normal formdaysa ve anahtar olmayan her öznitelik tamamen işlevsel olarak yalnızca anahtarlara bağlıysa. Bu nedenle, üçüncü normal formun gereksinimleri, birleşik bile olsa, birinci ve ikinci normal formların gereksinimlerinden daha güçlüdür. Aslında, üçüncü normal formda, anahtar olmayan her nitelik anahtara ve anahtarın tamamına bağlıdır ve anahtardan başka hiçbir şeye bağlıdır. Üçüncü normal forma normalleştirilmemiş bir ilişki getirme sürecini gösterelim. Bunu yapmak için bir örnek düşünün: üçüncü normal formda olmayan bir ilişki. Bu durumda, seçeneği 1 "Çalışanlar" ilişkisinin şemaları: Çalışanlar (personel numarası, Soyadı, Adı, Patronimik, Pozisyon Kodu, Maaş); Birincil anahtar (personel numarası); Ek olarak, bu "Çalışanlar" ilişkisinin üzerinde aşağıdaki işlevsel bağımlılıklar sistemi ayarlanır: {Pozisyon kodu} → {Maaş}; Gerçekten de, bir kural olarak, maaş miktarı, yani. ücret miktarı, doğrudan pozisyona ve dolayısıyla ilgili veritabanındaki koduna bağlıdır. Bu nedenle, "Çalışanlar" ilişkisi üçüncü normal formda değildir, çünkü anahtar olmayan "Maaş" özelliğinin işlevsel olarak tamamen "Pozisyon kodu" niteliğine bağlı olduğu ortaya çıkar, ancak bu nitelik kilit bir özellik değildir. İlginç bir şekilde, herhangi bir ilişki, bundan önceki iki biçimle tam olarak aynı şekilde, yani ayrıştırma yoluyla üçüncü normal biçime indirgenir. "Çalışanlar" ilişkisini ayrıştırdıktan sonra, aşağıdaki yeni bağımsız ilişkiler sistemini elde ederiz: Bu durumda, seçeneği 2 "Çalışanlar" ilişkisinin şemaları: pozisyonlar (pozisyon kodu, Aylık maaş); Birincil anahtar (konum kodu); Çalışanlar (personel numarası, Soyadı, Adı, Patronimik, Pozisyon kodu); Birincil anahtar (konum kodu); Yabancı anahtar (Pozisyon kodu) referansları Pozisyonlar (Pozisyon kodu); Şimdi, görebildiğimiz gibi, "Pozisyon" ile ilgili olarak, anahtar olmayan "Maaş" niteliği, işlevsel olarak tamamen basit birincil anahtar "Pozisyon kodu"na ve yalnızca bu anahtara bağlıdır. "Çalışanlar" ile ilgili olarak, "Soyadı", "Ad", "Patronimik" ve "Görev Kodu" gibi anahtar olmayan dört özelliğin de tamamen işlevsel olarak basit birincil anahtar "İstihdam Numarası"na bağlı olduğunu unutmayın. Bu açıdan "Pozisyon Kimliği" özelliği, "Pozisyonlar" ilişkisinin birincil anahtarına atıfta bulunan bir yabancı anahtardır. Bu örnekte, tüm gereksinimler basit birincil ve yabancı anahtarlar bildirilerek uygulanır, bu nedenle daha fazla normalleştirme gerekmez. Pratikte kişinin genellikle veri tabanlarını üçüncü normal biçime getirmekle yetindiğini bilmek ilginç ve faydalıdır. Aynı zamanda, aynı ilişkinin diğer özniteliklerine anahtar özniteliklerin bazı işlevsel bağımlılıkları dayatılmayabilir. Bu tür standart olmayan işlevsel bağımlılıklar için destek, daha önce bahsedilen tetikleyiciler kullanılarak (yani, prosedürel olarak uygun program kodunun yazılmasıyla) uygulanır. Ayrıca, tetikleyiciler bu ilişkinin demetleri ile çalışmalıdır. 5. Boyce-Codd Normal Formu (NFBC) Boyce-Codd normal formu, üçüncü normal formdan hemen sonra "karmaşıklık" içinde gelir. Bu nedenle, Boyce-Codd normal formu bazen basitçe olarak da adlandırılır. güçlü üçüncü normal form (veya güçlendirilmiş 3 NF). Neden güçlendirildi? Boyce-Codd normal formunun tanımını formüle ediyoruz: Tanım. Temel ilişki içindedir Boyce normal formu - kodd ancak ve ancak üçüncü normal formdaysa ve herhangi bir anahtar olmayan öznitelik işlevsel olarak herhangi bir anahtara tamamen bağımlı değil, herhangi bir anahtar özniteliği işlevsel olarak herhangi bir anahtara tamamen bağımlı olmalıdır. Bu nedenle, anahtar olmayan niteliklerin aslında anahtarın tamamına ve anahtardan başka hiçbir şeye bağlı olmaması şartı, anahtar nitelikler için de geçerlidir. Boyce-Codd normal formundaki bir ilişkide, ilişki içindeki tüm fonksiyonel bağımlılıklar, anahtarların bildirilmesiyle empoze edilir. Bununla birlikte, veritabanı ilişkileri Boyce-Codd formuna indirgenirken, çeşitli ilişkilerin öznitelikleri arasındaki bağımlılıkların işlevsel bağımlılıklar olmadığı durumlar mümkündür. Farklı ilişkilerin demetleri üzerinde çalışan tetikleyicilerle bu tür işlevsel bağımlılıkları desteklemek, tetikleyiciler tek bir ilişkinin demetleri üzerinde çalıştığında üçüncü normal form durumunda olduğundan daha zordur. Diğer şeylerin yanı sıra, veritabanı yönetim sistemleri tasarlama pratiği, temel ilişkiyi Boyce-Codd normal formuna getirmenin her zaman mümkün olmadığını göstermiştir. Belirtilen anormalliklerin nedeni, ikinci normal formun ve üçüncü normal formun gereksinimlerinin, diğer olası anahtarların bileşenleri olan özniteliklerin birincil anahtarına minimum işlevsel bağımlılık gerektirmemesidir. Bu problem, tarihsel olarak Boyce-Codd normal formu olarak adlandırılan ve birkaç örtüşen olası anahtarın varlığı durumunda üçüncü normal formun bir iyileştirmesi olan normal form ile çözülür. Genel olarak, veritabanı şeması normalleştirme, veritabanı bütünlüğünü koruyan kontrol ve yedekleme sayısını azalttığı için veritabanı yönetim sisteminin gerçekleştirmesi için veritabanı güncellemelerini daha verimli hale getirir. İlişkisel bir veritabanı tasarlarken, hemen hemen her zaman veritabanındaki tüm ilişkilerin ikinci normal biçimini elde edersiniz. Sık sık güncellenen veritabanlarında genellikle ilişkinin üçüncü normal biçimini sağlamaya çalışırlar. Boyce-Codd normal formu çok daha az dikkat çeker, çünkü pratikte, bir ilişkinin birkaç bileşik örtüşen aday anahtara sahip olduğu durumlar nadirdir. Yukarıdakilerin tümü, Boyce-Codd normal formunu program kodu geliştirirken kullanmak için çok uygun yapmaz, bu nedenle, daha önce belirtildiği gibi, pratikte geliştiriciler genellikle kendilerini veritabanlarını üçüncü normal forma getirmekle sınırlarlar. Bununla birlikte, kendi oldukça meraklı bir özelliği de vardır. Mesele şu ki, bir ilişkinin üçüncü normal formda olduğu ancak Boyce-Codd normal formunda olmadığı durumlar uygulamada son derece nadirdir, yani üçüncü normal forma indirildikten sonra, genellikle tüm fonksiyonel bağımlılıklar birincil, aday ve yabancı anahtarlar, bu nedenle işlevsel bağımlılıkları desteklemek için tetikleyicilere gerek yoktur. Bununla birlikte, işlevsel bağımlılıklarla bağlantılı olmayan bütünlük kısıtlamalarını desteklemek için tetikleyicilere duyulan ihtiyaç devam etmektedir. 6. Normal formların yuvalanması Normal formların yuvalanması ne anlama geliyor? Normal formların yuvalanması - bu, zayıflamış ve güçlendirilmiş form kavramlarının birbirine göre oranıdır. Normal formların yuvalanması, tamamen ilgili tanımlarından kaynaklanmaktadır. Bildiğimiz normal formların iç içe geçme ilişkisini gösteren bir diyagram hayal edelim:
Zayıflamış ve güçlendirilmiş normal form kavramlarını birbirine göre özel örneklerle açıklayalım. Birinci normal biçim, ikinci normal biçime göre (ve diğer tüm normal biçimlere göre de) zayıflar. Gerçekten de, geçtiğimiz tüm normal formların tanımlarını hatırlayarak, her normal formun gereksinimlerinin, ilk normal forma ait olma gereksinimini içerdiğini görebiliriz (sonuçta, sonraki her tanıma dahil edilmiştir). İkinci normal form, birinci normal formdan daha güçlüdür, ancak üçüncü normal formdan ve Boyce-Codd normal formundan daha zayıftır. Aslında, ikinci normal forma ait olmak üçüncünün tanımına dahildir ve ikinci formun kendisi de birinci normal formu içerir. Boyce-Codd normal formu, yalnızca üçüncü normal forma göre değil, aynı zamanda ondan önceki tüm diğer forma göre de güçlendirilir. Ve üçüncü normal biçim, sadece Boyce-Codd normal biçimine göre zayıflar. Ders No. 11. Veritabanı şemalarının tasarlanması Mantıksal düzeyde tasarım yaparken veritabanı şemalarını soyutlamanın en yaygın yolu, sözde varlık-ilişki modeli. Ayrıca bazen denir acil durum modeli, burada ER, kelimenin tam anlamıyla "varlık - ilişki" olarak tercüme edilen İngilizce Varlık - İlişki ifadesinin kısaltmasıdır. Bu tür modellerin elemanları varlık sınıfları, onların nitelikleri ve ilişkileridir. Bu unsurların her birinin açıklamalarını ve tanımlarını vereceğiz. varlık sınıfı nesne yönelimli programlama anlamında yöntemsiz bir nesne sınıfı gibidir. Fiziksel katmana taşınırken, varlık sınıfları, belirli veritabanı yönetim sistemleri için temel ilişkisel veritabanı ilişkilerine dönüştürülür. Temel ilişkilerin kendileri gibi, kendi özelliklerine sahiptirler. Şimdi verilen nesnelerin daha kesin ve kesin bir tanımını verelim. sınıf ortak niteliklere, işlemlere, ilişkilere ve anlambilime sahip bir nesne koleksiyonunun adlandırılmış açıklaması olarak adlandırılır. Grafiksel olarak, bir sınıf genellikle bir dikdörtgen olarak tasvir edilir. Her sınıfın, onu diğer tüm sınıflardan benzersiz bir şekilde ayıran bir adı (metin dizesi) olması gerekir. sınıf özelliği bu özelliğin örneklerinin alabileceği değerler kümesini tanımlayan bir sınıfın adlandırılmış özelliğidir. Bir sınıf herhangi bir sayıda özniteliğe sahip olabilir (özellikle, hiçbir özniteliği olamaz). Bir öznitelik tarafından ifade edilen bir özellik, verilen sınıfın tüm nesneleri için ortak olan modellenmiş varlığın bir özelliğidir. Dolayısıyla bir nitelik, bir nesnenin durumunun bir soyutlamasıdır. Herhangi bir sınıf nesnesinin herhangi bir özelliğinin bir değeri olmalıdır. Sözde ilişkiler, yabancı anahtarların bildirimi kullanılarak uygulanır (daha önce benzer fenomenlerle karşılaşmıştık), yani ilgili olarak, başka bir ilişkinin birincil veya aday anahtarlarına atıfta bulunan yabancı anahtarlar bildirilir. Ve bu sayede, birkaç farklı bağımsız temel ilişki, veritabanı adı verilen tek bir sisteme "bağlanır". Ayrıca, varlık-ilişki modelinin grafiksel temelini oluşturan diyagram, birleşik modelleme dili UML kullanılarak tasvir edilmiştir. Nesne yönelimli modelleme dili UML'ye (veya Birleşik Modelleme Dili) çok sayıda kitap ayrılmıştır ve bunların çoğu Rusça'ya çevrilmiştir (ve bazıları Rus yazarlar tarafından yazılmıştır). Genel olarak, UML farklı sistem türlerini modellemenize izin verir: tamamen yazılım, tamamen donanım, yazılım-donanım, karma, açıkça insan faaliyetlerini içeren vb. Ancak, diğer şeylerin yanı sıra, daha önce de belirttiğimiz gibi, UML dili, ilişkisel veritabanlarını tasarlamak için aktif olarak kullanılmaktadır. Bunun için dilin küçük bir kısmı (sınıf diyagramları) kullanılır ve o zaman bile tam olarak kullanılmaz. İlişkisel veritabanı tasarımı açısından, modelleme yetenekleri ER diyagramlarından çok farklı değildir. Ayrıca ilişkisel veritabanı tasarımı bağlamında, ER diyagramlarının kullanımına dayalı yapısal tasarım yöntemleri ile UML dilinin kullanımına dayalı nesne yönelimli yöntemlerin temel olarak sadece terminolojide farklılık gösterdiğini göstermek istedik. ER modeli kavramsal olarak UML'den daha basittir, daha az kavram, terim ve uygulama seçeneğine sahiptir. ER modellerinin farklı sürümleri özellikle ilişkisel veritabanı tasarımını desteklemek için geliştirildiğinden ve ER modelleri bir ilişkisel veritabanı tasarımcısının gerçek ihtiyaçlarının ötesine geçen neredeyse hiçbir özellik içermediğinden bu anlaşılabilir bir durumdur. UML, nesne dünyasına aittir. Bu dünya, ilişkisel dünyadan çok daha karmaşık (isterseniz daha anlaşılmaz, daha kafa karıştırıcı). UML, herhangi bir şeyin birleşik nesne yönelimli modellemesi için kullanılabildiğinden, dil, ilişkisel bir veritabanı tasarımı perspektifinden gereksiz olan çok sayıda kavram, terim ve kullanım senaryosu içerir. İlişkisel veritabanlarının tasarımı için gerçekten gerekli olanı sınıf diyagramlarının genel mekanizmasından çıkarırsak, tam olarak farklı bir gösterim ve terminolojiye sahip ER diyagramlarını elde ederiz. UML'de sınıf adları oluşturulurken rastgele bir harf, sayı ve hatta noktalama işareti kombinasyonuna izin verilmesi ilginçtir. Ancak uygulamada, sınıf isimleri olarak her biri büyük harfle başlayan kısa ve anlamlı sıfat ve isimlerin kullanılması tavsiye edilir. (Diyagram kavramını dersimizin bir sonraki paragrafında daha ayrıntılı olarak ele alacağız.) 1. Çeşitli tahvil türleri ve çoklukları Veritabanı şemalarının tasarımındaki ilişkiler arasındaki ilişki, varlık sınıflarını birbirine bağlayan çizgiler olarak tasvir edilir. Ayrıca, bağlantının uçlarından her biri, ad (yani bağlantı türü) ve bağlantıdaki sınıfın rolünün çokluğu ile karakterize edilebilir (ve genellikle olmalıdır). Çokluk kavramlarını ve bağlantı türlerini daha ayrıntılı olarak ele alalım. çokluk (çokluk), belirli bir role sahip bir varlık sınıfının kaç özniteliğinin bir tür ilişkinin her örneğine katılabileceğini veya katılması gerektiğini gösteren bir özelliktir. Bir ilişki rolünün önemliliğini belirlemenin en yaygın yolu, doğrudan belirli bir sayı veya aralık belirtmektir. Örneğin, "1" belirtmek, belirli bir role sahip her sınıfın bu bağlantının bir örneğine katılması gerektiğini ve bu role sahip sınıfın tam olarak bir nesnesinin bağlantının her örneğine katılabileceği anlamına gelir. "0..1" aralığının belirtilmesi, belirli bir role sahip sınıfın tüm nesnelerinin bu ilişkinin herhangi bir örneğine katılması gerekmediğini, ancak ilişkinin her örneğine yalnızca bir nesnenin katılabileceğini gösterir. Çokluk hakkında daha ayrıntılı konuşalım. Veritabanı tasarım sistemlerindeki tipik, en yaygın kardinaliteler aşağıdaki kardinalitelerdir: 1) 1 - karşılık gelen ucundaki bağlantının çokluğu bire eşittir; 2) 0... 1 - bu gösterim biçimi, belirli bir bağlantının karşılık gelen ucundaki çokluğunun bir'i geçemeyeceği anlamına gelir; 3) 0... ∞ - bu çokluk basitçe “çok” olarak deşifre edilir. Kural olarak "çok" kelimesinin "hiçbir şey" anlamına gelmesi ilginçtir; 4) 1... ∞ - “bir veya daha fazla” çokluğuna bu isim verilmiştir. Farklı bağlantı çokluğu ile çalışmayı göstermek için basit bir diyagram örneği verelim.
Bu şemaya göre, her bilet gişesinin birçok bileti olduğu ve sırayla her biletin bir (ve bundan fazla olmayan) bir bilet gişesinde bulunduğu kolayca anlaşılabilir. Şimdi en yaygın bağlantı türlerini veya adlarını düşünün. Bunları sıralayalım: 1) 1: 1 - bu atama bağlantıya verildi "bire bir", yani, olduğu gibi, iki kümenin bire bir yazışmasıdır; 2) 1 : 0... ∞ - bu, " gibi bir bağlantının tanımıdırbirden çok". Kısaca, böyle bir ilişkiye "1: M" denir. Daha önce ele alınan şemada, görebileceğiniz gibi, böyle bir adla bir ilişki vardır; 3) 0... ∞ : 1 - bu önceki bağlantının tersine çevrilmesidir veya " tipinde bir bağlantıdırçoktan bire"; 4) 0... ∞ : 0... ∞, " gibi bir bağlantının tanımıdırçoktan çoka", yani bağlantının her bir ucunda birçok özellik vardır; 5) 0... 1 : 0... 1 - bu, daha önce tanıtılan "bire bir" tipi bağlantıya benzer bir bağlantıdır, buna "birden fazla değil birden fazla"; 6) 0... 1 : 0... ∞ - bu, birden çoğa bağlantıya benzer bir bağlantıdır, buna "birden çoğa değil" denir; 7) 0... ∞ : 0... 1 - bu, çoktan bire bağlantı tipine benzer bir bağlantıdır, buna " denirçoğu birden fazla değil". Görüldüğü gibi son üç bağlantı, dersimizde bir, iki ve üç sayıları altında listelenen bağlantılardan "bir"in çokluğu "birden fazla olmayan" çokluğu ile değiştirilerek elde edilmiştir. 2. Diyagramlar. Grafik türleri Ve şimdi nihayet doğrudan diyagramların ve türlerinin değerlendirilmesine geçelim. Genel olarak, mantıksal modelin üç düzeyi vardır. Bu seviyeler, veri yapısı hakkındaki bilgilerin temsil derinliği bakımından farklılık gösterir. Bu seviyeler aşağıdaki diyagramlara karşılık gelir: 1) sunum şeması; 2) anahtar diyagram; 3) tam özellik diyagramı. Bu diyagram türlerinin her birini analiz edelim ve veri yapısı hakkındaki bilgilerin sunum derinliğindeki farklılıklarının anlamını ayrıntılı olarak açıklayalım. 1. Sunum diyagramı. Bu tür diyagramlar yalnızca en temel varlık sınıflarını ve bunların ilişkilerini tanımlar. Bu tür diyagramlardaki anahtarlar hiç tanımlanmayabilir ve buna bağlı olarak bağlantılar hiçbir şekilde kişiselleştirilmeyebilir. Bu nedenle, genellikle kaçınılmasına veya varsa, ince ayar yapılmasına rağmen, çoktan çoğa ilişkiler kabul edilebilir. Bileşik ve çok değerli nitelikler de tamamen geçerlidir, ancak daha önce bu niteliklerle temel ilişkilerin herhangi bir normal forma indirgenmediğini yazmıştık. İlginç bir şekilde, incelediğimiz üç diyagram türünden yalnızca son tür (tam nitelik diyagramı), onunla sunulan verilerin normal bir biçimde olduğunu varsayar. Oysa önceden düşünülen sunum şeması ve sıradaki anahtar diyagram, bu türden hiçbir şeyi ima etmemektedir. Bu tür diyagramlar genellikle sunumlar için kullanılır (dolayısıyla adları sunumdur, yani aşırı ayrıntıya ihtiyaç duyulmayan sunumlar, gösteriler için kullanılır). Bazen veri tabanlarını tasarlarken, bu özel veri tabanının bilgi ile uğraştığı konu alanındaki uzmanlara danışmak gerekir. Daha sonra sunum diyagramları da kullanılır, çünkü programlamadan uzak bir meslekteki uzmanlardan gerekli bilgileri almak için belirli detayların aşırı açıklığa kavuşturulması hiç gerekli değildir. 2. Anahtar şeması. Sunum diyagramlarından farklı olarak, anahtar diyagramlar zorunlu olarak tüm varlık sınıflarını ve bunların ilişkilerini yalnızca birincil anahtarlar cinsinden tanımlar. Burada çoktan çoğa ilişkiler zaten zorunlu olarak ayrıntılıdır (yani, bu tür ilişkiler saf formlarında burada belirtilemez). Çok değerli özniteliklere sunum diyagramında olduğu gibi izin verilir, ancak bunlar bir anahtar diyagramda mevcutsa, genellikle bağımsız varlık sınıflarına dönüştürülürler. Ancak, ilginç bir şekilde, belirsiz olmayan nitelikler hala eksik olarak temsil edilebilir veya bileşik olarak tanımlanabilir. Sunum ve anahtar diyagramlar gibi diyagramlarda hala geçerli olan bu "özgürlükler", bir sonraki diyagram türünde izin verilmez, çünkü bunlar taban ilişkisinin normalleştirilmediğini belirler. Bu nedenle, gelecekte anahtar diyagramların, önceden tanımlanmış varlık sınıflarında yalnızca "asılı" nitelikleri varsaydığı sonucuna varabiliriz, yani. bir sunum şeması kullanarak, en gerekli varlık sınıflarını tanımlamak ve ardından bir anahtar diyagramı kullanarak her şeyi eklemek yeterlidir. ona gerekli nitelikler ve en önemli tüm bağlantıları belirtin. 3. Tam özellik diyagramı. Tam öznitelik diyagramları, yukarıdaki tüm varlık sınıflarını, bunların niteliklerini ve bu varlık sınıfları arasındaki ilişkileri en ayrıntılı şekilde açıklar. Kural olarak, bu tür grafikler üçüncü normal formdaki verileri temsil eder, bu nedenle, bu tür grafikler tarafından açıklanan temel ilişkilerde, bileşik veya çok değerli niteliklere izin verilmemesi doğaldır, tıpkı tanecikli olmayan çok-to- birçok ilişki. Bununla birlikte, tam öznitelik çizelgelerinin hala bir dezavantajı vardır, yani veri sunumu açısından çizelgelerin en eksiksizleri olarak adlandırılamazlar. Örneğin, tam öznitelik diyagramlarını kullanırken belirli veritabanı yönetim sistemlerinin özelliği hala dikkate alınmaz ve özellikle veri türü, yalnızca gerekli mantıksal modelleme düzeyi için gerekli olduğu ölçüde belirtilir. 3. İlişkilendirmeler ve anahtar geçiş Biraz önce, veritabanlarında ilişkilerin ne olduğundan bahsetmiştik. Özellikle, ilişkinin yabancı anahtarları bildirilirken ilişki kurulmuştur. Ancak kursumuzun bu bölümünde artık temel ilişkilerden değil, varlıkların yazar kasalarından bahsediyoruz. Bu anlamda ilişki kurma süreci hala çeşitli anahtarların bildirimleri ile ilişkilendirilmektedir ancak şimdi varlık sınıflarının anahtarlarından bahsediyoruz. Yani, ilişki kurma süreci, bir varlık sınıfının basit veya bileşik birincil anahtarının başka bir sınıfa aktarılmasıyla ilişkilidir. Böyle bir transfer süreci de denir anahtar geçiş. Bu durumda birincil anahtarları aktarılan varlık sınıfına denir. ebeveyn sınıfıve yabancı anahtarların taşındığı varlıkların sınıfına denir. çocuk sınıfı varlıklar. Bir alt varlık sınıfında, anahtar nitelikler yabancı anahtar niteliklerinin durumunu alır ve kendi birincil anahtarının oluşumuna katılabilir veya katılmayabilir. Bu nedenle, bir birincil anahtar bir üst öğeden bir alt varlık sınıfına geçirildiğinde, alt sınıfta üst sınıfın birincil anahtarına başvuran bir yabancı anahtar görünür. Anahtar geçişinin formüle edilmiş gösteriminin rahatlığı için, aşağıdaki anahtar işaretleri sunuyoruz: 1) PK - birincil anahtarın (birincil anahtar) herhangi bir niteliğini bu şekilde belirteceğiz; 2) FK - bu işaretleyici ile bir yabancı anahtarın (yabancı anahtar) özelliklerini belirteceğiz; 3) PFK - böyle bir işaretleyici ile, birincil / yabancı anahtarın bir niteliğini, yani bazı varlık sınıfının tek birincil anahtarının parçası olan ve aynı zamanda aynı varlık sınıfının bazı yabancı anahtarının bir parçası olan herhangi bir niteliği belirteceğiz. . Böylece, bir varlık sınıfının PK ve FK işaretleyicileri ile nitelikleri bu sınıfın birincil anahtarını oluşturur. Ve FK işaretli nitelikler ve PFK, bu varlık sınıfının bazı yabancı anahtarlarının bir parçasıdır. Genel olarak, anahtarlar farklı şekillerde taşınabilir ve bu tür farklı her durumda bir tür bağlantı ortaya çıkar. Öyleyse, anahtar geçiş şemasına bağlı olarak ne tür bağlantıların olduğunu düşünelim. Toplamda, iki temel geçiş planı vardır. 1. Taşıma şeması ∀PK (PK |→PFK); Bu girdide, "|→" sembolü "geçer" kavramı anlamına gelir, yani yukarıdaki formül aşağıdaki gibi okunacaktır: ana varlık sınıfının birincil anahtarının PK'sinin herhangi bir (her) özniteliği, ana varlık sınıfına aktarılır (geçer). birincil anahtar PFTabii ki, bu sınıf için de bir yabancı anahtar olan K alt varlık sınıfı. Bu durumda, istisnasız olarak ana varlık sınıfının her bir anahtar niteliğinin alt varlık sınıfına taşınması gerektiği gerçeğinden bahsediyoruz. Bu tür bağlantı denir tanımlama, çünkü ana varlık sınıfının anahtarı tamamen alt varlıkların tanımlanmasında yer alır. Tanımlayıcı türdeki bağlantılar arasında, iki olası bağımsız bağlantı türü daha vardır. Dolayısıyla, iki tür tanımlayıcı bağlantı vardır: 1) tamamen tanımlama. Tanımlayıcı bir ilişkinin, yalnızca ana varlık sınıfının taşınan birincil anahtarının özniteliklerinin alt varlık sınıfının birincil (ve yabancı) anahtarını tamamen oluşturması durumunda tam olarak tanımlayıcı olduğu söylenir. Tam olarak tanımlayıcı bir ilişkiye bazen denir kategorik, çünkü tam olarak tanımlayıcı bir ilişki, tüm kategorilerdeki alt varlıkları tanımlar; 2) tam olarak tanımlayamıyorum. Tanımlayıcı bir ilişki, yalnızca ana varlık sınıfının taşınan birincil anahtarının nitelikleri, alt varlık sınıfının birincil (ve aynı zamanda yabancı) anahtarını yalnızca kısmen oluşturuyorsa, eksik tanımlayıcı olarak adlandırılır. Böylece, işaretleyicili anahtara ek olarak PFK ayrıca PK olarak işaretlenmiş bir anahtara sahip olacaktır. Bu durumda, alt varlık sınıfının yabancı anahtarı PFK'si, ana varlık sınıfının birincil anahtarı PK tarafından tamamen belirlenecektir, ancak bu çocuk ilişkisinin birincil anahtarı PK, üst öğenin birincil anahtarı PK tarafından belirlenmeyecektir. varlık sınıfı, kendi başına olacaktır. 2. Göç planı ∃PK (PK |→ FK); Böyle bir geçiş şeması aşağıdaki gibi okunmalıdır: geçiş sırasında alt varlık sınıfının zorunlu anahtar olmayan özniteliklerine aktarılan ana varlık sınıfının birincil anahtar öznitelikleri vardır. Bu nedenle, bu durumda, önceki durumda olduğu gibi bazılarının ve hepsinin değil, ana varlık sınıfının birincil anahtar niteliklerinin alt varlık sınıfına aktarıldığı gerçeğinden bahsediyoruz. Ek olarak, önceki geçiş şeması, aynı zamanda bir yabancı anahtar haline gelen alt ilişkinin birincil anahtarına geçişi tanımlamışsa, o zaman son geçiş türü, üst varlık sınıfının birincil anahtar niteliklerinin normale geçiş yaptığını belirler. , başlangıçta anahtar olmayan öznitelikler, bundan sonra yabancı anahtar statüsü kazanır. Bu tür bağlantı denir tanımlayıcı olmayan, çünkü gerçekten de, ana anahtar alt varlıkların oluşumuna tamamen dahil değildir, onları tanımlamaz. Tanımlayıcı olmayan ilişkiler arasında, iki olası ilişki türü de ayırt edilir. Bu nedenle, tanımlayıcı olmayan ilişkiler aşağıdaki iki türdendir: 1) mutlaka tanımlayıcı olmayan. Tanımlayıcı olmayan ilişkilerin, yalnızca ve ancak bir alt varlık sınıfının tüm geçiş anahtar nitelikleri için Null değerlerinin yasaklanması durumunda tanımlayıcı olmadığı söylenir; 2) isteğe bağlı olarak tanımlayıcı olmayan. Tanımlayıcı olmayan ilişkilerin, yalnızca alt varlık sınıfının bazı geçiş anahtar nitelikleri için boş değerlere izin veriliyorsa, tanımlayıcı olmadıkları söylenir. Sunulan materyalin sistemleştirilmesi ve anlaşılması görevini kolaylaştırmak için yukarıdakilerin tümünü aşağıdaki tablo şeklinde özetliyoruz. Ayrıca bu tabloda, hangi ilişki türlerinin ("birden fazla değil", "çoktan bire", "birden fazlaya çok") hangi tür ilişkilere (tam olarak tanımlayıcı, tam olarak değil) karşılık geldiğine ilişkin bilgilere yer vereceğiz. tanımlayıcı, mutlaka tanımlayıcı değil, mutlaka tanımlayıcı değil). Böylece, ebeveyn ve alt varlık sınıfları arasında, ilişkinin türüne bağlı olarak aşağıdaki ilişki türü kurulur.
Yani, sonuncusu hariç tüm durumlarda referansın boş olmadığını (null değil) → 1 olduğunu görüyoruz. Sonuncusu hariç tüm durumlarda bağlantının üst ucunda, çokluğun "bir" olarak ayarlandığı eğilimine dikkat edin. Bunun nedeni, bu ilişkiler durumlarında yabancı anahtarın değerinin (yani, tam olarak tanımlama, tam olarak tanımlamama ve zorunlu olarak ilişki türlerini tanımlamama), mutlaka birincil anahtarın değerine karşılık gelmesi (ve dahası, tek) olmasıdır. ana varlık sınıfı. Ve ikinci durumda, yabancı anahtarın değerinin Null değerine (FK: boş geçerlilik bayrağı) eşit olabileceği gerçeğinden dolayı, çokluk, ebeveyn sonunda "birden fazla değil" olarak ayarlanır. ilişki. Analizimizi daha da yürütüyoruz. Bağlantının alt ucunda, ilki hariç her durumda, çokluk "çok" olarak ayarlanır. Bunun nedeni, ikinci durumda olduğu gibi eksik tanımlama nedeniyle (veya ikinci ve üçüncü durumlarda hiç böyle bir tanımlama olmaması), ana varlık sınıfının birincil anahtarının değerinin, değerler arasında tekrar tekrar ortaya çıkabilmesidir. alt sınıfın yabancı anahtarının. Ve ilk durumda, ilişki tamamen tanımlayıcıdır, bu nedenle ana varlık sınıfının birincil anahtarının nitelikleri, alt varlık sınıfının anahtarlarının nitelikleri arasında yalnızca bir kez ortaya çıkabilir. Ders No. 12. Varlık sınıflarının ilişkileri Dolayısıyla, diyagramlar ve türleri, çokluklar ve ilişki türleri ve ayrıca anahtar göçün türleri gibi üzerinden geçtiğimiz tüm kavramlar, şimdi bize aynı ilişkiler hakkında, ancak zaten belirli sınıflar arasındaki materyali gözden geçirmemizde yardımcı olacaktır. varlıklar. Bunların arasında, göreceğimiz gibi, çeşitli türden bağlantılar da vardır. 1. Hiyerarşik özyinelemeli ilişki Ele alacağımız varlık sınıfları arasındaki ilk ilişki türü, sözde hiyerarşik özyinelemeli ilişki. Hiç özyineleme (ya özyinelemeli bağlantı) bir varlık sınıfının kendisiyle ilişkisidir. Bazen, yaşam durumlarına benzetilerek, böyle bir bağlantıya "balık kancası" da denir. Hiyerarşik özyinelemeli ilişki (ya da sadece hiyerarşik özyineleme) "en fazla bire çok" türündeki herhangi bir özyinelemeli ilişkidir. Hiyerarşik özyineleme en yaygın olarak verileri bir ağaç yapısında depolamak için kullanılır. Hiyerarşik bir özyinelemeli ilişki belirtilirken, üst varlık sınıfının birincil anahtarı (bu özel durumda aynı zamanda bir alt varlık sınıfı olarak da işlev görür), aynı varlık sınıfının zorunlu anahtar olmayan özniteliklerine bir yabancı anahtar olarak geçirilmelidir. Bütün bunlar, "hiyerarşik özyineleme" kavramının mantıksal bütünlüğünü korumak için gereklidir. Böylece, yukarıdakilerin hepsini dikkate alarak, hiyerarşik özyinelemeli bir ilişkinin ancak mutlaka tanımlayıcı değil ve başkası değil, çünkü başka tür bir ilişki kullanılmış olsaydı, yabancı anahtar için Null değerler geçersiz olur ve özyineleme sonsuz olur. Niteliklerin aynı varlık sınıfında aynı ad altında iki kez görünemeyeceğini hatırlamak da önemlidir. Bu nedenle, taşınan anahtarın niteliklerine sözde rol adı verilmelidir. Böylece, hiyerarşik bir özyinelemeli ilişkide, bir düğümün nitelikleri, doğrudan atası olan düğümün birincil anahtarına isteğe bağlı bir referans olan bir yabancı anahtarla genişletilir. İlişkisel bir veri modelinde hiyerarşik özyineleme uygulayan bir sunum ve anahtar diyagramlar oluşturalım ve bir tablo biçimi örneği verelim. Önce bir sunum şeması oluşturalım:
Şimdi daha ayrıntılı bir anahtar şema oluşturalım:
Hiyerarşik özyinelemeli bir ilişki gibi bir ilişki türünü açıkça gösteren bir örnek düşünün. Bir önceki örnekte olduğu gibi "Ancestor Code" ve "Node Code" özniteliklerinden oluşan aşağıdaki varlık sınıfı bize verelim. İlk olarak, bu varlık sınıfının bir tablo gösterimini gösterelim:
Şimdi bu varlık sınıfını temsil eden bir diyagram oluşturalım. Bunu yapmak için, bunun için gerekli tüm bilgileri tablodan seçiyoruz: "bir" kodlu düğümün atası mevcut değil veya tanımlı değil, bundan "bir" düğümünün bir köşe olduğu sonucuna varıyoruz. Aynı düğüm "bir", "iki" ve "üç" kodlu düğümlerin atasıdır. Sırayla, "iki" kodlu düğümün iki çocuğu vardır: "dört" kodlu düğüm ve "beş" kodlu düğüm. Ve "üç" kodlu düğümün yalnızca bir çocuğu var - "altı" kodlu düğüm. O halde, yukarıdakilerin hepsini göz önünde bulundurarak, bir önceki tabloda yer alan verilerle ilgili bilgileri yansıtan bir ağaç yapısı oluşturalım:
Böylece ağaç yapılarını hiyerarşik özyinelemeli bir ilişki kullanarak temsil etmenin gerçekten uygun olduğunu gördük. 2. Ağ özyinelemeli iletişim Varlık sınıflarının kendi aralarındaki ağ özyinelemeli bağlantısı, deyim yerindeyse, daha önce içinden geçtiğimiz hiyerarşik özyinelemeli bağlantının çok boyutlu bir benzeridir. Yalnızca hiyerarşik özyineleme "en fazla bire çok" özyinelemeli bir ilişki olarak tanımlandıysa, o zaman ağ özyineleme yalnızca "çoktan çoğa" türünden aynı özyinelemeli ilişkiyi temsil eder. Bu bağlantıya her iki tarafta birçok varlık sınıfı katıldığından, buna ağ bağlantısı denir. Hiyerarşik özyineleme ile benzer şekilde zaten tahmin edebileceğiniz gibi, ağ özyineleme türündeki bağlantılar, grafik veri yapılarını temsil etmek için tasarlanmıştır (hatırladığımız gibi, yalnızca ağaç yapılarının uygulanması için hiyerarşik bağlantılar kullanılır). Ancak, ağ özyineleme türünün bağlantısında, "çoktan çoğa" türündeki bağlantılar belirtildiğinden, bunların ek ayrıntıları olmadan yapılması imkansızdır. Bu nedenle, şemadaki tüm çoktan çoğa ilişkileri iyileştirmek için, Ata-Alçadan ilişkisinin üst veya alt öğelerine yapılan tüm başvuruları içeren yeni bir bağımsız varlık sınıfı oluşturmak gerekli hale gelir. Böyle bir sınıf genellikle denir ilişkisel varlık sınıfı. Bizim özel durumumuzda (dersimizde dikkate alınacak veritabanlarında), birleştirici varlık kendi ek özelliklerine sahip değildir ve arama, çünkü Ata-Torun ilişkilerini bunlara atıfta bulunarak adlandırır. Bu nedenle, ana bilgisayarları temsil eden varlık sınıfının birincil anahtarı, ilişkisel varlık sınıflarına iki kez geçirilmelidir. Bu sınıfta, taşınan anahtarlar birlikte bir bileşik birincil anahtar oluşturmalıdır. Yukarıdakilerden, ağ özyineleme kullanırken bağlantı kurmanın tamamen tanımlayıcı olmaması ve başka bir şey olmaması gerektiği sonucuna varabiliriz. Tıpkı hiyerarşik özyinelemeli bir ilişki kullanırken olduğu gibi, bir ilişki olarak ağ özyinelemesini kullanırken, hiçbir öznitelik aynı varlık sınıfında aynı ad altında iki kez görünemez. Bu nedenle, geçen sefer olduğu gibi, geçiş anahtarının tüm niteliklerinin rol adını alması özellikle şart koşulmuştur. Ağ özyinelemeli iletişimin çalışmasını göstermek için, bir ilişkisel veri modelinde ağ özyinelemesini uygulayan bir sunum ve anahtar diyagramlar oluşturalım. Bir sunum şemasıyla başlayalım:
Şimdi daha ayrıntılı bir anahtar diyagram oluşturalım:
Burada ne görüyoruz? Ve bu anahtar diyagramdaki her iki bağlantının da “çoka bir” bağlantı olduğunu görüyoruz. Üstelik “0… ∞” çokluğu ya da “çok” çokluğu, varlıkların adlandırma sınıfının karşı karşıya olduğu bağlantının sonundadır. Aslında çok sayıda bağlantı vardır, ancak hepsi "Düğümler" varlık sınıfının birincil anahtarı olan tek bir düğüm koduna atıfta bulunur. Ve son olarak, ağ özyinelemesi gibi bir varlık sınıfı tarafından bu tür bir bağlantının çalışmasını gösteren bir örneği ele alalım. Bağlantılar hakkında bilgi içeren bir adlandırma varlık sınıfının yanı sıra, bazı varlık sınıflarının tablo şeklinde bir temsilini verelim. Gelin bu tablolara bir göz atalım. Düğüm:
Bağlantılar:
Aslında, yukarıdaki gösterim ayrıntılıdır: burada kodlanmış grafik yapısını kolayca yeniden oluşturmak için gerekli tüm bilgileri verir. Örneğin, "bir" kodlu düğümün sırasıyla "iki", "üç" ve "dört" kodlu üç çocuğu olduğunu hiçbir engel olmadan görebiliriz. Ayrıca, "iki" ve "üç" kodlu düğümlerin hiç alt öğesi olmadığını ve "dört" kodlu bir düğümün ("bir" düğümünün yanı sıra, "bir", "iki" ve üç". Yukarıda verilen varlık sınıfları tarafından verilen bir grafik çizelim:
Dolayısıyla, az önce oluşturduğumuz grafik, bir ağ özyineleme tipi bağlantı kullanılarak varlık sınıflarının bağlandığı verilerdir. 3. Dernek Özel derslerimizin dikkate alınmasına dahil edilen tüm bağlantı türlerinden sadece ikisi özyinelemeli bağlantılardır. Bunları zaten dikkate almayı başardık, bunlar sırasıyla hiyerarşik ve ağ özyinelemeli bağlantılar. Göz önünde bulundurmamız gereken diğer tüm ilişki türleri özyinelemeli değildir, ancak kural olarak birkaç ebeveyn ve birkaç alt varlık sınıfının ilişkisini temsil eder. Ayrıca, tahmin edebileceğiniz gibi, ebeveyn ve alt varlık sınıfları artık hiçbir zaman çakışmayacaktır (aslında artık özyinelemeden bahsetmiyoruz). Dersin bu bölümünde tartışılacak olan bağlantıya çağrışım denir ve tam olarak özyinelemeli olmayan bağlantı tipine atıfta bulunur. Yani bağlantı denilen bağlantı, birden çok ana varlık sınıfı ile bir alt varlık sınıfı arasında bir ilişki olarak uygulanır. Ve aynı zamanda, ilginç olan bu ilişki, çeşitli türlerdeki ilişkilerle tanımlanır. Ayrıca, ağ özyinelemesinde olduğu gibi, ilişkilendirme sırasında yalnızca bir ana varlık sınıfı olabileceğini, ancak böyle bir durumda bile, alt varlık sınıfından gelen ilişkilerin sayısının en az iki olması gerektiğini belirtmekte fayda var. İlginç bir şekilde, ilişkilendirmede ve ağ özyinelemesinde özel türde varlık sınıfları vardır. Böyle bir sınıfa bir örnek, bir alt varlık sınıfıdır. Gerçekten de, genel durumda, bir dernekte, bir alt varlık sınıfına denir. ilişkisel varlık sınıfı. Bir ilişkisel varlık sınıfının kendi ek özniteliklerine sahip olmadığı ve yalnızca ana varlık sınıflarından birincil anahtarlarla birlikte göç eden öznitelikleri içerdiği özel durumda, böyle bir sınıfa denir. adlandırma varlıkları sınıfı. Gördüğünüz gibi, bir ağ özyinelemeli bağlantıda ilişkisel ve adlandırma varlıkları kavramıyla neredeyse mutlak bir analoji vardır. Çoğu zaman, çoktan çoğa ilişkileri iyileştirmek (çözmek) için bir ilişkilendirme kullanılır. Bu ifadeyi örnekleyelim. Örneğin, belirli bir hastanede belirli bir doktoru kabul etme planını açıklayan aşağıdaki sunum şemasını verelim:
Bu diyagram, kelimenin tam anlamıyla, hastanede çok sayıda doktor ve çok sayıda hasta olduğu ve doktorlar ve hastalar arasında başka bir ilişki ve yazışma olmadığı anlamına gelir. Bu nedenle, elbette, böyle bir veri tabanı ile, hastane yönetimi için farklı hastalar için farklı doktorlarla nasıl randevu ayarlanacağı asla net olmayacaktır. Burada kullanılan çoktan çoğa ilişkilerinin, çeşitli doktorlar ve hastalar arasındaki ilişkiyi somutlaştırmak için basitçe detaylandırılması gerektiği açıktır, başka bir deyişle, tüm doktorların ve hastalarının randevu takvimini rasyonel olarak düzenlemek için. hastane. Şimdi, mevcut çoktan çoğa ilişkileri zaten detaylandırdığımız daha ayrıntılı bir anahtar diyagram oluşturalım. Bunu yapmak için, buna göre yeni bir varlık sınıfı tanıtacağız, buna bir ilişkisel varlık sınıfı olarak hareket edecek "Al" diyeceğiz (daha sonra bunun neden sadece bir adlandırma sınıfı değil de bir ilişkisel varlık sınıfı olacağını göreceğiz. daha önce bahsettiğimiz varlıklar). Yani anahtar diyagramımız şöyle görünecek:
Böylece, şimdi yeni "Alma" sınıfının neden bir adlandırma varlıkları sınıfı olmadığını açıkça görebilirsiniz. Sonuçta, bu sınıfın kendi ek "Tarih - Saat" özniteliği vardır, bu nedenle, tanıma göre, yeni tanıtılan "Reception" sınıfı bir ilişkisel varlıklar sınıfıdır. Bu sınıf, "Doktorlar" ve "Hasta" varlık sınıflarını şu veya bu randevunun gerçekleştirildiği zaman aracılığıyla birbirleriyle "ilişkilendirir", bu da böyle bir veritabanıyla çalışmayı çok daha kolay hale getirir. Böylece, "Tarih - Saat" özelliğini tanıtarak, çeşitli doktorlar için çok ihtiyaç duyulan çalışma programını tam anlamıyla düzenledik. Ayrıca, "Reception" varlık sınıfının "Doctor's Code" harici birincil anahtarının, "Doctors" varlık sınıfının aynı adlı birincil anahtarına atıfta bulunduğunu görüyoruz. Ve benzer şekilde, "Reception" varlık sınıfının harici birincil anahtarı "Hasta Kodu", "Hasta" varlık sınıfındaki aynı ada sahip birincil anahtara atıfta bulunur. Bu durumda, doğal olarak, "Doctors" ve "Patient" varlık sınıfları üst öğedir ve birleştirici varlık sınıfı "Reception" ise tek alt öğedir. Önceki sunum şemasındaki çoktan çoğa ilişkisinin artık tamamen ayrıntılı olduğunu görebiliriz. Yukarıdaki sunum şemasında gördüğümüz çoktan çoğa ilişki yerine, iki çoktan çoğa ilişkimiz var. İlk ilişkinin alt ucunda "çok" çokluğu vardır, bu da kelimenin tam anlamıyla "Resepsiyon" varlık sınıfının birçok doktoru olduğu anlamına gelir (hepsi hastanede). Ve bu ilişkinin ebeveyn ucunda "bir"in çokluğu var, bu ne anlama geliyor? Bu, "Reception" varlık sınıfında, her belirli doktorun mevcut kodlarının her birinin süresiz olarak birçok kez ortaya çıkabileceği anlamına gelir. Nitekim hastanedeki programda aynı doktorun kodu farklı gün ve saatlerde birçok kez geçmektedir. Ve işte aynı kod, ancak zaten "Doctors" varlık sınıfında, bir kez ve yalnızca bir kez ortaya çıkabilir. Gerçekten de, tüm hastane doktorları listesinde (ve "Doktorlar" varlık sınıfı böyle bir listeden başka bir şey değildir), her bir doktorun kodu yalnızca bir kez bulunabilir. Benzer bir şey, "Hasta" üst sınıfı ile "Hasta" alt sınıfı arasındaki ilişkide olur. Tüm hastane hastaları listesinde ("Hastalar" varlık sınıfında), her belirli hastanın kodu yalnızca bir kez yer alabilir. Ancak diğer yandan, randevu programında ("Resepsiyon" varlık sınıfında), belirli bir hastanın her kodu keyfi olarak birçok kez ortaya çıkabilir. Bu yüzden bağın uçlarındaki çokluklar bu şekilde düzenlenmiştir. İlişkisel bir veri modelinde bir ilişkilendirmenin uygulanmasına bir örnek olarak, isteğe bağlı danışman katılımıyla müşteri ve yüklenici arasındaki toplantıların zamanlamasını tanımlayan bir model oluşturalım. Sunum diyagramı üzerinde durmayacağız çünkü diyagramların yapımını tüm detaylarıyla düşünmemiz gerekiyor ve sunum diyagramı böyle bir imkan sağlayamıyor. Öyleyse, müşteri, yüklenici ve danışman arasındaki ilişkinin özünü yansıtan bir anahtar diyagram oluşturalım.
Öyleyse, yukarıdaki anahtar diyagramın ayrıntılı bir analizine başlayalım. İlk olarak, "Graph" sınıfı bir ilişkisel varlıklar sınıfıdır, ancak önceki örnekte olduğu gibi, adlandırılmış varlıklar sınıfı değildir, çünkü anahtarlarla birlikte kendisine göç etmeyen bir özniteliğe sahiptir. kendi özniteliği. Bu, "Tarih - Saat" özelliğidir. İkinci olarak, "Chart" "Customer code", "Executor code" ve "Date - Time" alt varlık sınıfının özniteliklerinin bu varlık sınıfının birleşik birincil anahtarını oluşturduğunu görüyoruz. "Danışman Kodu" özelliği, yalnızca "Grafik" varlık sınıfının yabancı anahtarıdır. Lütfen bu özelliğin değerleri arasında Null değerlere izin verdiğini unutmayın, çünkü duruma göre toplantıda bir danışmanın bulunması gerekli değildir. Ayrıca, üçüncü olarak, ilk iki bağlantının (mevcut üç bağlantıdan) tamamen tanımlayıcı olmadığını not ediyoruz. Yani, tam olarak tanımlamaz, çünkü her iki durumda da geçiş anahtarı ("Müşteri kodu" ve "Yürütücü kodu" birincil anahtarları) "Grafik" varlık sınıfının birincil anahtarını tamamen oluşturmaz. Gerçekten de, bileşik birincil anahtarın bir parçası olan "Tarih - Saat" özniteliği kalır. Bu eksik tanımlayıcı bağların her ikisinin de sonunda, "bir" ve "çok" çoklukları işaretlenmiştir. Bu, (doktorlar ve hastalarla ilgili örnekte olduğu gibi) müşterinin veya icracının kodunun farklı varlık sınıflarında belirtilmesi arasındaki farkı göstermek için yapılır. Gerçekten de, "Grafik" varlık sınıfında, herhangi bir müşteri veya yüklenici kodu, istendiği kadar çok kez ortaya çıkabilir. Bu nedenle, çocuk, bağlantının sonunda çok sayıda "çok" vardır. Ve "Müşteriler" veya "Yükleniciler" varlık sınıfında, sırasıyla müşterinin veya yüklenicinin kodlarının her biri bir kez ve yalnızca bir kez ortaya çıkabilir, çünkü bu varlık sınıflarının her biri tüm müşterilerin ve icracıların tam bir listesinden başka bir şey değildir. Bu nedenle, bağlantının ana ucunda, çok sayıda "bir" vardır. Ve son olarak, üçüncü ilişkinin, yani "Graph" varlık sınıfının "Danışmanlar" varlık sınıfıyla ilişkisinin mutlaka tanımlayıcı olmaması gerekmediğine dikkat edin. Aslında, bu durumda, "Danışmanlar" varlık sınıfının "Danışman kodu" anahtar niteliğinin, aynı adı taşıyan "Grafik" varlık sınıfının anahtar olmayan niteliğine, yani birincil anahtarına aktarılmasından bahsediyoruz. "Grafik" varlık sınıfındaki "Danışmanlar" varlık sınıfı, zaten bu sınıfın birincil anahtarını tanımlamaz. Ayrıca, daha önce belirtildiği gibi, "Danışman Kodu" özelliği Null değerlere izin verir, bu nedenle burada kullanılan tam olarak tanımlayıcı olmayan ilişkidir. Böylece, "Danışman Kodu" özelliği, bir yabancı anahtarın durumunu alır ve başka bir şey değildir. Bu eksik tanımlayıcı olmayan bağlantının ebeveyn ve alt uçlarına yerleştirilen bağlantıların çokluğuna da dikkat edelim. Ebeveyn ucunun "birden fazla olmayan" bir çokluğu vardır. Gerçekten de, tamamen tanımlayıcı olmayan bir ilişkinin tanımını hatırlayacak olursak, "Graph" varlık sınıfındaki "Danışman kodu" özniteliğinin, tüm danışmanlar listesinden birden fazla danışman koduna karşılık gelemeyeceğini anlayacağız. ("Danışmanlar" varlık sınıfıdır). Ve genel olarak, herhangi bir danışman koduna karşılık gelmeyeceği ortaya çıkabilir (Boş değerlerin kabul edilebilirliği için onay kutusunu unutmayın: Danışman kodu: Boş), çünkü duruma göre, bir danışmanın varlığı genel olarak konuşursak, müşteri ve yüklenici arasındaki toplantı gerekli değildir. 4. Genellemeler Ele alacağımız varlık sınıfları arasındaki başka bir ilişki türü, formun bir ilişkisidir. genelleme. Aynı zamanda özyinelemeli olmayan bir ilişki türüdür. Yani böyle bir ilişki genelleme bir üst varlık sınıfının birkaç alt varlık sınıfıyla ilişkisi olarak uygulanır (birkaç üst varlık sınıfı ve bir alt varlık sınıfıyla ilgilenen önceki İlişkilendirme ilişkisinin aksine). Genelleme ilişkisini kullanarak veri temsili kurallarını formüle ederken, bir ana varlık sınıfı ve birkaç alt varlık sınıfı arasındaki bu ilişkinin, ilişkileri tam olarak tanımlayarak, yani kategorik ilişkilerle tanımlandığı hemen söylenmelidir. Tam olarak tanımlayıcı ilişkilerin tanımını hatırlayarak, Genelleştirme kullanılırken, ana varlık sınıfının birincil anahtarının her bir özniteliğinin, alt varlık sınıflarının birincil anahtarına, yani ana öğenin birincil geçiş anahtarının özniteliklerine aktarıldığı sonucuna varırız. varlık sınıfı, tüm alt varlık sınıflarının birincil anahtarlarını tamamen oluşturur, onları tanımlar. Genelleştirmenin sözde uyguladığını belirtmek ilginçtir. kategori hiyerarşisi veya miras hiyerarşisi. Bu durumda, ana varlık sınıfı şunları tanımlar: genel varlık sınıfı, tüm alt sınıfların varlıklarında ortak olan veya sözde kategorik varlıklar yani, bir ana varlık sınıfı, tüm alt varlık sınıflarının gerçek bir genellemesidir. İlişkisel bir veri modelinde genelleme uygulamasına bir örnek olarak aşağıdaki modeli oluşturacağız. Bu model genelleştirilmiş "Öğrenciler" kavramını temel alacak ve aşağıdaki kategorik kavramları tanımlayacaktır (yani, aşağıdaki alt varlık sınıflarını genelleştirecektir): "Okul Çocukları", "Öğrenciler" ve "Lisansüstü öğrenciler". Öyleyse, Genelleme türünün bir bağlantısıyla açıklanan, ana varlık sınıfı ile alt varlık sınıfları arasındaki ilişkinin özünü yansıtan bir anahtar diyagram oluşturalım.
Peki ne görüyoruz? İlk olarak, "Okul çocukları", "Öğrenciler" ve "Lisansüstü öğrenciler" temel ilişkilerinin her biri (veya aynı olan varlık sınıflarından) "Sınıf", "Ders" ve "Çalışma Yılı" gibi kendi özelliklerine karşılık gelir. ". Bu niteliklerin her biri, kendi varlık sınıfının üyelerini karakterize eder. Ayrıca, "Students" ana varlık sınıfının birincil anahtarının her bir alt varlık sınıfına taşındığını ve orada birincil yabancı anahtarı oluşturduğunu görüyoruz. Bu bağlantıların yardımıyla, herhangi bir öğrencinin koduyla adını, soyadını ve soyadını, ilgili alt varlık sınıflarının kendisinde bulamayacağımız bilgileri belirleyebiliriz. İkincisi, varlık sınıflarının tam olarak tanımlayıcı (veya kategorik) bir ilişkisinden bahsettiğimiz için, ana varlık sınıfı ile onun alt sınıfları arasındaki ilişkilerin çokluğuna dikkat edeceğiz. Bu bağlantıların her birinin üst ucunda "bir" çokluğu vardır ve bağlantıların her alt ucunda "en fazla bir" çokluğu vardır. Varlık sınıflarının tam olarak tanımlayıcı bir ilişkisinin tanımını hatırlayacak olursak, "Öğrenciler" varlık sınıfının birincil anahtarı olan gerçekten benzersiz öğrenci kodunun, her alt varlıkta böyle bir kodla en fazla bir özniteliği belirttiği anlaşılır. sınıf "Öğrenci", "Öğrenciler" ve Lisansüstü. Bu nedenle, tüm tahviller tam da bu tür çokluklara sahiptir. "Okul çocukları" ve "Öğrenciler" temel ilişkilerini oluşturmak için operatörlerin bir parçasını, kademeli türün referans bütünlüğünü korumak için kuralların tanımıyla yazalım. Böylece sahibiz: Tablo oluştur ... birincil anahtar (Öğrenci kodu) yabancı anahtar (Öğrenci Kimliği) başvuruları Öğrenciler (Öğrenci Kimliği) güncelleme kademesinde silme kademesinde Tablo oluştur Öğrenciler ... birincil anahtar (Öğrenci kodu) yabancı anahtar (Öğrenci Kimliği) başvuruları Öğrenciler (Öğrenci Kimliği) güncelleme kademesinde silme kademeli; Böylece, "Öğrenci" alt varlık sınıfında (veya ilişkisinde) "Öğrenciler" ana varlık sınıfına (veya ilişkisine) atıfta bulunan bir birincil yabancı anahtarın belirtildiğini görüyoruz. Referans bütünlüğünü korumaya yönelik kademeli kural, "Öğrenciler" ana varlık sınıfının nitelikleri silindiğinde veya güncellendiğinde, "Öğrenci" alt ilişkisinin karşılık gelen niteliklerinin otomatik olarak güncelleneceğini veya silineceğini belirler. Benzer şekilde, "Öğrenciler" ana varlık sınıfının öznitelikleri silindiğinde veya güncellendiğinde, "Öğrenciler" alt ilişkisinin karşılık gelen öznitelikleri de otomatik olarak güncellenecek veya silinecektir. Unutulmamalıdır ki, burada kullanılan referans bütünlüğü kuralıdır, çünkü bu bağlamda (öğrenci listesi) bilgilerin silinmesini ve güncellenmesini yasaklamak ve ayrıca gerçek bilgi yerine tanımsız bir değer atamak mantıklı değildir. . Şimdi bir önceki diyagramda anlatılan varlık sınıflarına bir örnek verelim, sadece tablo halinde sunulmuş. Yani, aşağıdaki ilişki tablolarına sahibiz: öğrenciler - diğer tüm ilişkilerin nitelikleri hakkındaki bilgileri birleştiren ebeveyn ilişkisi:
Öğrenciler - çocuk ilişkisi:
öğrenciler - ikinci çocuk ilişkisi:
doktora öğrencileri - üçüncü çocuk ilişkisi:
Gerçekten de, varlıkların alt sınıflarının öğrencilerin, yani okul çocukları, öğrenciler ve lisansüstü öğrencilerin soyadı, adı ve soyadı hakkında bilgi içermediğini görüyoruz. Bu bilgi, yalnızca ana varlık sınıfına yapılan referanslar yoluyla elde edilebilir. Ayrıca "Students" varlık sınıfındaki farklı öğrenci kodlarının farklı alt varlık sınıflarına karşılık gelebileceğini görüyoruz. Bu nedenle, "1" Nikolai Zabotin kodlu öğrenci hakkında, ebeveyn ilişkisinde adı dışında hiçbir şey bilinmemektedir ve diğer tüm bilgiler (kim olduğu, bir okul çocuğu, öğrenci veya yüksek lisans öğrencisi) yalnızca başvurarak bulunabilir. karşılık gelen alt varlık sınıfına (kod tarafından belirlenir). Benzer şekilde, "Öğrenciler" ana varlık sınıfında kodları belirtilen diğer öğrencilerle çalışmanız gerekir. 5. Bileşim Bileşim türünün varlık sınıflarının ilişkisi, önceki ikisi gibi, özyinelemeli ilişki türüne ait değildir. bileşim (veya bazen denildiği gibi, bileşik toplama), daha önce tartıştığımız ilişki gibi, tek bir ebeveyn varlık sınıfının birden çok alt varlık sınıfıyla ilişkisidir. genelleme. Ancak genelleme, tam olarak tanımlayıcı ilişkiler tarafından açıklanan varlık sınıflarının bir ilişkisi olarak tanımlandıysa, o zaman kompozisyon, sırayla, tam olarak tanımlanmayan ilişkilerle tanımlanır, yani kompozisyon sırasında, ana varlık sınıfının birincil anahtarının her bir niteliği, anahtar niteliğine geçer. alt varlık sınıfının. Ve aynı zamanda, geçiş yapan anahtar nitelikleri, alt varlık sınıfının birincil anahtarını yalnızca kısmen oluşturur. Bu nedenle, bileşik toplamayla (bileşimle birlikte), ana varlık sınıfı (veya birim) birden çok alt varlık sınıfıyla (veya bileşenler). Bu durumda, kümenin bileşenleri (yani, ana varlık sınıfının bileşenleri), birincil anahtarın parçası olan bir yabancı anahtar aracılığıyla kümeye atıfta bulunur ve bu nedenle, kümenin dışında var olamaz. Genel olarak, bileşik toplama, basit toplamanın gelişmiş bir biçimidir (bundan biraz sonra bahsedeceğiz). Bir bileşim (veya bileşik küme), şu gerçeğiyle karakterize edilir: 1) montaja yapılan atıf, bileşenlerin tanımlanmasında yer alır; 2) bu bileşenler toplamın dışında var olamaz. Zorunlu olarak tanımlayıcı olmayan ilişkilere sahip bir birleştirme (daha sonra ele alacağımız bir ilişki), bileşenlerin kümenin dışında var olmasına izin vermez ve bu nedenle, yukarıda açıklanan bileşik birleştirmenin uygulanmasına anlam olarak yakındır. Bir ana varlık sınıfı ile birkaç alt varlık sınıfı arasındaki ilişkiyi açıklayan, yani bileşik toplama türündeki varlık sınıflarının ilişkisini açıklayan bir anahtar diyagram oluşturalım. Bu, binalar, sınıflar ve asansörler dahil olmak üzere belirli bir kampüsün binalarının bileşimini gösteren bir anahtar diyagram olsun. Yani bu diyagram şöyle görünecek:
O halde az önce oluşturduğumuz şemaya bir göz atalım. İçinde ne görüyoruz? İlk olarak, bu bileşik kümelemede kullanılan ilişkinin gerçekten de özdeşleştirici olduğunu ve aslında tam olarak özdeşleşmediğini görüyoruz. Sonuçta, "Binalar" ana varlık sınıfının birincil anahtarı, "İzleyiciler" ve "Asansörler" alt varlık sınıflarının birincil anahtarının oluşumunda yer alır, ancak onu tam olarak tanımlamaz. Ana varlık sınıfının birincil anahtarı "Durum No", her iki alt sınıfın "Durum No" yabancı birincil anahtarlarına taşınır, ancak bu taşınan anahtara ek olarak, her iki alt varlık sınıfının da sırasıyla "Kitle" olmak üzere kendi birincil anahtarı vardır. Hayır" ve "Asansör No.", yani alt varlık sınıflarının bileşik birincil anahtarları, ana varlık sınıfının birincil anahtarının yalnızca kısmen oluşturulmuş öznitelikleridir. Şimdi ebeveyni ve her iki alt sınıfı birbirine bağlayan bağlantıların çokluğuna bakalım. Eksik tanımlayıcı bağlantılarla uğraştığımız için, çokluklar mevcuttur: "bir" ve "çok". "Bir" çokluğu, her iki ilişkinin de ebeveyn ucunda bulunur ve mevcut tüm corporalar listesinde (ve "Corpus" varlık sınıfı tam da böyle bir listedir), her sayının yalnızca bir kez (ve daha fazla değil) olabileceğini sembolize eder. bundan daha fazla) kez. Ve sırayla, "İzleyici" ve "Asansörler" sınıflarının nitelikleri arasında, binalardan daha fazla izleyici (veya asansör) olduğundan ve her binada birkaç oditoryum ve asansör olduğundan, her bina numarası birçok kez ortaya çıkabilir. Bu nedenle tüm derslik ve asansörleri listelerken kaçınılmaz olarak bina numaralarını tekrarlayacağız. Ve son olarak, önceki bağlantı türünde olduğu gibi, temel ilişkiler (veya aynı şey, varlık sınıfları) "İzleyiciler" ve "Asansörler" oluşturmak için operatörlerin parçalarını yazalım ve bunu, kademeli türün referans bütünlüğünü korumaya yönelik kuralların tanımıyla yapın. Yani bu ifade şöyle görünecektir: Tablo Kitleleri oluşturun ... birincil anahtar (korpus numarası, izleyici numarası) yabancı anahtar (durum numarası) referansları Modeller (durum numarası) güncelleme kademesinde silme kademesinde Masa Asansörleri oluşturun ... birincil anahtar (kasa numarası, asansör numarası) yabancı anahtar (durum numarası) referansları Modeller (durum numarası) güncelleme kademesinde silme kademeli; Böylece, alt varlık sınıflarının gerekli tüm birincil ve yabancı anahtarlarını ayarladık. Daha önce en rasyonel olarak tanımladığımız için, referans bütünlüğünü koruma kuralını kademeli olarak aldık. Şimdi az önce ele aldığımız tüm varlık sınıflarına tablo şeklinde bir örnek vereceğiz. Yansıttığımız bu temel ilişkileri bir diyagram yardımıyla tablolar şeklinde açıklayalım ve netlik için orada belirli miktarda gösterge verisi sunacağız. konut Ebeveyn ilişkisi şöyle görünür:
Kitleler - alt varlık sınıfı:
Asansörler - "Muhafazalar" üst sınıfının ikinci alt varlık sınıfı:
Böylece gerçek hayattaki herhangi bir eğitim kurumunun kullanabileceği bu veri tabanında tüm binalara, sınıflarına ve asansörlerine ait bilgilerin nasıl düzenlendiğini görebiliriz. 6. Toplama Toplama, kursumuzun bir parçası olarak kabul edilecek varlık sınıfları arasındaki son ilişki türüdür. Aynı zamanda özyinelemeli değildir ve iki türünden biri, daha önce düşünülen bileşik kümelemeye anlam olarak oldukça yakındır. Bu durumda, toplama bir üst varlık sınıfının birden çok alt varlık sınıfıyla ilişkisidir. Bu durumda, ilişki iki tür ilişki ile tanımlanabilir: 1) mutlaka tanımlayıcı olmayan bağlantılar; 2) isteğe bağlı tanımlayıcı olmayan bağlantılar. Zorunlu olarak tanımlayıcı olmayan ilişkilerle, ana varlık sınıfının birincil anahtarının bazı niteliklerinin, alt sınıfın anahtar olmayan bir niteliğine aktarıldığını ve geçiş anahtarının tüm nitelikleri için Null değerlerinin yasaklandığını hatırlayın. Ve mutlaka tanımlayıcı olmayan ilişkilerle, birincil anahtarların geçişi tamamen aynı ilkeye göre gerçekleşir, ancak geçiş anahtarının bazı özellikleri için Boş değerlere izin verilir. Toplarken, ana varlık sınıfı (veya birim) birden çok alt varlık sınıfıyla (veya bileşenler). Toplamın bileşenleri (yani, ana varlık sınıfı), birincil anahtarın parçası olmayan bir yabancı anahtar aracılığıyla toplamaya atıfta bulunur ve bu nedenle, bu durumda, mutlaka tanımlayıcı olmayan bağlantılar, toplama bileşenleri, toplama dışında var olabilir. Zorunlu olarak tanımlayıcı olmayan ilişkilerle kümeleme durumunda, kümenin bileşenlerinin kümenin dışında var olmasına izin verilmez ve bu anlamda, zorunlu olarak tanımlayıcı olmayan ilişkilerle kümeleme, bileşik kümelemeye yakındır. Toplama tipi ilişkinin ne olduğu netleştiğine göre, bu ilişkinin işleyişini açıklayan bir anahtar diyagram oluşturalım. Gelecekteki diyagramımız, otomobillerin işaretli bileşenlerini (yani motor ve şasi) tanımlasın. Aynı zamanda, aracın devre dışı bırakılmasının şasinin de devre dışı bırakılması anlamına geldiğini, ancak motorun aynı anda devre dışı bırakılması anlamına gelmediğini varsayacağız. Yani anahtar diyagramımız şuna benziyor:
Peki bu anahtar şemada ne görüyoruz? İlk olarak, "Arabalar" ana varlık sınıfının "Motorlar" alt varlık sınıfı ile ilişkisi mutlaka tanımlayıcı değildir, çünkü "araba #" özniteliği değerleri arasında boş değerlere izin verir. Buna karşılık, bu özellik, motorun devre dışı bırakılmasının koşula göre tüm aracın devre dışı bırakılmasına bağlı olmaması ve dolayısıyla bir arabanın devre dışı bırakılması sırasında mutlaka meydana gelmemesi nedeniyle Boş değerlere izin verir. Ayrıca, "Arabalar" varlık sınıfının "Motor #" birincil anahtarının, "Motorlar" varlık sınıfının anahtar olmayan "Motor #" özniteliğine geçtiğini görüyoruz. Ve aynı zamanda, bu özellik bir yabancı anahtarın statüsünü alır. Ve bu Engines varlık sınıfındaki birincil anahtar, üst ilişkinin herhangi bir özniteliğine başvurmayan Engine Marker özniteliğidir. İkinci olarak, "Motorlar" ana varlık sınıfı ile "Şasi" alt varlık sınıfı arasındaki ilişki, zorunlu olarak tanımlayıcı olmayan bir ilişkidir, çünkü "Araba #" yabancı anahtar özelliği, değerleri arasında Boş değerlere izin vermez. Bu da, aracın devre dışı bırakılmasının, şasinin zorunlu olarak aynı anda devreden çıkarılması anlamına geldiği koşuluyla bilindiği için gerçekleşir. Burada, önceki ilişkide olduğu gibi, "Motorlar" ana varlık sınıfının birincil anahtarı, "Şasi" alt varlık sınıfının anahtar olmayan "Araba numarası" özniteliğine taşınır. Aynı zamanda, bu varlık sınıfının birincil anahtarı, "Motorlar" üst ilişkisinin herhangi bir özniteliğine atıfta bulunmayan "Şasi İşaretçisi" özniteliğidir. Devam et. Konunun en iyi özümlenmesi için, referans bütünlüğünü koruma kurallarının tanımıyla "Motorlar" ve "Şasi" temel ilişkilerini oluşturmak için operatörlerin parçalarını tekrar yazalım. Tablo Motorları oluştur ... birincil anahtar (Motor işaretleyici) yabancı anahtar (araç no.) referansları Arabalar (araç no.) güncelleme kademesinde silme set Null Tablo Şasi oluştur ... birincil anahtar (şasi işaretçisi) yabancı anahtar (araç no.) referansları Arabalar (araç no.) güncelleme kademesinde silme kademeli; Her yerde referans bütünlüğünü korumak için aynı kuralı kullandığımızı görüyoruz - daha önce bile en rasyonel olarak kabul ettiğimiz için kademeli. Ancak bu sefer (kaskad kuralına ek olarak) set Null referans bütünlüğü kuralını kullandık. Ayrıca, bunu şu koşul altında kullandık: "Arabalar" ana varlık sınıfından "Araba numarası" birincil anahtarının bir değeri silinirse, "Motorlar" alt ilişkisinin yabancı anahtarının "Araba numarası" değeri buna atıfta bulunarak bir Null-değeri atanacaktır. 7. Niteliklerin birleştirilmesi Belirli bir ebeveyn varlık sınıfının birincil anahtarlarının geçişi sırasında, anlam bakımından çakışan farklı üst sınıflardan gelen nitelikler aynı alt sınıfa girerse, bu nitelikler "birleştirilmelidir", yani bu işlemin gerçekleştirilmesi gerekir. -aranan niteliklerin birleştirilmesi. Örneğin, bir çalışanın bir kuruluşta çalışabilmesi durumunda, birden fazla departmanda listelenmemesi durumunda, "Kuruluş Kodu" özniteliğini birleştirdikten sonra aşağıdaki anahtar diyagramı alırız:
Birincil anahtarı "Organizasyon" ve "Departmanlar" üst varlık sınıflarından "Çalışanlar" alt sınıfına geçirirken, "Kuruluş Kimliği" niteliği "Çalışanlar" varlık sınıfına girer. Ve iki kez: 1) işaretleyici ile ilk kez PFEksik tanımlayıcı bir ilişki kurarken "Kuruluş" varlık sınıfından K; 2) ve ikinci kez, zorunlu olarak tanımlayıcı olmayan bir ilişki kurarken "Bölümler" varlık sınıfından Boş değerleri kabul etme koşuluyla FK işaretçisi ile. Birleştirildiğinde, "Kuruluş Kimliği" özniteliği, yabancı anahtar özniteliğinin durumunu emerek birincil/yabancı anahtar özniteliği durumunu alır. Birleştirme sürecinin kendisini gösteren yeni bir anahtar diyagram oluşturalım:
Böylece niteliklerin birleşmesi gerçekleşti. Ders No. 13. Uzman sistemler ve bilgi üretim modeli 1. Uzman sistemlerin atanması Bizim için böyle yeni bir konseptle tanışmak için uzman sistemler yeni başlayanlar için, "uzman sistemler" yönünün yaratılması ve geliştirilmesinin tarihini gözden geçireceğiz ve sonra uzman sistem kavramını tanımlayacağız. 80'lerin başında. XNUMX. yüzyıl yapay zekanın yaratılmasıyla ilgili araştırmalarda, adı verilen yeni bir bağımsız yön oluşturuldu. uzman sistemler. Uzman sistemler üzerine yapılan bu yeni araştırmanın amacı, belirli problem türlerini çözmek için tasarlanmış özel programlar geliştirmektir. Yepyeni bir bilgi mühendisliğinin yaratılmasını gerektiren bu özel problem türü nedir? Bu özel görev türü, kesinlikle herhangi bir konu alanındaki görevleri içerebilir. Onları sıradan problemlerden ayıran en önemli şey, bunları çözmenin bir insan uzmanı için çok zor bir iş gibi görünmesidir. Sonra ilk sözde uzman sistem (uzman rolünün artık bir kişi değil, bir makine olduğu yerde) ve uzman sistem, sıradan bir kişi - bir uzman tarafından elde edilen çözümlere göre kalite ve verimlilik açısından daha düşük olmayan sonuçlar alır. Uzman sistemlerin çalışmalarının sonuçları kullanıcıya çok üst düzeyde anlatılabilir. Uzman sistemlerin bu kalitesi, kendi bilgi ve sonuçları hakkında akıl yürütme yetenekleriyle sağlanır. Uzman sistemler, bir uzmanla etkileşim sürecinde kendi bilgilerini yenileyebilir. Böylece, tam olarak oluşturulmuş bir yapay zeka ile tam bir güvenle aynı seviyeye getirilebilirler. Uzman sistemler alanındaki araştırmacılar, kendi disiplinlerinin adı için genellikle daha önce bahsedilen "bilgi mühendisliği" terimini kullanırlar ve Alman bilim adamı E. Feigenbaum tarafından "yapay zeka alanındaki araştırma ilkelerini ve araçlarını çözmeye getirmek" olarak tanıtıldı. uzman bilgisi gerektiren zor uygulamalı problemler." Ancak, geliştirme firmalarına ticari başarı hemen gelmedi. 1960'dan 1985'e çeyrek asırdır. Yapay zekanın başarıları esas olarak araştırma geliştirmeleriyle ilgilidir. Ancak, 1985'ten başlayarak ve 1987'den 1990'a kadar büyük bir ölçekte. uzman sistemler ticari uygulamalarda aktif olarak kullanılmaktadır. Uzman sistemlerin faydaları oldukça büyüktür ve aşağıdaki gibidir: 1) uzman sistem teknolojisi, çözümü önemli ekonomik faydalar sağlayan ve ilgili tüm süreçleri büyük ölçüde basitleştiren kişisel bilgisayarlarda çözülen pratik olarak önemli görevlerin yelpazesini önemli ölçüde genişletir; 2) uzman sistem teknolojisi, süre, kalite ve sonuç olarak karmaşık uygulamaların geliştirilmesinin yüksek maliyeti gibi geleneksel programlamanın küresel sorunlarını çözmede en önemli araçlardan biridir ve bunun sonucunda ekonomik etki önemli ölçüde azaltılmıştır. ; 3) genellikle geliştirme maliyetini birkaç kat aşan karmaşık sistemlerin yüksek bir işletme ve bakım maliyetinin yanı sıra programların düşük düzeyde yeniden kullanılabilirliği vb. 4) uzman sistem teknolojisinin geleneksel programlama teknolojisiyle birleşimi, ilk olarak, uygulamaların bir programcı tarafından değil, sıradan bir kullanıcı tarafından dinamik olarak değiştirilmesini sağlayarak yazılım ürünlerine yeni nitelikler ekler; ikincisi, uygulamanın daha fazla "şeffaflığı", daha iyi grafikler, arayüz ve uzman sistemlerin etkileşimi. Sıradan kullanıcılara ve önde gelen uzmanlara göre, yakın gelecekte uzman sistemler aşağıdaki uygulamaları bulacaktır: 1) uzman sistemler tasarım, geliştirme, üretim, dağıtım, hata ayıklama, kontrol ve hizmet sunumunun tüm aşamalarında öncü bir rol oynayacaktır; 2) Geniş ticari dağıtım alan uzman sistem teknolojisi, hazır akıllı etkileşimli modüllerden uygulamaların entegrasyonunda devrim niteliğinde bir atılım sağlayacaktır. Genel olarak, uzman sistemler sözde resmi olmayan görevleryani, uzman sistemler, resmileştirilmiş sorunları çözmeye odaklanan program geliştirmeye yönelik geleneksel yaklaşımı reddetmez ve yerine geçmez, ancak onları tamamlar, böylece olasılıkları önemli ölçüde genişletir. Bu tam olarak bir insan uzmanının yapamayacağı şeydir. Bu tür karmaşık resmi olmayan görevler aşağıdakilerle karakterize edilir: 1) kaynak verilerin yanlışlığı, yanlışlığı, belirsizliği ve ayrıca eksikliği ve tutarsızlığı; 2) problem alanı ve çözülmekte olan problem hakkında yanlışlık, belirsizlik, yanlışlık, eksiklik ve bilgi tutarsızlığı; 3) belirli bir sorunun çözüm alanının büyük boyutu; 4) bu tür gayri resmi bir sorunu çözme sürecinde doğrudan veri ve bilginin dinamik değişkenliği. Uzman sistemler, bilinen bir algoritmanın yürütülmesine değil, temel olarak bir çözüm için buluşsal aramaya dayanır. Bu, uzman sistem teknolojisinin geleneksel yazılım geliştirme yaklaşımına göre ana avantajlarından biridir. Bu, kendilerine verilen görevlerle çok iyi başa çıkmalarını sağlayan şeydir. Uzman sistem teknolojisi, çeşitli sorunları çözmek için kullanılır. Bu görevlerin başlıcalarını listeliyoruz. 1. Yorumlama. Yorumu gerçekleştiren uzman sistemler, çoğu zaman, işlerin durumunu tanımlamak için çeşitli araçların okumalarını kullanır. Yorumlayıcı uzman sistemler, çeşitli bilgi türlerini işleyebilir. Bir örnek, bileşimlerini ve özelliklerini belirlemek için spektral analiz verilerinin ve maddelerin özelliklerindeki değişikliklerin kullanılmasıdır. Ayrıca bir örnek, kazanların ve içindeki suyun durumunu tanımlamak için kazan dairesindeki ölçüm cihazlarının okumalarının yorumlanmasıdır. Yorumlayıcı sistemler çoğunlukla doğrudan göstergelerle ilgilenir. Bu bağlamda, diğer sistem türlerinin sahip olmadığı zorluklar ortaya çıkmaktadır. Bu zorluklar nelerdir? Bu zorluklar, uzman sistemlerin tıkanmış gereksiz, eksik, güvenilmez veya yanlış bilgileri yorumlamak zorunda kalmasından kaynaklanmaktadır. Bu nedenle, ya hatalar ya da veri işlemede önemli bir artış kaçınılmazdır. 2. Tahmin. Bir şeyin tahminini gerçekleştiren uzman sistemler, verilen durumların olasılık koşullarını belirler. Örnekler, olumsuz hava koşullarının tahıl hasadına neden olduğu hasarın tahmini, dünya pazarındaki gaz talebinin değerlendirilmesi, meteoroloji istasyonlarına göre hava tahminidir. Tahmin sistemleri bazen modellemeyi kullanır, yani onları bir programlama ortamında yeniden oluşturmak için gerçek dünyada bazı ilişkileri gösteren programlar ve ardından belirli ilk verilerle ortaya çıkabilecek durumları tasarlar. 3. Çeşitli cihazların teşhisi. Uzman sistemler, arızalı bir teşhis edilebilir sistemin olası nedenlerini belirlemek için herhangi bir durum, davranış veya çeşitli bileşenlerin yapısına ilişkin verileri kullanarak bu tür teşhisleri gerçekleştirir. Örnekler, hastalarda (tıpta) gözlenen semptomlarla hastalığın koşullarının oluşturulmasıdır; elektronik devrelerdeki arızaların tespiti ve çeşitli cihazların mekanizmalarındaki arızalı bileşenlerin tespiti. Teşhis sistemleri genellikle yalnızca teşhis koymakla kalmayıp aynı zamanda sorun gidermede de yardımcı olan yardımcılardır. Bu gibi durumlarda, bu sistemler sorun gidermeye yardımcı olmak için kullanıcıyla etkileşime girebilir ve ardından bunları çözmek için gereken eylemlerin bir listesini sağlayabilir. Şu anda, mühendislik ve bilgisayar sistemlerine uygulama olarak birçok teşhis sistemi geliştirilmektedir. 4. Çeşitli etkinlikler planlamak. Çeşitli operasyonları planlamak için tasarlanmış uzman sistemler. Sistemler, uygulanmaları başlamadan önce neredeyse eksiksiz bir eylem dizisini önceden belirler. Bu tür olay planlamasına örnek olarak, düşman kuvvetlerine karşı avantaj elde etmek için belirli bir süre için önceden belirlenmiş hem savunma hem de saldırı askeri operasyonlar için planların oluşturulması verilebilir. 5. Dizayn. Tasarım gerçekleştiren uzman sistemler, mevcut koşulları ve ilgili tüm faktörleri dikkate alarak çeşitli nesne formları geliştirir. Bir örnek genetik mühendisliğidir. 6. Kontrol. Kontrol uygulayan uzman sistemler, sistemin mevcut davranışını beklenen davranışıyla karşılaştırır. Uzman sistemlerin gözlemlenmesi, normal davranışa karşı beklentilerini veya potansiyel sapma varsayımlarını doğrulayan kontrollü davranışı tespit eder. Kontrol eden uzman sistemler, doğası gereği, gerçek zamanlı olarak çalışmalı ve kontrol edilen nesnenin davranışının zamana bağlı ve bağlama bağlı bir yorumunu uygulamalıdır. Örnekler, acil durumları tespit etmek için nükleer reaktörlerdeki ölçüm cihazlarının okumalarının izlenmesini veya yoğun bakım ünitesindeki hastalardan alınan teşhis verilerinin değerlendirilmesini içerir. 7. Управление. Sonuçta, kontrolü uygulayan uzman sistemlerin, bir bütün olarak sistemin davranışını çok etkili bir şekilde yönettiği yaygın olarak bilinmektedir. Bir örnek, çeşitli endüstrilerin yönetimi ve bilgisayar sistemlerinin dağıtımıdır. Kontrol uzman sistemleri, bir nesnenin davranışını uzun bir süre boyunca kontrol etmek için gözlemci bileşenleri içermelidir, ancak halihazırda analiz edilmiş görev türlerinden başka bileşenlere de ihtiyaç duyabilirler. Uzman sistemler çeşitli alanlarda kullanılmaktadır: finansal işlemler, petrol ve gaz endüstrisi. Uzman sistem teknolojisi enerji, ulaşım, ilaç endüstrisi, uzay geliştirme, metalurji ve madencilik endüstrileri, kimya ve diğer birçok alanda da uygulanabilir. 2. Uzman sistemlerin yapısı Uzman sistemlerin geliştirilmesinin, geleneksel bir yazılım ürününün geliştirilmesinden bir takım önemli farklılıkları vardır. Uzman sistemler oluşturma deneyimi, geliştirmelerinde geleneksel programlamada benimsenen metodolojinin kullanılmasının, uzman sistemlerin oluşturulması için harcanan süreyi büyük ölçüde artırdığını veya hatta olumsuz sonuçlara yol açtığını göstermiştir. Uzman sistemler genellikle ikiye ayrılır: statik и dinamik. İlk olarak, statik bir uzman sistemi düşünün. standart statik uzman sistem aşağıdaki ana bileşenlerden oluşur: 1) veri tabanı olarak da adlandırılan çalışma belleği; 2) bilgi temelleri; 3) yorumlayıcı olarak da adlandırılan bir çözücü; 4) bilgi edinmenin bileşenleri; 5) açıklayıcı bileşen; 6) diyalog bileşeni. Şimdi her bileşeni daha ayrıntılı olarak ele alalım. çalışan bellek (çalışma ile mutlak benzetme ile, yani bilgisayar RAM'i), o anda çözülmekte olan görevin ilk ve ara verilerini almak ve depolamak için tasarlanmıştır. База знаний belirli bir konu alanını açıklayan uzun vadeli verileri depolamak için tasarlanmıştır ve çözülmekte olan problemin bu alanındaki verilerin rasyonel dönüşümünü tanımlayan kurallar. çözücüolarak da adlandırılır tercüman, şu şekilde çalışır: çalışma belleğindeki ilk verileri ve bilgi tabanındaki uzun vadeli verileri kullanarak, ilk verilere uygulanması sorunun çözümüne yol açan kuralları oluşturur. Tek kelimeyle, önüne konan sorunu gerçekten "çözüyor"; Bilgi Edinme Bileşeni uzman sistemi uzman bilgisi ile doldurma sürecini otomatikleştirir, yani bilgi tabanına bu belirli konu alanından gerekli tüm bilgileri sağlayan bu bileşendir. Bileşeni açıkla sistemin bu soruna nasıl bir çözüm bulduğunu veya bu çözümü neden almadığını ve bunu yaparken hangi bilgileri kullandığını açıklar. Başka bir deyişle, açıklama bileşeni bir ilerleme raporu oluşturur. Bu bileşen, sistemin bir uzman tarafından test edilmesini büyük ölçüde kolaylaştırdığı ve ayrıca kullanıcının elde edilen sonuca olan güvenini arttırdığı ve dolayısıyla geliştirme sürecini hızlandırdığı için tüm uzman sistem için çok önemlidir. İletişim Bileşeni hem problem çözme sürecinde hem de bilgi edinme ve çalışma sonuçlarını bildirme sürecinde kullanıcı dostu bir arayüz sağlamaya hizmet eder. Artık istatistiksel bir uzman sistemin genel olarak hangi bileşenlerden oluştuğunu bildiğimize göre, böyle bir uzman sistemin yapısını yansıtan bir diyagram oluşturalım. Şuna benziyor:
Statik uzman sistemler çoğunlukla, bir problemin çözümü sırasında meydana gelen çevre değişikliklerini hesaba katmamanın mümkün olmadığı teknik uygulamalarda kullanılır. Pratik uygulama alan ilk uzman sistemlerin tam olarak statik olduğunu bilmek ilginçtir. Bu nedenle, şimdilik istatistiksel uzman sistem incelemesini bitireceğiz, dinamik uzman sistemin analizine geçelim. Ne yazık ki, kursumuzun programı bu uzman sistemin ayrıntılı bir değerlendirmesini içermemektedir, bu nedenle kendimizi dinamik bir uzman sistem ile statik bir sistem arasındaki yalnızca en temel farklılıkları analiz etmekle sınırlayacağız. Statik bir uzman sistemin aksine, yapı dinamik uzman sistem Ek olarak, aşağıdaki iki bileşen tanıtılmıştır: 1) dış dünyayı modellemek için bir alt sistem; 2) dış çevre ile ilişkilerin bir alt sistemi. Dış çevre ile ilişkilerin alt sistemi Sadece dış dünya ile bağlantı kurar. Bunu özel sensörler ve kontrolörler sistemi aracılığıyla yapıyor. Ek olarak, statik bir uzman sistemin bazı geleneksel bileşenleri, o anda çevrede meydana gelen olayların zamansal mantığını yansıtmak için önemli değişikliklere uğrar. Statik ve dinamik uzman sistemler arasındaki temel fark budur. Dinamik bir uzman sistemin bir örneği, farmasötik endüstrisinde çeşitli ilaçların üretiminin yönetimidir. 3. Uzman sistemlerin geliştirilmesine katılanlar Uzman sistemlerin geliştirilmesinde çeşitli uzmanlıkların temsilcileri yer almaktadır. Çoğu zaman, belirli bir uzman sistem üç uzman tarafından geliştirilir. Bu genellikle: 1) uzman; 2) bilgi mühendisi; 3) araçların geliştirilmesi için bir programcı. Burada listelenen uzmanların her birinin sorumluluklarını açıklayalım. Uzman Geliştirilmekte olan bu özel uzman sistem yardımıyla görevleri çözülecek olan konu alanında uzmandır. Bilgi Mühendisi doğrudan bir uzman sistemin geliştirilmesinde uzmandır. Onun kullandığı teknolojiler ve yöntemlere bilgi mühendisliği teknolojileri ve yöntemleri denir. Bir bilgi mühendisi, bir uzmanın, konu alanındaki tüm bilgilerden, geliştirilmekte olan belirli bir uzman sistemle çalışmak için gerekli olan bilgileri belirlemesine ve ardından onu yapılandırmasına yardımcı olur. Geliştirmeye katılanlar arasında bilgi mühendislerinin bulunmaması, yani programcılar tarafından değiştirilmelerinin, tüm projenin belirli bir uzman sistem oluşturma başarısızlığına yol açması veya geliştirme süresini önemli ölçüde artırması ilginçtir. Ve nihayet, programcı uzman sistemlerin gelişimini hızlandırmak için tasarlanmış araçlar (araçlar yeni geliştirilmişse) geliştirir. Bu araçlar, limit dahilinde, bir uzman sistemin tüm ana bileşenlerini içerir; programcı ayrıca araçlarını kullanılacağı ortamla arayüzler. 4. Uzman sistemlerin çalışma modları Uzman sistem iki ana modda çalışır: 1) bilgi edinme modunda; 2) sorunu çözme modunda (istişare modu veya uzman sistemi kullanma modu olarak da adlandırılır). Bu mantıklı ve anlaşılırdır, çünkü ilk önce uzman sistemi çalışmak zorunda olduğu konu alanından gelen bilgilerle yüklemek gerekir, bu uzman sistemin "eğitim" modudur, olduğu moddur. ilim alır. Ve iş için gerekli tüm bilgileri yükledikten sonra işin kendisi takip eder. Uzman sistem çalışmaya hazır hale gelir ve artık danışmalar veya herhangi bir sorunun çözümü için kullanılabilir. Daha ayrıntılı olarak düşünelim bilgi edinme modu. Bilgi edinme modunda, uzman sistem ile çalışma, bir uzman tarafından bir bilgi mühendisi aracılığıyla gerçekleştirilir. Bu modda uzman, bilgi edinme bileşenini kullanarak sistemi bilgi (veri) ile doldurur ve bu da sistemin bu konu alanındaki sorunları bir uzmanın katılımı olmadan çözüm modunda çözmesine izin verir. Program geliştirmeye yönelik geleneksel yaklaşımdaki bilgi edinme modunun, doğrudan programcı tarafından gerçekleştirilen algoritmalaştırma, programlama ve hata ayıklama aşamalarına karşılık geldiği belirtilmelidir. Geleneksel yaklaşımın aksine, uzman sistemler söz konusu olduğunda, programların geliştirilmesi bir programcı tarafından değil, bir uzman tarafından, elbette, uzman sistemlerin yardımıyla, yani genel olarak gerçekleştirilir. , programlama bilmeyen bir kişi. Şimdi de uzman sistemin ikinci işleyiş biçimini ele alalım, yani. problem çözme modu. Problem çözme modunda (veya sözde danışma modunda), uzman sistemlerle iletişim, doğrudan çalışmanın nihai sonucuyla ve bazen de onu elde etme yöntemiyle ilgilenen son kullanıcı tarafından gerçekleştirilir. Unutulmamalıdır ki, uzman sistemin amacına bağlı olarak kullanıcının bu sorun alanında uzman olması gerekmemektedir. Bu durumda sonuç elde etmek için yeterli bilgiye sahip olmadığı için sonuç için uzman sistemlere yönelir. Veya kullanıcı kendi başına istenen sonuca ulaşmak için yeterli bilgi düzeyine sahip olabilir. Bu durumda kullanıcı sonucu kendisi almakta, ancak sonuca ulaşma sürecini hızlandırmak veya uzman sistemlere monoton bir iş atamak için uzman sistemlere yönelmektedir. Danışma modunda, diyalog bileşeni tarafından işlendikten sonra kullanıcının göreviyle ilgili veriler çalışma belleğine girer. Çözücü, çalışan bellekten gelen girdi verilerine, problem alanı hakkındaki genel verilere ve veri tabanından gelen kurallara dayanarak probleme bir çözüm üretir. Bir problemi çözerken, uzman sistemler sadece belirli bir işlemin öngörülen sırasını yürütmekle kalmaz, aynı zamanda onu önceden oluşturur. Bu, sistemin tepkisinin kullanıcı için tamamen net olmadığı durumlarda yapılır. Bu durumda kullanıcı, bu uzman sistemin neden belirli bir soru sorduğunu veya bu uzman sistemin bu işlemi neden gerçekleştiremediğini, bu uzman sistem tarafından sağlanan şu veya bu sonucun nasıl elde edildiğini açıklamasını isteyebilir. 5. Bilginin üretim modeli Özünde, bilgi üretim modelleri Mantıksal veri çıkarımı için çok etkili prosedürler düzenlemenize izin veren mantıksal modellere yakın. Bu bir yandan. Ancak öte yandan, bilginin üretim modellerini mantıksal modellerle karşılaştırmalı olarak ele alırsak, o zaman birincisi bilgiyi daha açık bir şekilde gösterir ki bu tartışılmaz bir avantajdır. Bu nedenle, kuşkusuz, bilginin üretim modeli, yapay zeka sistemlerinde bilgiyi temsil etmenin temel araçlarından biridir. Öyleyse, bilgi üretim modeli kavramının ayrıntılı bir değerlendirmesine başlayalım. Geleneksel bilgi üretim modeli aşağıdaki temel bileşenleri içerir: 1) üretim sisteminin bilgi tabanını temsil eden bir dizi kural (veya üretim); 2) orijinal olguların yanı sıra çıkarım mekanizmasını kullanarak orijinal olgulardan türetilen olguları saklayan işleyen bellek; 3) mevcut gerçeklerden mevcut çıkarım kurallarına göre yeni gerçekler türetmesine izin veren mantıksal çıkarım mekanizmasının kendisi. Ve ilginç bir şekilde, bu tür işlemlerin sayısı sonsuz olabilir. Üretim sisteminin bilgi tabanını temsil eden her kural, bir koşullu ve bir de son kısım içerir. Kuralın koşullu kısmı ya tek bir olgu ya da bir bağlaçla birbirine bağlanan birkaç olgu içerir. Kuralın son kısmı, kuralın koşullu kısmı doğruysa, işleyen bellekle doldurulması gereken gerçekleri içerir. Bilginin üretim modelini şematik olarak göstermeye çalışırsak, üretim aşağıdaki formun bir ifadesi olarak anlaşılır: (i) Q; P; A→B; N; Burada, bu üretimin tüm üretim modellerinden ayırt edilmesini sağlayan ve bir tür tanımlama alan bilgi üretim modelinin adı veya seri numarası. Bu ürünün özünü yansıtan bazı sözlük birimleri isim işlevi görebilir. Aslında, listeden istenen ürünü aramayı basitleştirmek için ürünleri bilinçli olarak daha iyi algılamak için adlandırıyoruz. Basit bir örnek alalım: bir defter satın almak" veya "bir dizi renkli kalem. Açıkçası, her ürün genellikle o ana uygun kelimelerle anılır. Başka bir deyişle, bir kürek kürek çağırın. Devam et. Q öğesi, bu özel bilgi üretim modelinin kapsamını karakterize eder. Bu tür alanlar insan zihninde kolayca ayırt edilir, bu nedenle kural olarak bu öğenin tanımında herhangi bir zorluk yoktur. Bir örnek alalım. Şu durumu ele alalım: diyelim ki bilincimizin bir alanında yemek pişirme bilgisi depolanır, diğerinde işe nasıl gidilir, üçüncüsünde çamaşır makinesinin nasıl düzgün çalıştırılacağı. Bilginin üretim modelinin belleğinde de benzer bir bölünme mevcuttur. Bilginin ayrı alanlara bu şekilde bölünmesi, şu anda ihtiyaç duyulan bazı spesifik bilgi üretim modellerini aramak için harcanan zamandan önemli ölçüde tasarruf sağlayabilir ve böylece onlarla çalışma sürecini büyük ölçüde basitleştirir. Tabii ki, üretimin ana unsuru, yukarıdaki formülümüzde A → B olarak gösterilen çekirdeğidir. Bu formül, "A koşulu karşılanırsa, B eylemi yapılmalıdır" şeklinde yorumlanabilir. Daha karmaşık çekirdek yapıları ile uğraşıyorsak, sağ tarafta aşağıdaki alternatif seçime izin verilir: "A koşulu sağlanırsa, B eylemi gerçekleştirilmelidir.1, aksi takdirde B eylemini gerçekleştirmelisiniz2". Bununla birlikte, bilginin üretim modelinin özünün yorumu farklı olabilir ve sıralı "→" işaretinin solunda ve sağında ne olacağına bağlı olabilir. Bilgi üretim modelinin özünün yorumlarından biri ile, ardışık olağan mantıksal anlamda, yani. gerçek A koşulundan B eyleminin mantıksal sonucunun bir işareti olarak yorumlanabilir. Bununla birlikte, bilgi üretim modelinin özünün başka yorumları da mümkündür. Bu nedenle, örneğin A, bir B eyleminin gerçekleştirilmesi için yerine getirilmesi gerekli olan bir koşulu tanımlayabilir. Daha sonra, R bilgisinin üretim modelinin bir unsurunu ele alıyoruz. eleman Р ürün çekirdeğinin uygulanabilirliği için bir koşul olarak tanımlanır. P koşulu doğruysa, üretim çekirdeği etkinleştirilir. Aksi takdirde, P koşulu sağlanmazsa, yani yanlış ise, çekirdek etkinleştirilemez. Açıklayıcı bir örnek olarak, aşağıdaki bilgi üretim modelini göz önünde bulundurun: "Paranın mevcudiyeti"; "Eğer A şeyini almak istiyorsan, bedelini kasiyere ödemeli ve çeki satıcıya ibraz etmelisin." Bakıyoruz, P koşulu doğruysa, yani satın alma ödendi ve çek sunuldu, sonra çekirdek etkinleştirildi. Satın alma tamamlandı. Bu bilgi üretim modelinde, çekirdeğin uygulanabilirlik koşulu yanlışsa, yani para yoksa, bilgi üretim modelinin çekirdeğini uygulamak imkansızdır ve etkinleştirilmez. Ve sonunda elemente git N. N öğesi, üretim verisi modelinin son koşulu olarak adlandırılır. Son koşul, üretim çekirdeğinin uygulanmasından sonra gerçekleştirilmesi gereken eylemleri ve prosedürleri tanımlar. Daha iyi bir algı için basit bir örnek verelim: Bir mağazadan bir şey satın aldıktan sonra, bu mağazanın mallarının envanterinde bu tür şeylerin sayısını birer birer azaltmak gerekir, yani satın alma yapıldıysa (dolayısıyla , çekirdek satılır), o zaman mağazada bu üründen bir birim daha az bulunur. Bu nedenle, "Satın alınan öğenin biriminin üzerini çizin" son koşulu. Özetle, bilginin bir kurallar dizisi olarak, yani bir bilgi üretim modelinin kullanılması yoluyla temsilinin aşağıdaki avantajlara sahip olduğunu söyleyebiliriz: 1) bireysel kuralları oluşturma ve anlama kolaylığıdır; 2) mantıksal seçim mekanizmasının basitliğidir. Bununla birlikte, bilginin bir dizi kural biçiminde temsilinde, üretim bilgisi modellerinin uygulama kapsamını ve sıklığını hala sınırlayan dezavantajlar da vardır. Bu tür ana dezavantaj, belirli bir bilgi üretim modelini oluşturan kurallar ile mantıksal seçim kuralları arasındaki karşılıklı ilişkilerin belirsizliğidir. Notlar 1. Kitabın basılı baskısındaki altı çizili yazı tipi, Kalın italik kitabın bu (elektronik) versiyonunda. (Yaklaşık e. ed.)
▪ Pedagoji ve Eğitim Tarihi. Beşik
Bahçelerdeki çiçekleri inceltmek için makine
02.05.2024 Gelişmiş Kızılötesi Mikroskop
02.05.2024 Böcekler için hava tuzağı
01.05.2024
▪ Hibrit mobil bilgisayarlar için Intel Core M işlemciler ▪ TPL5110 - Nano Güç Yönetimi Zamanlayıcısı ▪ Okul otobüsleri için Omnicomm izleme sistemi ▪ Angry Birds 67,6 milyon dolar gelir getirdi
▪ Sitenin teknoloji tarihi, teknoloji, etrafımızdaki nesneler bölümü. Makale seçimi ▪ Feldwebel'in Voltaire'deki makalesini vermek için. Popüler ifade ▪ makale Bir gaz sızıntısını tespit etmek için kuşlar nasıl kullanılır? ayrıntılı cevap ▪ Bir uçta Sekizinci Madde. Seyahat ipuçları ▪ makale Basit mantık araştırması. Radyo elektroniği ve elektrik mühendisliği ansiklopedisi ▪ makale Zor pimler. Odak Sırrı
Ana sayfa | Kütüphane | Makaleler | Site haritası | Site incelemeleri
www.diagram.com.ua |



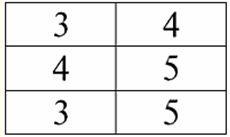

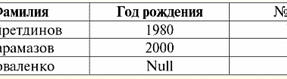

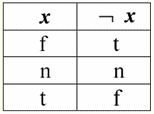

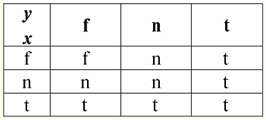
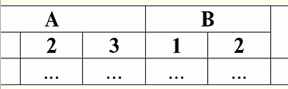


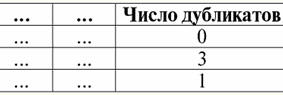
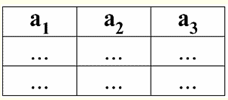






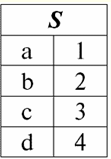


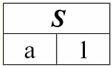
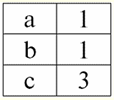

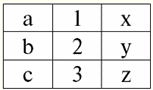









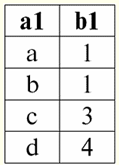






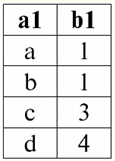



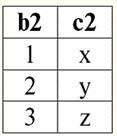

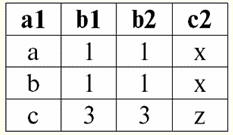







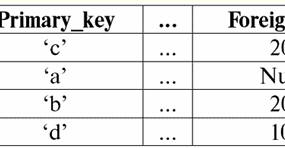








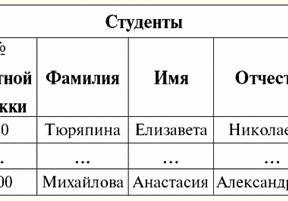
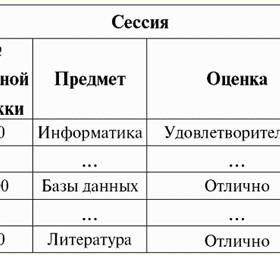




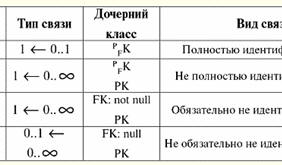














 Diğer makalelere bakın bölüm
Diğer makalelere bakın bölüm 